这是 DBRECOVER for Oracle 的官方用户手册。可使用左侧目录跳转至特定恢复场景;如需全面了解,请从头到尾顺序阅读。
概述
DBRECOVER for Oracle 是一款企业级 Oracle 数据灾难恢复软件。它可以直接从 Oracle 8i 至 21c 数据库的数据文件中提取并恢复数据,无需通过运行中的 Oracle 数据库实例进行 SQL 查询。DBRECOVER 基于 Java 构建,无需额外安装,下载并解压后即可直接使用。
DBRECOVER 提供直观的 GUI 图形界面,操作简便。用户无需学习独立的命令集,也无需了解 Oracle 内部存储结构;Recovery Wizard(恢复向导)会引导整个恢复流程。
为什么选择 DBRECOVER?
一个常见的问题是:传统的 Oracle Recovery Manager (RMAN) 备份恢复是否已经足够,为什么还需要 DBRECOVER?答案来自实际的恢复场景。
随着企业 IT 系统的快速发展,数据量正在以几何级数增长。Oracle DBA 经常面临这样的问题:现有的磁盘存储系统容量不足以存放完整备份,而磁带备份在数据恢复时所需的平均修复时间远远超出预期。
"数据库备份至关重要"是每位 DBA 牢记于心的箴言。然而现实往往并不如人意:备份容量不足、存储设备无法及时采购、需要恢复时却发现备份不可用,这些都是常见的情况。
为了解决这些现实中常见的数据恢复困境,DBRECOVER 软件充分利用了对 Oracle 数据库内部数据结构、核心启动流程及其他内部原理的深入理解。即使在完全没有备份的情况下,它也能应对因 SYSTEM 表空间丢失、对 Oracle 数据字典表的误操作、断电导致数据字典不一致等问题而无法顺利打开数据库的情况。它可以挽救业务数据表被截断、删除或被 DROP 等人为错误,并以更少的人工操作步骤恢复数据。
即使是仅接触 Oracle 数据库几天的非 DBA 人员也能轻松使用 DBRECOVER。这得益于 DBRECOVER 简单的安装方式和完全图形化的用户界面。执行恢复操作的人无需具备深厚的数据库恢复专业知识,无需学习命令行恢复流程,也无需理解底层数据库存储结构。只需点击几下鼠标,就能以更少的人工操作步骤恢复数据。DBRECOVER 打破了只有少数专业人员才能执行数据库恢复任务的局限,大大缩短了从数据库故障到完整数据恢复所需的时间,并降低了企业数据恢复的总成本。
DBRECOVER 可恢复的数据有两种形式。传统的提取方法是从数据文件中提取数据,并写入平面文本文件,然后使用 SQLLDR 等工具导入数据库。这种方法简单直观,但需要相当于现有数据容量两倍的空间:一份用于存放平面文本数据,另一份用于将文本数据导入数据库时所需的空间;耗时也是两倍,因为需要先从数据文件中提取原始数据,才能再导入到新数据库中。
我们强烈推荐另一种方法,即 DBRECOVER 创新的 Data Bridge(数据桥)方法。该方法通过 DBRECOVER 将提取的数据直接装载到新的或其他可用数据库中,避免数据落盘。与传统方法相比,能有效节省数据恢复所需的空间和时间成本。
Oracle 的 ASM(自动存储管理)技术正在被越来越多的企业采用。与传统文件系统相比,使用 ASM 存储的数据库具有高性能、支持集群、管理便利等优点。但 ASM 的问题在于其存储结构过于复杂,普通用户难以理解。一旦 ASM 中某个 Disk Group 的内部数据结构损坏且无法成功 MOUNT,用户的重要数据就会被"锁"在这个 ASM"黑盒"中。此时通常需要熟悉 ASM 内部数据结构的 Oracle 高级工程师到用户现场手动修复 ASM 的内部结构;而对普通用户来说,购买 Oracle 现场服务往往既昂贵又耗时。
由于 DBRECOVER 的开发人员对 Oracle ASM 的内部数据结构有深入理解,DBRECOVER 专门为 ASM 增加了数据恢复功能。
目前 DBRECOVER 支持的 ASM 数据恢复功能包括:
即使 Disk Group 无法正常 MOUNT,DBRECOVER 也可以直接读取 ASM 磁盘上可用的元数据,并根据这些元数据复制 Disk Group 中的 ASM 文件。
即使 Disk Group 无法正常 MOUNT,DBRECOVER 也可以直接读取 ASM 上的数据文件并从中提取数据,同时支持传统提取方式和 Data Bridge 方式。
DBRECOVER for Oracle 简介
DBRECOVER for Oracle 基于 JAVA 开发,这确保了它能够跨平台运行,无论是 AIX、Solaris、HPUX 等 Unix 平台,还是 Redhat、Oracle Linux、SUSE 等 Linux 平台,乃至 Windows 平台。
DBRECOVER 支持的操作系统平台:
| 平台名称 | 支持 |
| Windows | YES |
| AIX | YES |
| Solaris Sparc/X86 | YES |
| Linux x86/64 | YES |
| HPUX | YES |
| MacOS | YES |
DBRECOVER 当前支持的数据库版本:8i ~ 21C
DBRECOVER 自带运行所需的 JAVA 环境,因此在 Windows/Linux 上无需单独安装 JAVA 软件。
在 Windows 上,双击运行 start_dbrecover_windows_local_java.bat
在 Linux 上,执行:sh start_dbrecover_linux_local_java.sh
对于 AIX/HPUX/Solaris 等类 UNIX 环境,用户需要自行安装 JAVA 8 环境。
DBRECOVER 支持的数据库字符集:
| 语言 | 字符集 | 编码 |
| 中文 | ZHS16GBK | GBK |
| 中文 | ZHS16DBCS | CP935 |
| 中文 | ZHT16BIG5 | BIG5 |
| 中文 | ZHT16DBCS | CP937 |
| 中文 | ZHT16HKSCS | CP950 |
| 中文 | ZHS16CGB231280 | GB2312 |
| 中文 | ZHS32GB18030 | GB18030 |
| 日语 | JA16SJIS | SJIS |
| 日语 | JA16EUC | EUC_JP |
| 日语 | JA16DBCS | CP939 |
| 韩语 | KO16MSWIN949 | MS649 |
| 韩语 | KO16KSC5601 | EUC_KR |
| 韩语 | KO16DBCS | CP933 |
| 法语 | WE8MSWIN1252 | CP1252 |
| 法语 | WE8ISO8859P15 | ISO8859_15 |
| 法语 | WE8PC850 | CP850 |
| 法语 | WE8EBCDIC1148 | CP1148 |
| 法语 | WE8ISO8859P1 | ISO8859_1 |
| 法语 | WE8PC863 | CP863 |
| 法语 | WE8EBCDIC1047 | CP1047 |
| 法语 | WE8EBCDIC1147 | CP1147 |
| 德语 | WE8MSWIN1252 | CP1252 |
| 德语 | WE8ISO8859P15 | ISO8859_15 |
| 德语 | WE8PC850 | CP850 |
| 德语 | WE8EBCDIC1141 | CP1141 |
| 德语 | WE8ISO8859P1 | ISO8859_1 |
| 德语 | WE8EBCDIC1148 | CP1148 |
| 意大利语 | WE8MSWIN1252 | CP1252 |
| 意大利语 | WE8ISO8859P15 | ISO8859_15 |
| 意大利语 | WE8PC850 | CP850 |
| 意大利语 | WE8EBCDIC1144 | CP1144 |
| 泰语 | TH8TISASCII | CP874 |
| 泰语 | TH8TISEBCDIC | TIS620 |
| 阿拉伯语 | AR8MSWIN1256 | CP1256 |
| 阿拉伯语 | AR8ISO8859P6 | ISO8859_6 |
| 阿拉伯语 | AR8ADOS720 | CP864 |
| 西班牙语 | WE8MSWIN1252 | CP1252 |
| 西班牙语 | WE8ISO8859P1 | ISO8859_1 |
| 西班牙语 | WE8PC850 | CP850 |
| 西班牙语 | WE8EBCDIC1047 | CP1047 |
| 葡萄牙语 | WE8MSWIN1252 | CP1252 |
| 葡萄牙语 | WE8ISO8859P1 | ISO8859_1 |
| 葡萄牙语 | WE8PC850 | CP850 |
| 葡萄牙语 | WE8EBCDIC1047 | CP1047 |
| 葡萄牙语 | WE8ISO8859P15 | ISO8859_15 |
| 葡萄牙语 | WE8PC860 | CP860 |
DBRECOVER 支持的表存储类型:
| 表存储类型 | 是否支持 |
| 簇表(Cluster Table) | YES |
| 索引组织表(IOT),分区或非分区 | NO |
| 堆组织表,分区或非分区 | YES |
| 基本压缩的堆组织表 | NO |
| 高级压缩(Advanced Compression)的堆组织表 | NO |
| 混合列式压缩(HCC)的堆组织表 | NO |
| 加密的堆组织表 | NO |
| 含虚拟列的表 | NO |
| 行链接、行迁移 | YES |
注意:对于虚拟列和 11g 优化的默认列,数据提取通常不会报错,但对应字段会丢失。这两者都是 11g 之后的特性,使用并不广泛。
DBRECOVER 支持的列字段数据类型:
| 数据类型 | 是否支持 |
| BFILE | No |
| Binary XML | No |
| BINARY_DOUBLE | Yes |
| BINARY_FLOAT | Yes |
| BLOB | Yes |
| CHAR | Yes |
| CLOB 和 NCLOB | Yes |
| 集合类型(包括 VARRAYS 和嵌套表) | No |
| Date | Yes |
| INTERVAL DAY TO SECOND | Yes |
| INTERVAL YEAR TO MONTH | Yes |
| 以 SecureFiles 方式存储的 LOB | Yes |
| LONG | Yes |
| LONG RAW | Yes |
| 多媒体数据类型(包括 Spatial、Image 和 Oracle Text) | No |
| NCHAR | Yes |
| Number | Yes |
| NVARCHAR2 | Yes |
| RAW | Yes |
| ROWID, UROWID | Yes |
| TIMESTAMP | Yes |
| TIMESTAMP WITH LOCAL TIMEZONE | Yes |
| TIMESTAMP WITH TIMEZONE | Yes |
| 用户自定义类型 | No |
| VARCHAR2 和 VARCHAR | Yes |
| 以 CLOB 方式存储的 XMLType | No |
| 以对象关系方式存储的 XMLType | No |
DBRECOVER 对 ASM 的支持:
| 功能 | 是否支持 |
| 支持直接从 ASM 提取数据,无需复制到文件系统 | YES |
| 支持从 ASM 中复制数据文件 | YES |
DBRECOVER 安装与启动
DBRECOVER 是基于 Java 的便携式软件,无需单独的安装流程。用户解压下载的软件 ZIP 包后即可使用该软件进行数据恢复。
启动 DBRECOVER:
- 在 Windows 上:双击运行
start_dbrecover_windows_local_java.bat
- 在 Linux 上:可以在带图形界面的本地机器上使用本软件,也可以使用 Xmanager 或 VNC 等远程图形工具。运行软件前请确认能够打开
xclock图形时钟程序。然后在软件解压所在的目录中执行:sh start_dbrecover_linux_local_java.sh
对于 AIX/HP-UX/Solaris 环境,DBRECOVER 可以在带图形界面的本地机器上使用,或通过 Xmanager、VNC 等远程图形工具使用。启动 DBRECOVER 的步骤如下:
- 确认对应平台的 Java 8 环境已安装。可使用命令
java -version进行确认。
- 确认能够打开
xclock图形时钟程序。
- 在软件解压所在的目录中执行:
sh start_dbrecover.sh
注册 DBRECOVER 许可证
DBRECOVER for Oracle 是商业软件。DBRECOVER 也提供社区版供用户测试和学习。
目前仅提供一种许可证类型,即企业许可证。购买信息请参见 DBRECOVER for Oracle 价格页面。
获取 License Key 后,用户可以自行在软件中完成注册。具体使用方法如下:
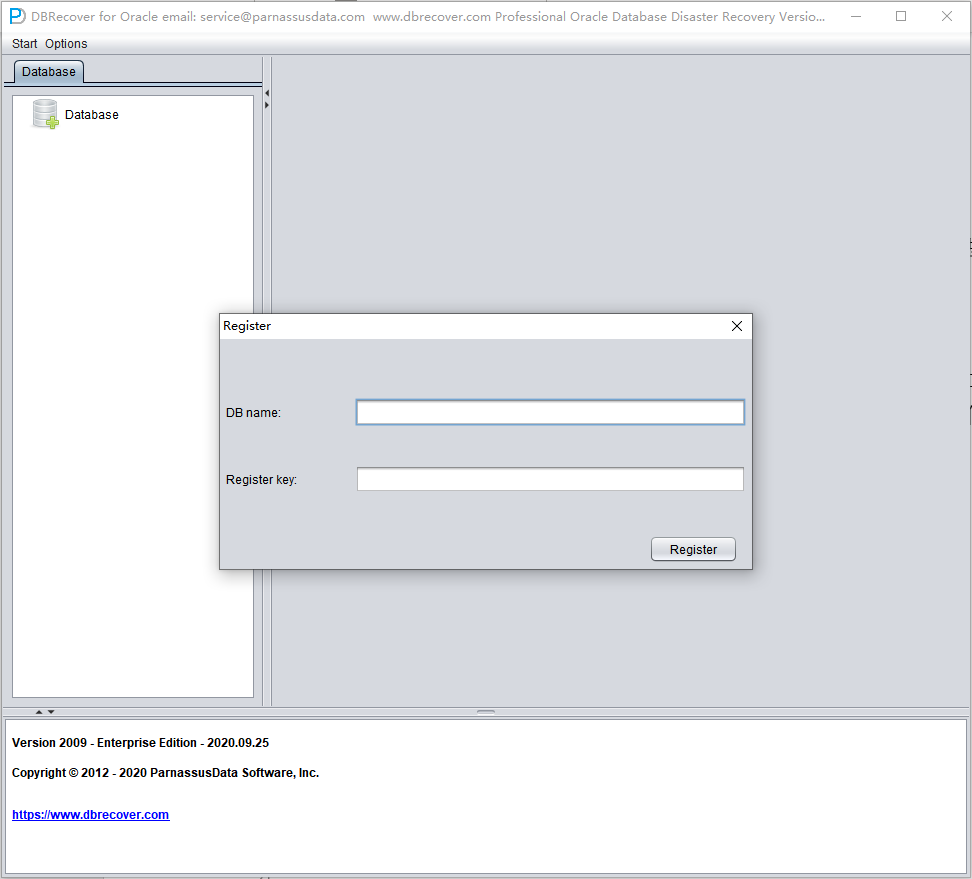
按以下步骤注册 DBRECOVER 许可证:
- 在菜单栏中选择 "Help",然后选择 "Register"。
- 使用购买后获得的信息,输入您的 DB NAME 和 key,然后点击 "Register" 按钮。
- 注册完成后,以后每次重新启动 DBRECOVER 时它都会自动检查许可证注册信息,因此无需再次注册。
可以通过 "Help" => "About" 查看注册成功的信息。
在 Oracle 恢复场景中使用 DBRECOVER
恢复场景 1:Oracle 数据文件损坏导致数据库无法打开
A 公司的生产数据库长期运行在非归档模式下,偶尔做一些 EXP 逻辑备份,但从未做过物理备份。某天服务器断电重启后,数据库无法正常打开使用。检查后发现 SYSTEM 表空间已严重损坏。此时可以使用 DBRECOVER 快速将损坏数据库中的数据迁移到新建数据库,从而快速恢复业务运行。
在与此类似的场景中,如果遇到 ORA-01194、ORA-01110、ORA-01033、ORA-01115、ORA-00368、ORA-00600 kcbzib_kcrsds_1、ORA-00333、ORA-01113、ORA-01122、ORA-27027 等错误导致数据库无法打开,可以参照本恢复场景中所采用的方法尝试恢复数据。
简要步骤如下:
- 使用 dbca 新建一个 ORACLE 数据库,确保字符集与损坏数据库一致
- 在新数据库中创建对应的数据库用户和表空间,建议临时为这些用户授予 DBA 角色
- 启动监听程序(LISTENER),确保数据库服务已注册到监听器
- 以 Dictionary mode(字典模式)启动 DBRECOVER,并加载来自原损坏数据库的所有数据文件
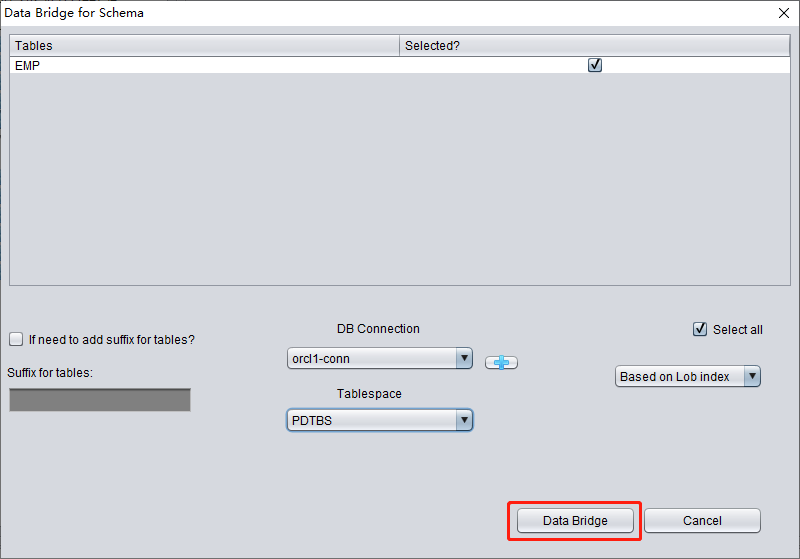
- 在 DBRECOVER 中选中需要恢复的用户名,右键点击并选择 Data Bridge(数据桥)
- 在 Data Bridge 界面中,点击加号图标添加新数据库的连接信息(Connection)
- 点击 Data Bridge 启动传输作业,等待该 SCHEMA 下的所有表传输到目标数据库的目标 SCHEMA
- 选中对应的 SCHEMA,右键选择 EXPORTDDL 导出 DDL 功能,选择需要恢复的对象类型并点击 EXPORT
- 根据 EXPORTDDL 生成的 DDL SQL 文件,在目标数据库的目标 SCHEMA 中手动执行
恢复提示:启动监听程序(LISTENER),确保数据库服务已注册到监听器。
C:\Users\testenv>lsnrctl status
LSNRCTL for 64-bit Windows: Version 11.2.0.1.0 - Production on 12-MAY-2023 10:01:48
Copyright (c) 1991, 2010, Oracle. All rights reserved.
Connecting to (DESCRIPTION=(ADDRESS=(PROTOCOL=TCP)(HOST=DESKTOP-testenv)(PORT=1521)))
STATUS of the LISTENER
-----------------------
Alias LISTENER
Version TNSLSNR for 64-bit Windows: Version 11.2.0.1.0 - Production
Start Date 12-MAY-2023 10:00:49
Uptime 0 days 0 hr. 0 min. 59 sec
Trace Level off
Security ON: Local OS Authentication
SNMP OFF
Listener Parameter File D:\app\testenv\product\11.2.0\dbhome_2\network\admin\listener.ora
Listener Log File d:\app\testenv\diag\tnslsnr\DESKTOP-testenv\listener\alert\log.xml
Listening Endpoints Summary...
(DESCRIPTION=(ADDRESS=(PROTOCOL=tcp)(HOST=DESKTOP-testenv)(PORT=1521)))
(DESCRIPTION=(ADDRESS=(PROTOCOL=ipc)(PIPENAME=\\.\pipe\EXTPROC1521ipc)))
Services Summary...
Service "CLRExtProc" has 1 instance(s).
Instance "CLRExtProc", status UNKNOWN, has 1 handler(s) for this service...
Service "ORCL1XDB" has 1 instance(s).
Instance "orcl1", status READY, has 1 handler(s) for this service...
Service "ORCLXDB" has 1 instance(s).
Instance "orcl", status READY, has 1 handler(s) for this service...
Service "orcl" has 1 instance(s).
Instance "orcl", status READY, has 1 handler(s) for this service...
Service "orcl1" has 1 instance(s).
Instance "orcl1", status READY, has 1 handler(s) for this service...
The command completed successfully
恢复提示:在新数据库中创建对应的数据库用户和表空间,建议临时为这些用户授予 DBA 角色。
set ORACLE_SID=ORCL1
sqlplus / as sysdba
SQL> create user pd identified by oracle;
User created.
SQL> grant dba to pd;
Grant succeeded.
SQL> create tablespace pdtbs datafile size 500M autoextend on next 100M;
Tablespace created.
SQL> alter user pd default tablespace pdtbs;
User altered.
启动 DBRECOVER,然后选择 Tools => Recovery Wizard(恢复向导)
点击 Next。
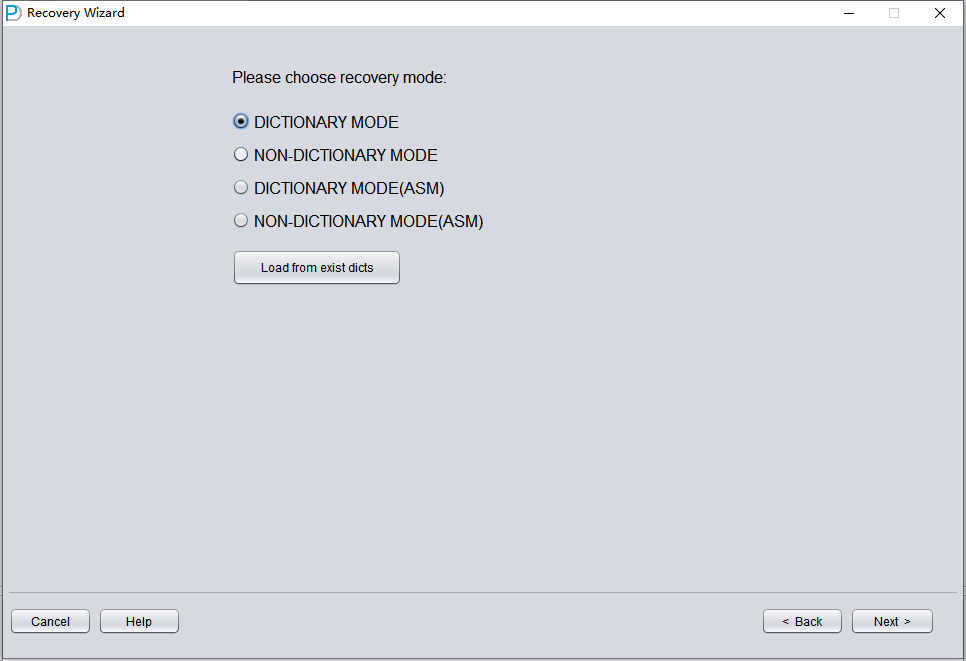
下一步是选择正确的 ENDIAN(字节序)。Oracle 数据文件在不同操作系统平台上采用不同的 Endian 字节格式。
Endian(字节序)是多字节数据类型在内存中的存储方式,它决定数据的字节顺序。Endian 有两种:Little 和 Big。在 Little Endian 中,数据按低字节在前的方式存储,也就是低位字节存放在最前面;而在 Big Endian 中,数据按高字节在前的方式存储,最前面的字节是最高位。
在 Oracle 数据库中,endian 格式由其所运行环境的字节序信息决定。数据库的 endian 格式决定了它可以迁移到哪些环境。无法用常规方法在不同 endian 环境之间迁移数据库。例如,无法使用 Data Guard 将数据库从 Little Endian 系统迁移到 Big Endian 系统。
可通过以下查询查看当前数据库的 endian 格式:
查询结果会给出当前数据库的 endian 格式。
使用 Big Endian 格式的平台包括:IBM AIX、Apple Mac OS、HP-UX (64-bit)、HP-UX IA (64-bit)、IBM Power Based Linux、IBM zSeries Based Linux 以及 Solaris OE(32 位和 64 位)。
使用 Little Endian 格式的平台包括:Linux x86 64-bit、Apple Mac OS (x86-64)、HP IA Open VMS、HP Open VMS、HP Tru64 UNIX、Linux IA (32-bit)、Linux IA (64-bit)、Microsoft Windows IA (32-bit)、Microsoft Windows IA (64-bit)、Microsoft Windows x86 64-bit 以及 Solaris Operating System (x86 和 x86-64)。
字节序与平台的对应关系如下:
| 平台 | 字节序 |
| Solaris[tm] OE (32-bit) | Big |
| Solaris[tm] OE (64-bit) | Big |
| Microsoft Windows IA (32-bit) | Little |
| Linux IA (32-bit) | Little |
| AIX-Based Systems (64-bit) | Big |
| HP-UX (64-bit) | Big |
| HP Tru64 UNIX | Little |
| HP-UX IA (64-bit) | Big |
| Linux IA (64-bit) | Little |
| HP Open VMS | Little |
| Microsoft Windows IA (64-bit) | Little |
| IBM zSeries Based Linux | Big |
| Linux x86 64-bit | Little |
| Apple Mac OS | Big |
| Microsoft Windows x86 64-bit | Little |
| Solaris Operating System (x86) | Little |
| IBM Power Based Linux | Big |
| HP IA Open VMS | Little |
| Solaris Operating System (x86-64) | Little |
| Apple Mac OS (x86-64) | Little |
只需注意:最常用的 Windows 和 Linux 平台都是 Little Endian,无需做任何设置,保持默认即可。
在中型 Unix 平台上,包括 AIX-Based Systems (64-bit) 和 HP-UX (64-bit) 等,使用的是 Big Endian,因此这里应当选择 Big Endian。
请注意:如果您的数据文件是在 AIX(即 Big Endian)上生成的,并且为了方便将这些数据文件复制到 Windows 服务器上使用 DBRECOVER 进行恢复,仍应选择其原始的 Big Endian 格式。
这里我们恢复的是来自 Linux x86-64 平台的 Oracle 数据库文件,所以 Endian 选择 Little Endian。
点击 Next
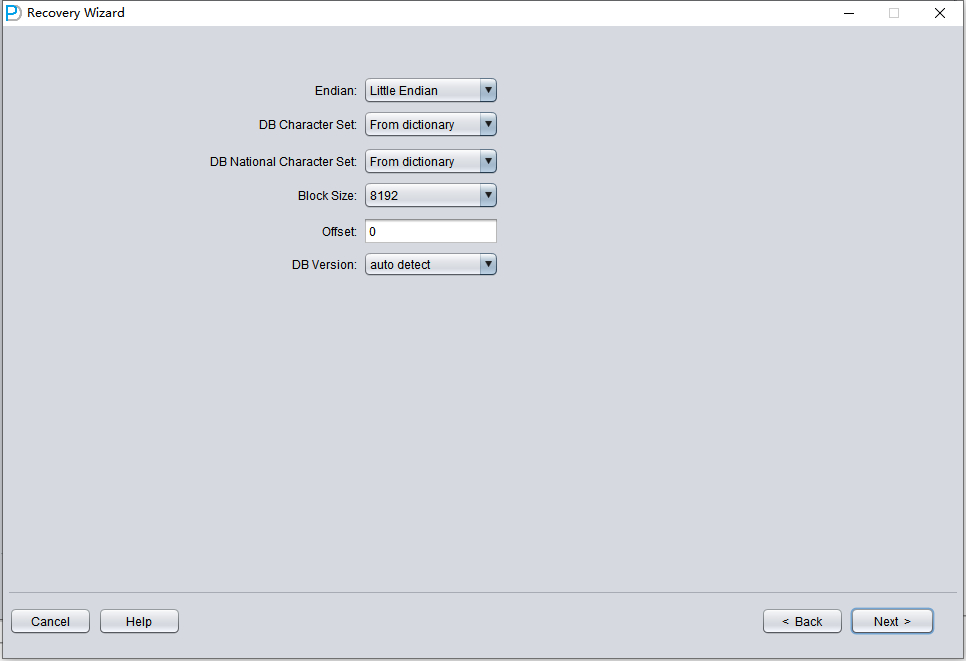
点击 'Choose Files'。一般我们建议:如果数据库不大,就选中该数据库的全部数据文件。如果您的数据库非常大,并且明确知道数据表所在的数据文件,那么可以只选择 SYSTEM 表空间的数据文件(必选!)以及数据所在的数据文件。
注意:Choose 界面支持 Ctrl + A 和 Shift 等键盘操作。
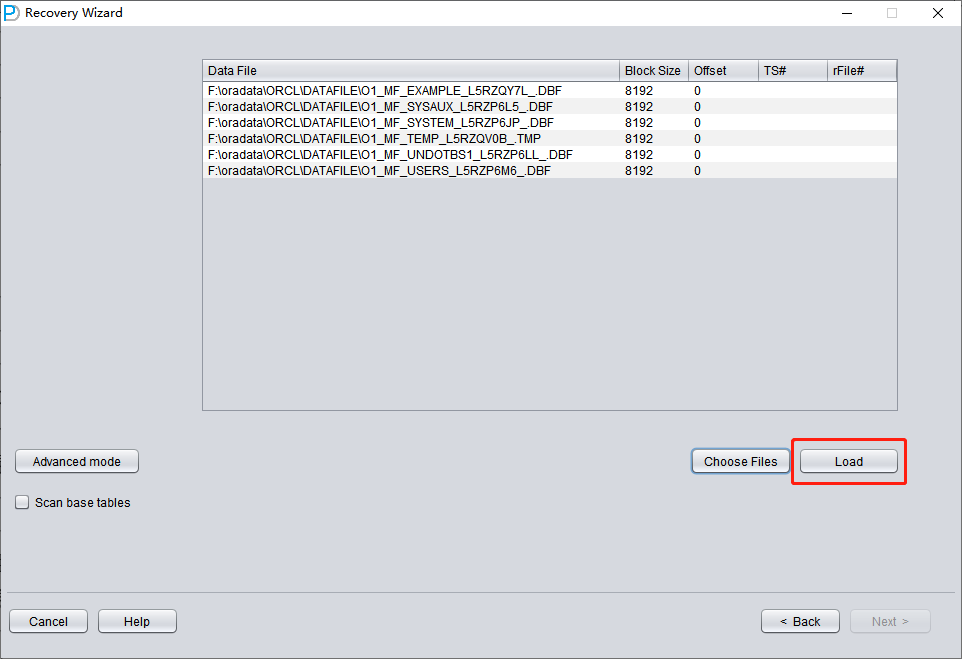
注意:添加完所有数据文件后,如果不了解该界面上的其他参数,请保持默认值,不要修改。
接下来需要为指定的数据文件设置 Block Size(块大小),即 ORACLE 数据块的大小。可根据实际情况修改:例如您的 DB_BLOCK_SIZE 为 8K,但某些表空间指定 16K 作为数据块大小,那么只需将这些非 8K 的数据文件的 BLOCK_SIZE 修改即可。
在使用常规文件系统的情况下,这里无需指定 OFFSET。OFFSET 参数主要针对使用裸设备(raw device)存放数据文件的场景。例如在 AIX 上,如果使用普通 VG 的 LV 作为数据文件,则有 4k 的 OFFSET 需要在此指定。
如果您正好使用裸设备数据文件,且不清楚 OFFSET 是多少,可以使用 $ORACLE_HOME/bin 自带的 dbfsize 工具进行检查。下面的示例表明该裸设备不存在 4K 的 OFFSET:
$ dbfsize /dev/lv_control_01
Database file: /dev/lv_control_01
Database file type: raw device without 4K starting offset
Database file size: 334 16384 byte blocks
本场景中所有数据文件的 BLOCK SIZE 均为 8K 且基于文件系统,没有 OFFSET,因此直接点击 'Load'。
在 Load 阶段,DBRECOVER 会从 SYSTEM 表空间读取 ORACLE 数据字典信息,并在其内置的 Derby 中构建一份数据字典。这样 DBRECOVER 就具备了分析 ORACLE 数据库各类数据的能力。
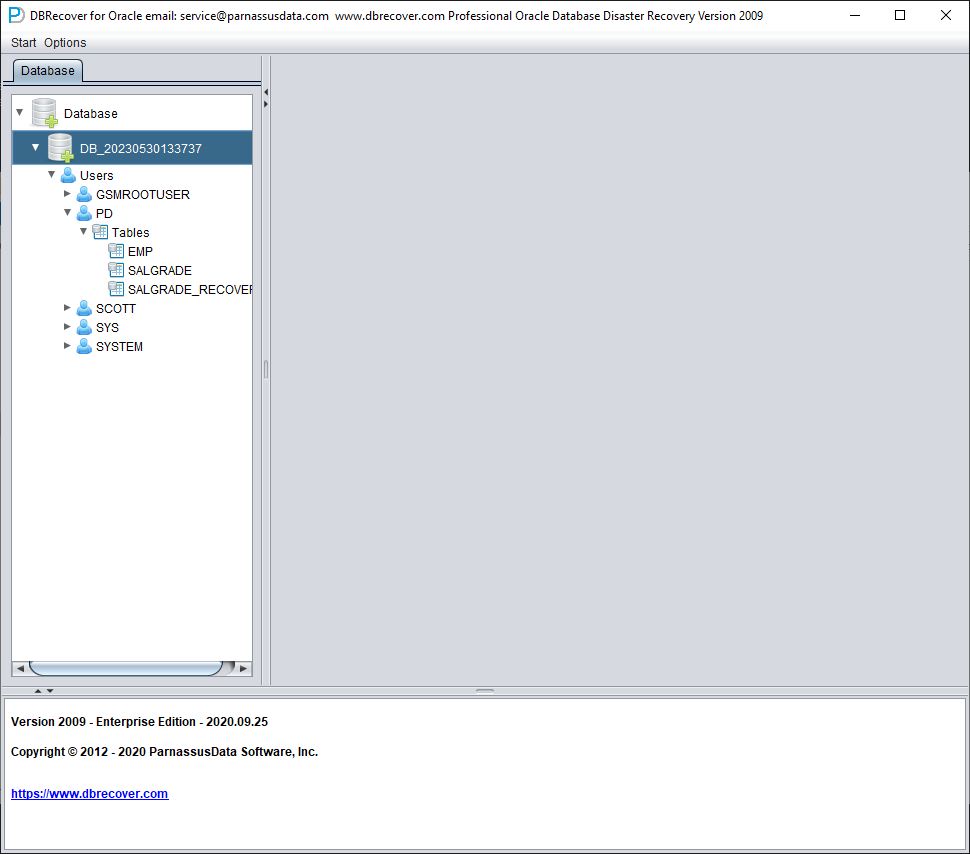
Load 完成后,DBRECOVER 界面左侧会按数据库用户分组显示一棵树形图:
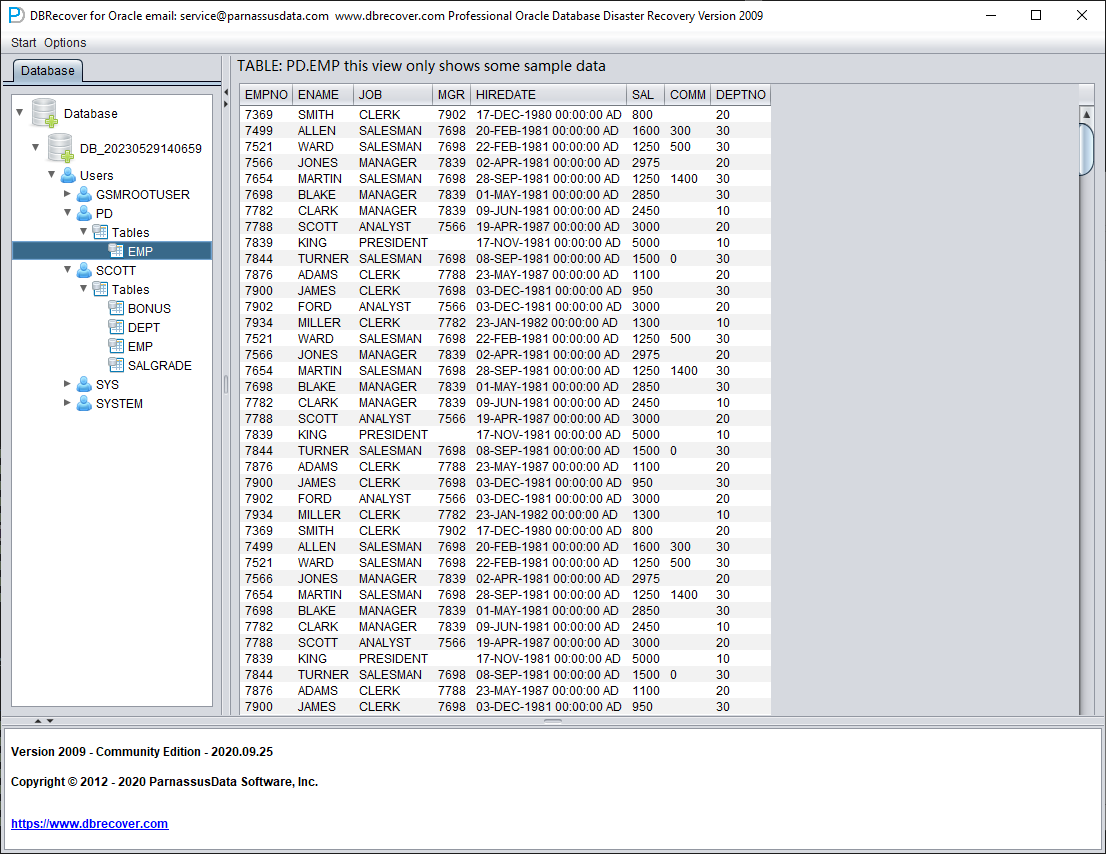
选择您要恢复的表,双击即可查看数据:
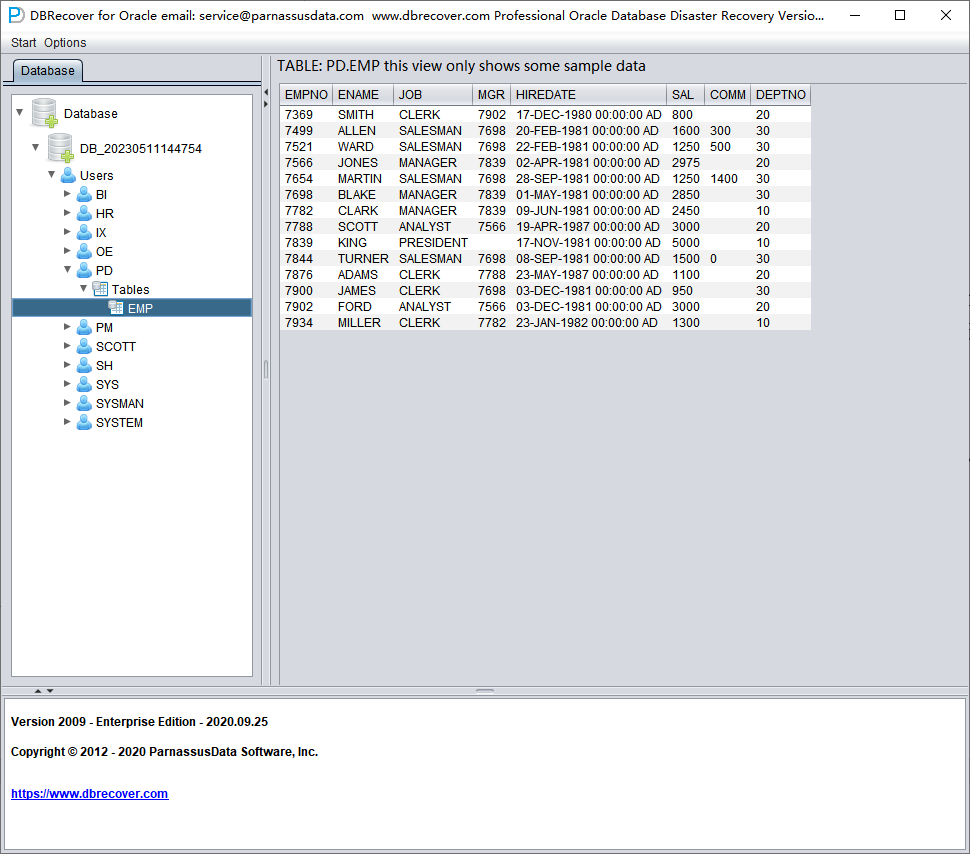
在尚未购买软件许可证的情况下,可以通过浏览数据表、最多提取 10000 行数据以及检查可恢复行数等功能,来评估 DBRECOVER 是否能恢复足够的数据。
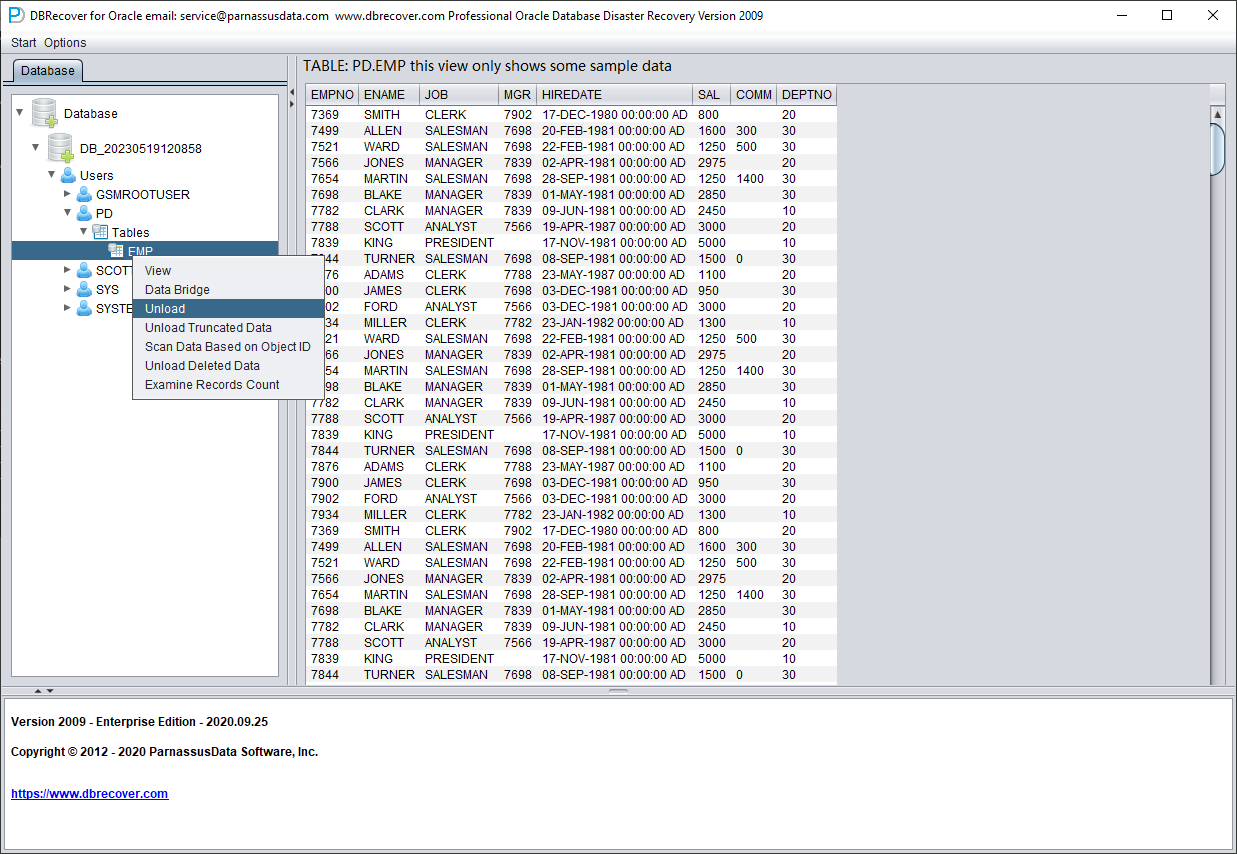
选中表后,右键点击 UNLOAD,即可将表数据导出为文本格式:
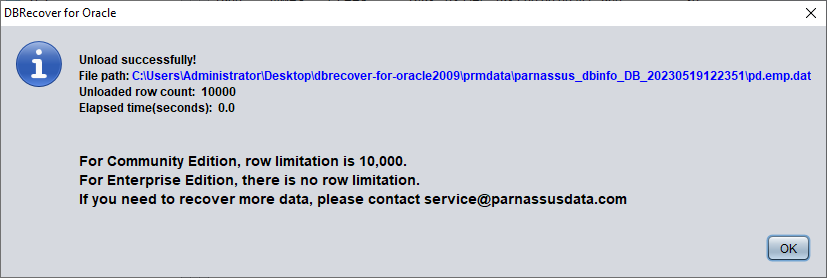
在未注册软件许可证的情况下,单张表最多可提取 10000 行数据。
对于存储超过 10000 行数据的表,可以使用检查可恢复行数的功能进行进一步验证。选中要检查的表,右键点击 EXAMINE RECORDS COUNT:
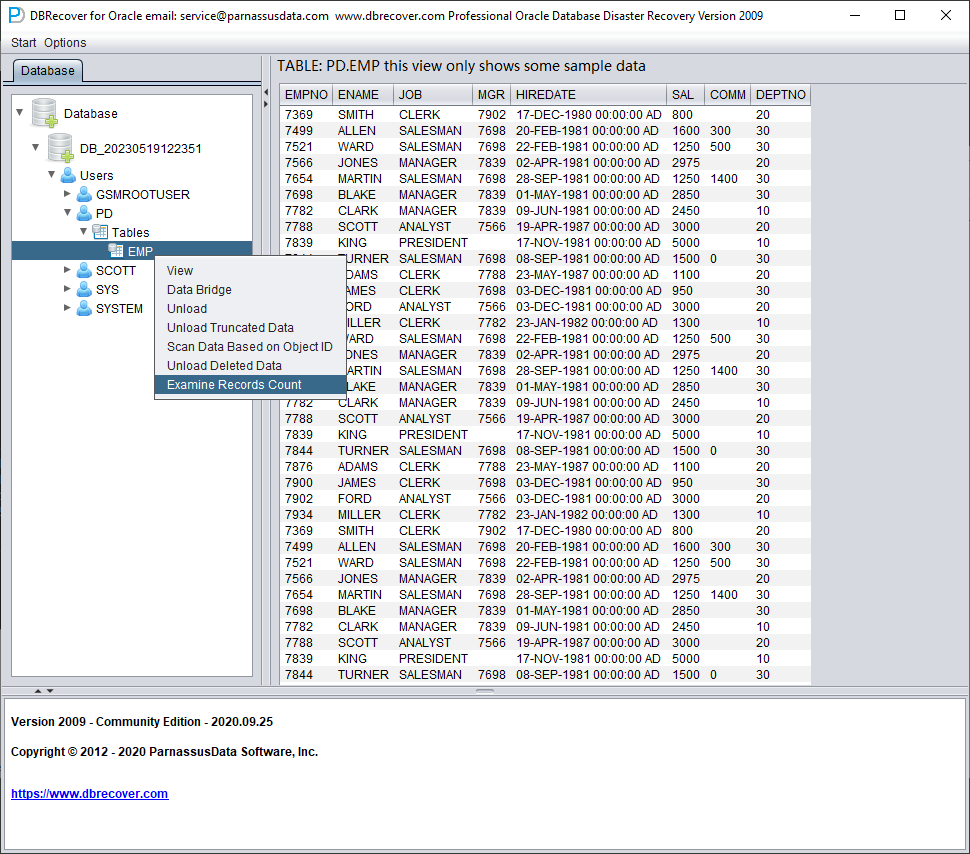
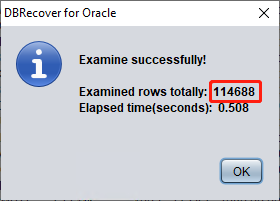
从 Oracle 10g 开始,引入了自动收集统计信息作业的特性。借助该特性,我们可以查看表的历史统计信息,包括行数。在 Dictionary mode(字典模式)下,每次浏览、提取或检查某张表时,软件都会将表的元数据写入日志文件 log_dbrecover.txt。该日志文件存放在软件目录下:
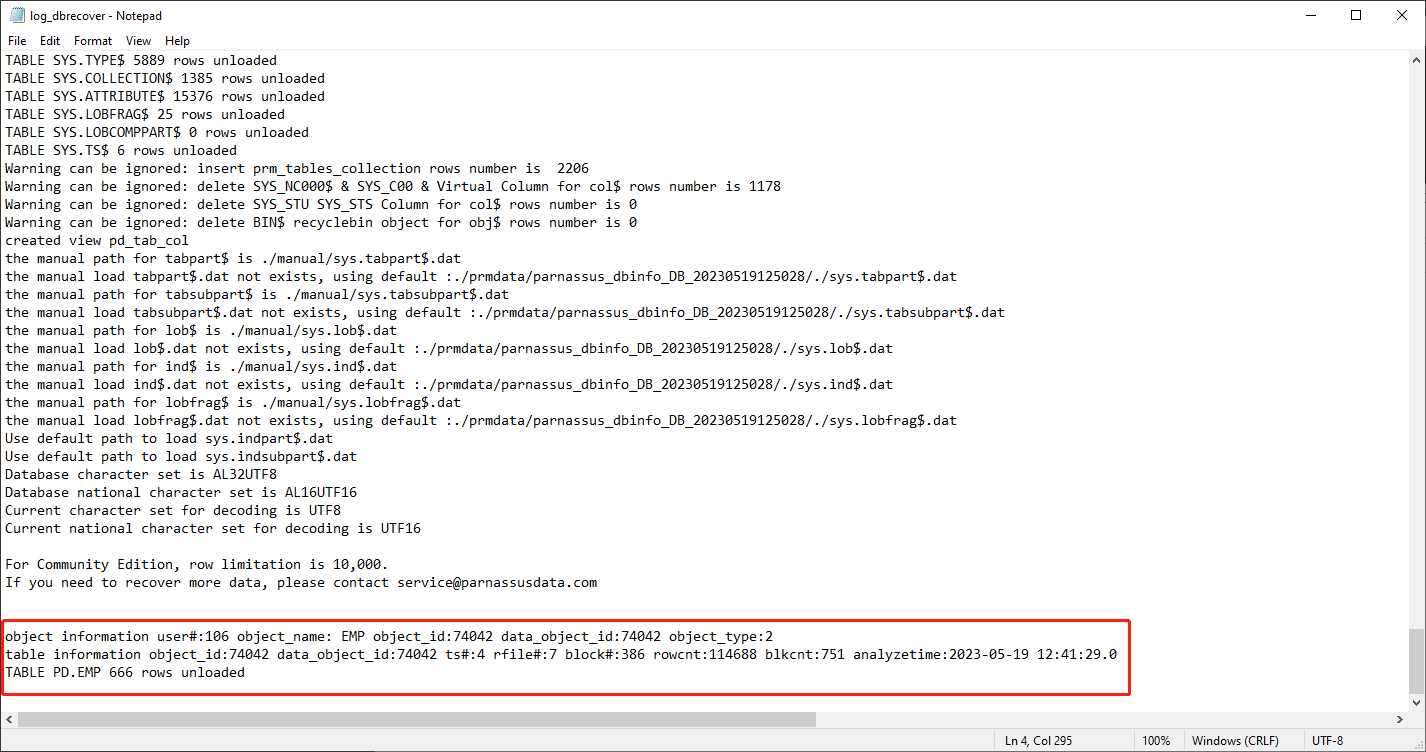
检查该日志文件:
object information user#:106 object_name: EMP object_id:74042 data_object_id:74042 object_type:2
table information object_id:74042 data_object_id:74042 ts#:4 rfile#:7 block#:386 rowcnt:114688 blkcnt:751 analyzetime:2023-05-19 12:41:29.0
TABLE PD.EMP 666 rows unloaded
日志中包含许多有用的信息:
| object_id | 74042 |
| data_object_id | 74042 |
| ts# | 4 |
| rfile# | 7 |
| block# | 386 |
| rowcnt | 114688 |
| blkcnt | 751 |
| analyzetime | 2023-05-19 12:41:29.0 |
通常统计信息的误差不超过 10%,因此可以根据这里的 rowcnt 来对比检查行数的结果。例如这里 rowcnt 为 114688(对于小于 100 万行的表,统计信息的误差非常小),而 EXAMINE 的结果也是 114688 行,可以验证该结果的真实性。
用户可根据自身需求对每张重要的数据表执行上述检查。建议用户在购买软件许可证之前充分检查可恢复数据的完整性。
完成上述检查后,我们以 SCHEMA 用户为单位启动 Data Bridge 传输。在需要恢复的用户名上右键点击 Data Bridge。
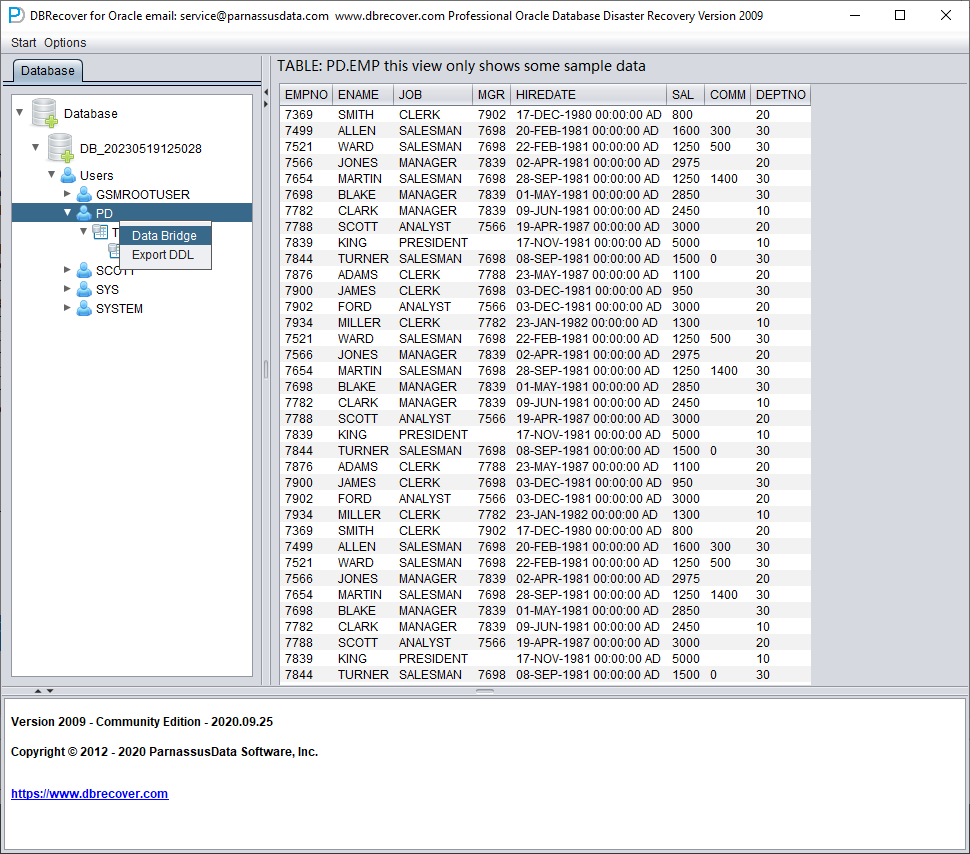
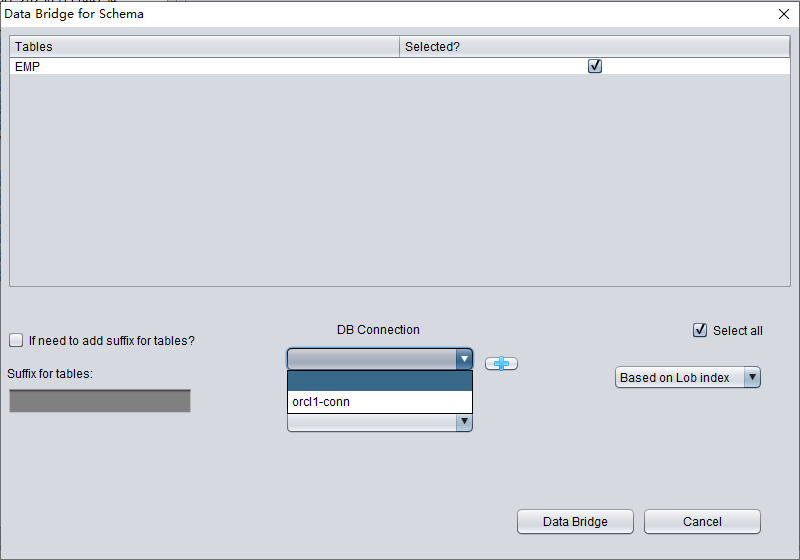
在 SCHEMA 级别的 Data Bridge 界面中,点击 "+" 按钮添加目标数据库链接信息:
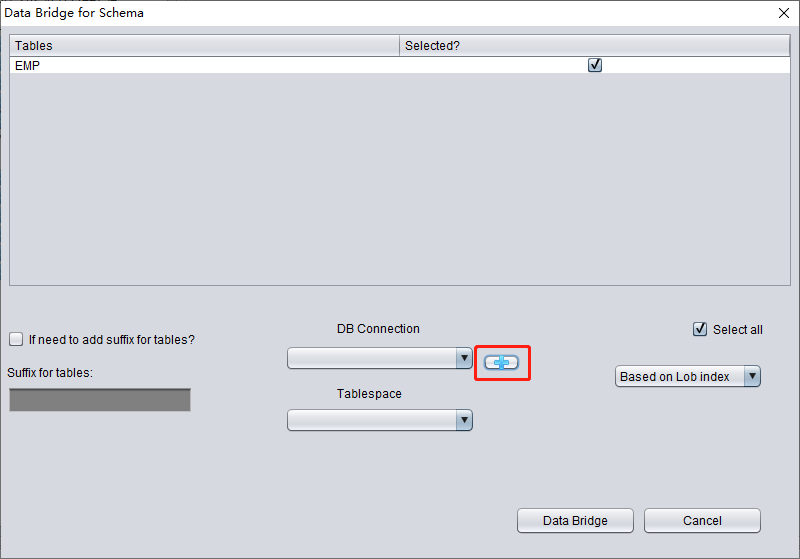
输入新建实例的连接信息,这里使用 PD 用户。
注意:DBRECOVER 软件只会将数据传输给数据库链接信息中所指定的用户,也就是说,如果这里填写 PD,数据就会被传输到 PD。客户应遵循简单的一对一原则,即如果有需要恢复的数据库用户(例如 EAS),则在目标数据库中创建 EAS 用户及其表空间并授予必要的权限(DBA 角色),并在该数据库链接中填写 EAS,以确保数据传输到 EAS。这里的 PD 只是示例。如果客户希望恢复多个数据库用户(例如 EAS、MES、NC001 等),就需要在目标数据库中相应地创建这些账号及其表空间并授予必要权限(DBA 角色),然后在 DBRECOVER 中创建多个数据库链接信息(DB Connection),在传输特定用户 SCHEMA 时指定对应的数据库链接信息(DB Connection)。
点击 TEST 测试目标数据库链接的可用性:
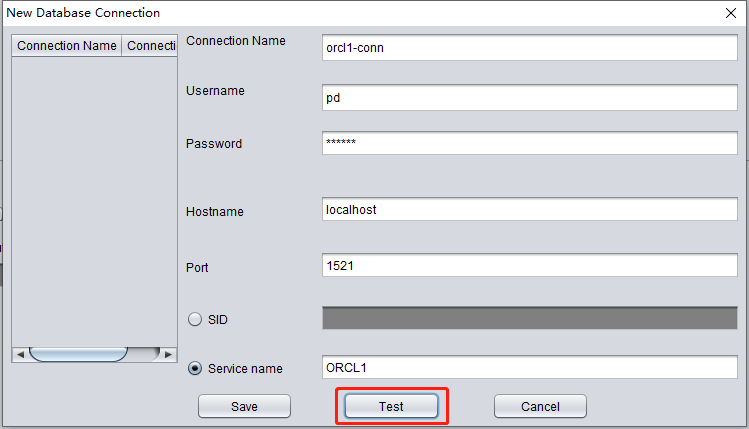
测试成功后,点击 SAVE 保存:
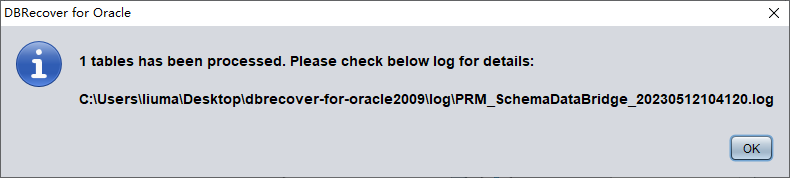
检查数据
SQL> show parameter db_name
NAME TYPE VALUE
----------------------------------- ---------------------- ------------------------------
db_name string ORCL1
SQL> select count(*) from pd.emp;
COUNT(*)
---------
14
WIDE TABLE 模式介绍
注意:上述 Data Bridge 默认使用 WIDE TABLE(宽表)模式传输数据,即默认将所有 CHAR、NCHAR、VARCHAR、NVARCHAR 字段类型转换为其最大长度(2000 或 4000)。这样做是为了避免因字段长度过短而导致恢复出的字符串无法顺利插入的问题。
如果不想使用 WIDE TABLE 模式,可在菜单栏点击 Options => Preferences。
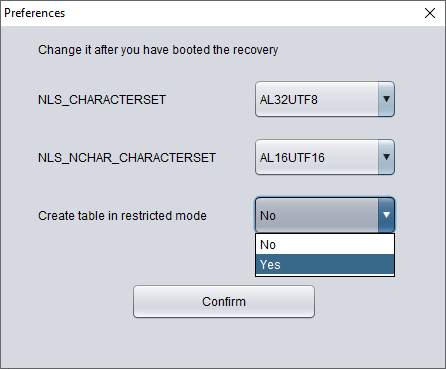
在上图中,将 'Create table in restricted mode' 下拉框选为 'Yes',即可阻止以 WIDE TABLE 模式创建数据表。
EXPORT DDL 功能介绍
上述恢复操作针对的是单个 SCHEMA 的数据表,所恢复的对象包括:创建对应的数据表并插入可恢复的数据。
对于索引、约束、视图、触发器及其他对象的恢复,可以使用 EXPORT DDL 功能。
选中要恢复的 SCHEMA,右键选择 EXPORT DDL 功能:
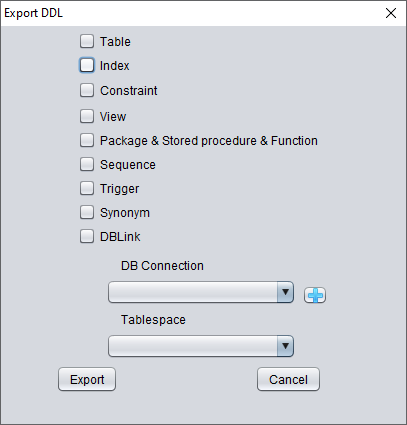
可恢复的对象类型包括:
- Create table 语句(注意不包含分区信息)
- Create index 语句(注意不包含分区信息)
- 约束(Constraint)
- 视图(View)
- 包、存储过程与函数(Package & Stored Procedure & Function)
- 序列(Sequence)
- 触发器(Trigger)
- 同义词(Synonym)
- DBlink(数据库链接)
这里选择之前已输入的数据库链接信息用于临时处理 DDL 信息。
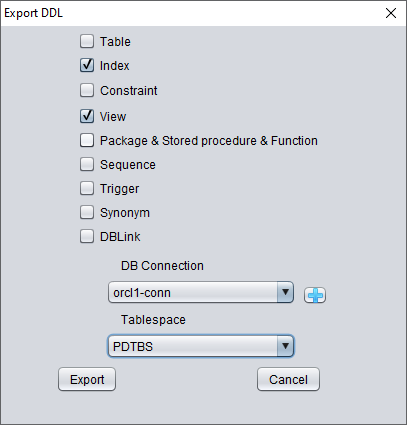

弹出窗口将显示 DDL SQL 文件的路径,查看该文件:
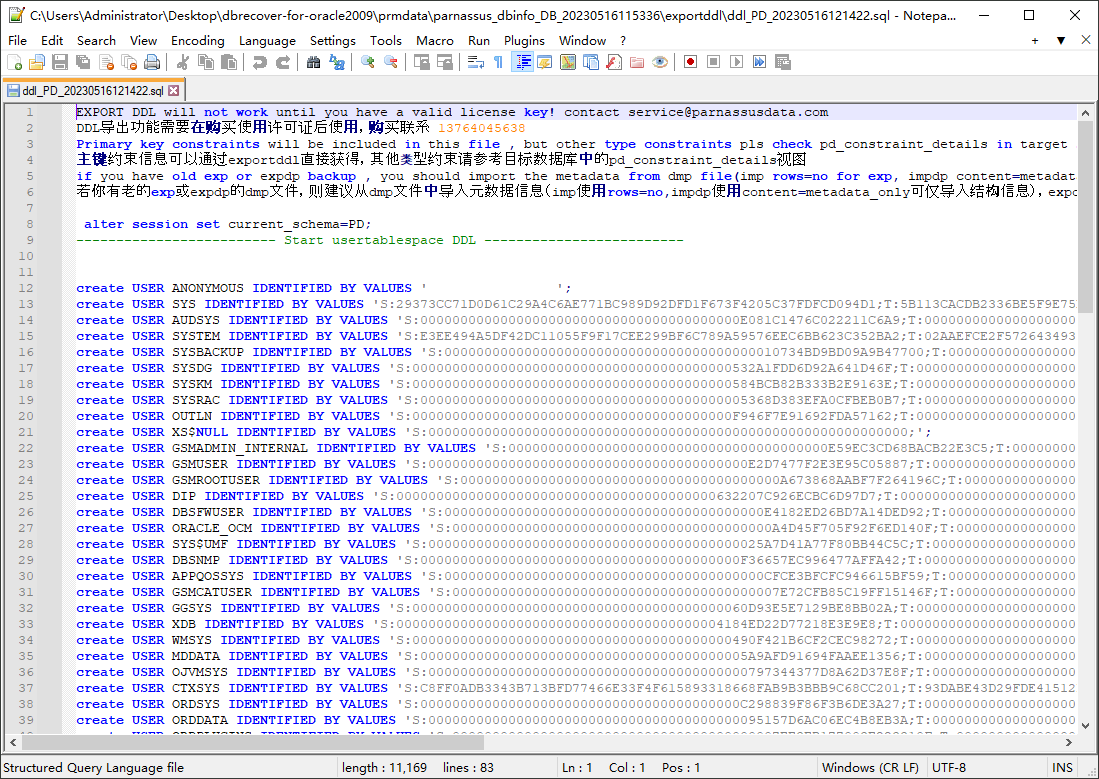
注意:EXPORTDDL 功能只有在注册了有效的企业版许可证(LICENSE KEY)后才能正常使用!
上述 DDL SQL 文件中创建索引、视图及其他对象的语句需要由用户复制并在对应的数据库用户下执行。
如果用户拥有旧的 exp 或 expdp dmp 文件,建议从 dmp 文件中导入元数据信息(imp 使用 rows=no,impdp 使用 content=metadata_only,仅导入结构信息)。exportddl 功能会缺少少量元数据信息,例如对象授权和外键等。
LOAD FROM EXIST DICTS 功能介绍:
在实际的恢复过程中,如果遇到程序无响应、卡顿或报错的情况,可以在重启 DBRECOVER 后使用 LOAD FROM EXIST DICTS 功能直接加载之前的恢复状态。
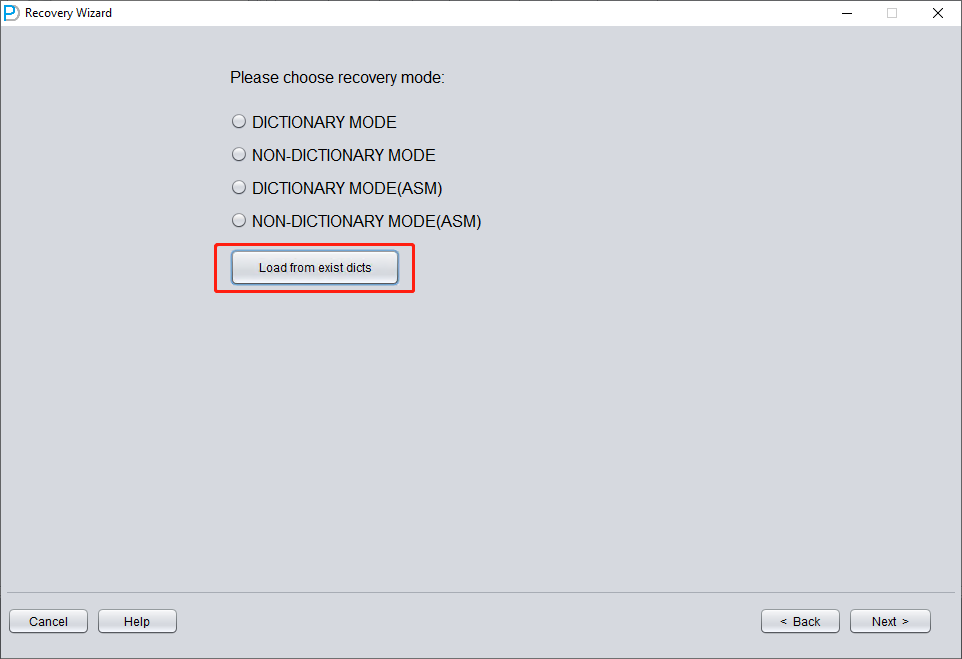
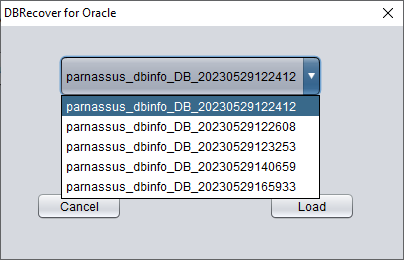
恢复状态按时间排序。选择合适的状态后,点击 LOAD 按钮即可加载。Dictionary mode(字典模式)和 Non-Dictionary mode(非字典模式)都可使用该快速加载功能,以避免重复操作。
恢复场景 2:SYSTEM 表空间被误删除或完全丢失
D 公司的 SA 系统管理员误删了某数据库 SYSTEM 表空间所在的数据文件,导致数据库完全无法打开,数据无法导出。在没有备份的情况下,可以使用 DBRECOVER 挖掘数据。
在此场景下,启动 DBRECOVER 进入 Recovery Wizard 后,选择 'Non-Dictionary mode'(非字典模式):
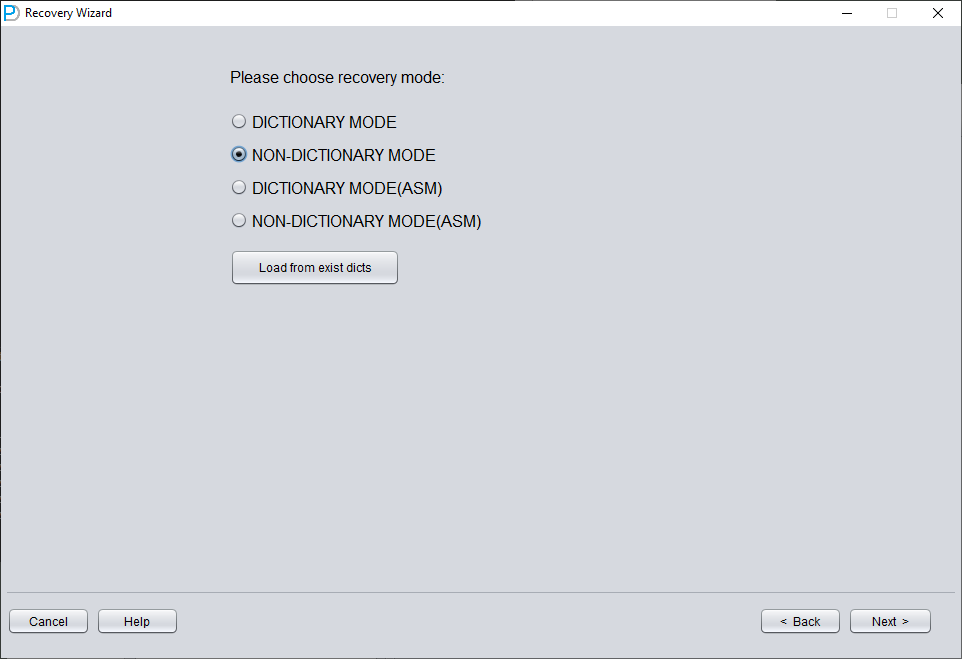
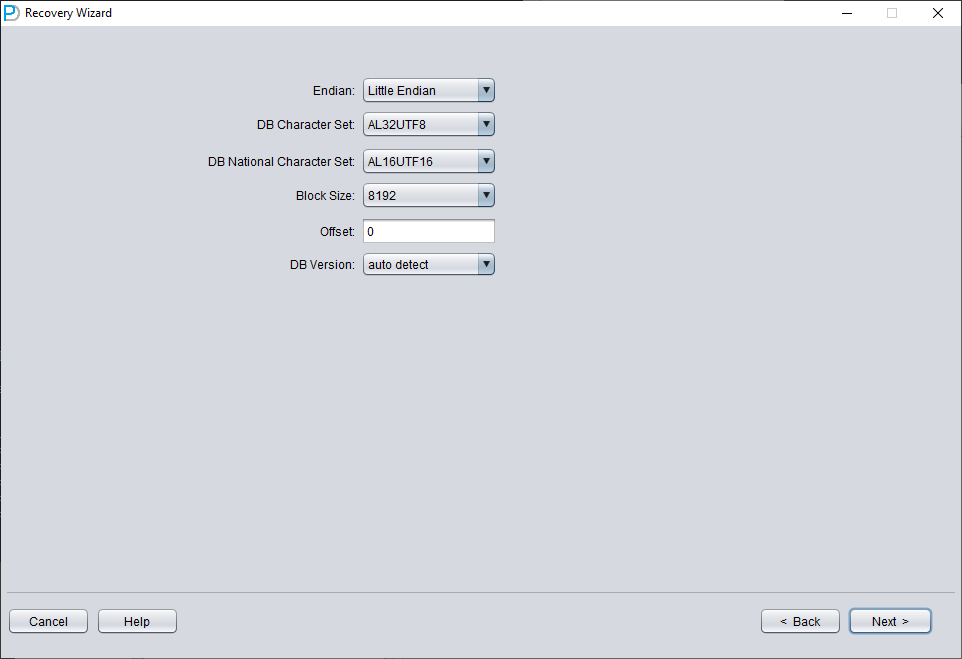
然后需要选择正确的字符集,否则后续数据会出现乱码。
在 Non-Dictionary mode 下,必须指定字符集和国家字符集。SYSTEM 表空间丢失后,数据库的字符集元数据无法读取,因此 DBRECOVER 需要您手动提供。Non-Dictionary mode 下的多语言数据提取只有在同时配置正确的字符集和对应语言包时才能正常工作。
与场景 1 类似,导入用户当前可用的全部数据文件(不含临时文件),并设置正确的 Block Size 和 OFFSET:
然后点击 SCAN。SCAN 的功能是扫描所有数据文件中的数据信息。
然后在左侧树形图中右键点击数据库节点执行 SCAN EXTENT。仅当能够确认所有数据文件(SYSTEM01.DBF 除外)都完好可用时,才使用 SCAN TABLE FROM SEGMENTS 模式。该模式的优势是稍快一些,但当数据文件不完整或损坏时,其恢复程度低于 SCAN EXTENT 模式。
Scan Tables From Extents 完成后,可以展开主界面左侧的树形图:
树形图中的每个节点代表一个常规堆表或分区的数据段,节点名称为 obj + 数据段上记录的 DATA OBJECT ID。
点击某个节点,观察主界面右侧的侧边栏:
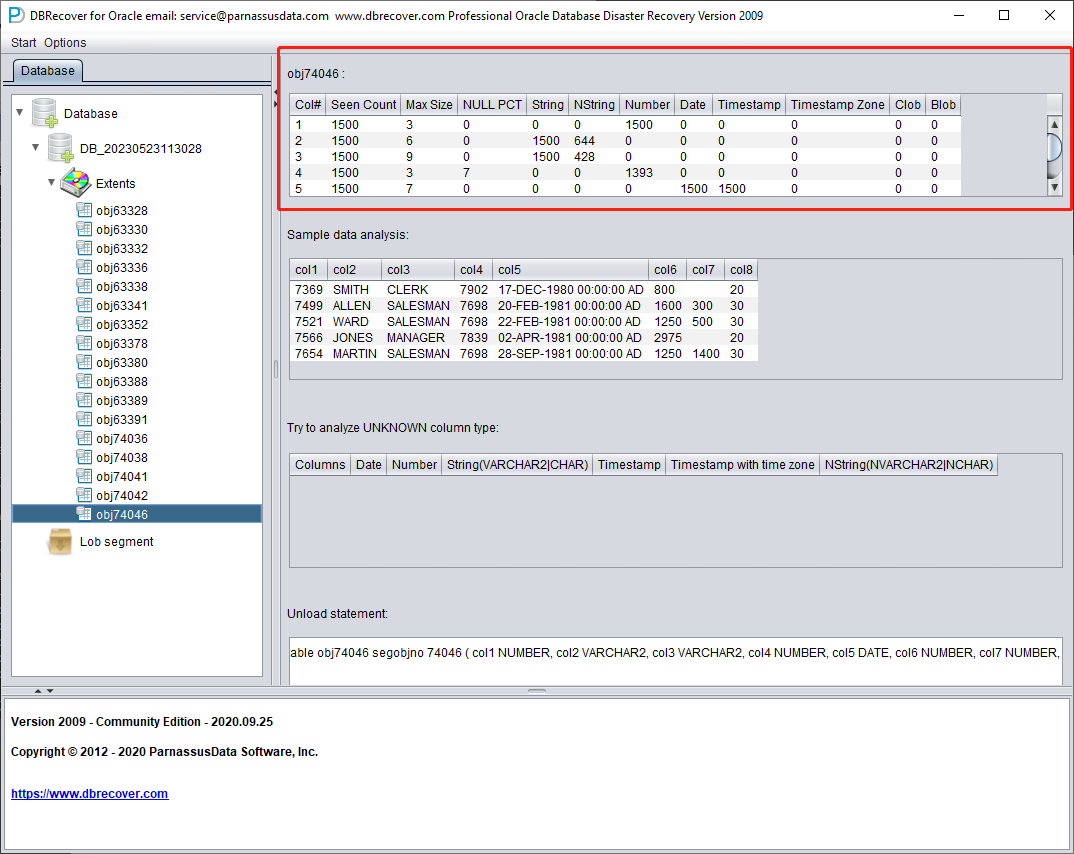
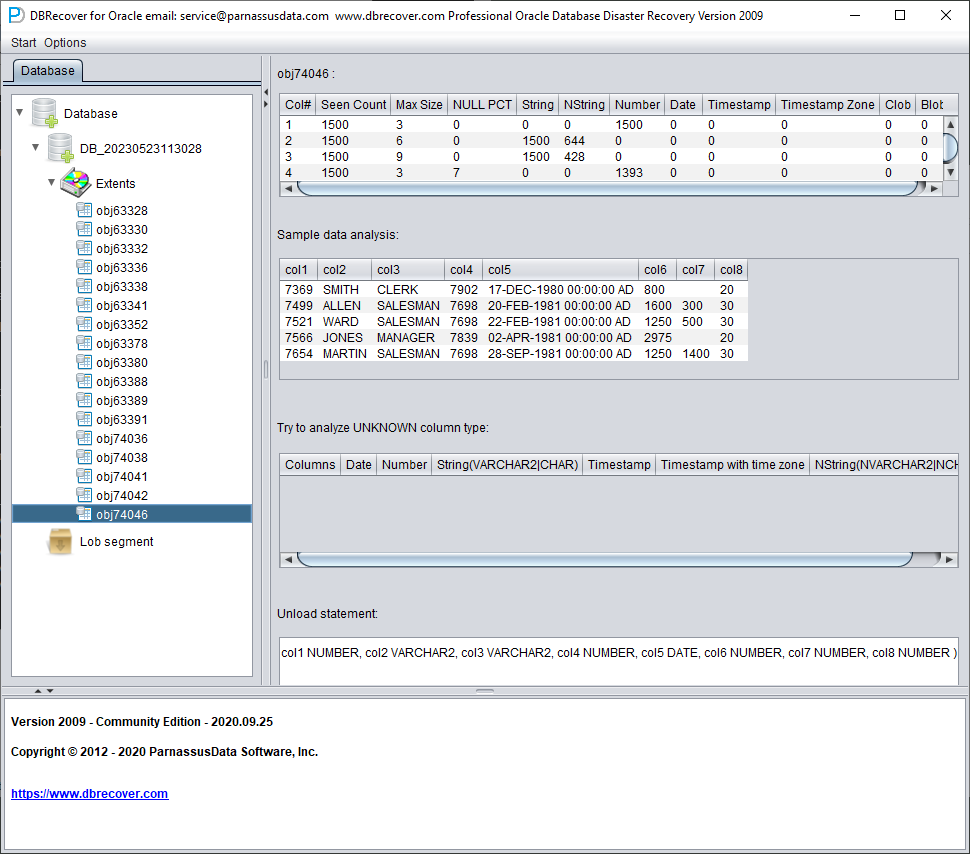
字段类型分析
由于 SYSTEM 表空间丢失,Non-Dictionary mode 下缺少数据表的结构信息。结构信息包括表上的字段名和字段类型,而在 ORACLE 中这些信息仅以字典信息形式保存,并不存储在数据表上。当用户只拥有应用数据所在的表空间时,需要根据数据段上的 ROW 数据来推测每个字段的类型。这里我们可以解析十多种主流数据类型:
- String:包括 char、varchar
- NString 国家字符串:nchar、nvarchar
- Number 数值类型
- Date 日期类型
- TimeStamp 类型
- 带时区的 TimeStamp Zone 类型
- CLOB
- BLOB
样本数据分析
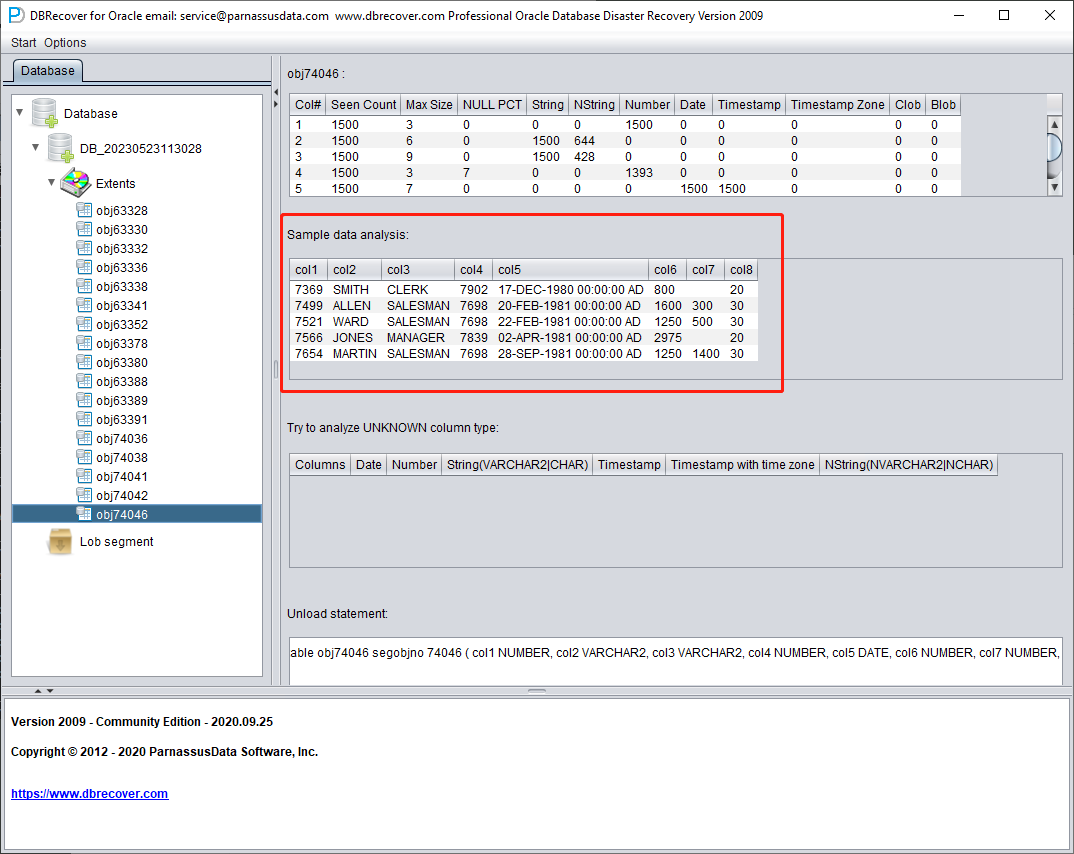
此部分根据字段类型分析的结果解析 10 条数据并展示解析结果。样本数据可以帮助用户了解该数据段中实际存储的数据。如果数据段记录数不足 10 条,则会全部显示。
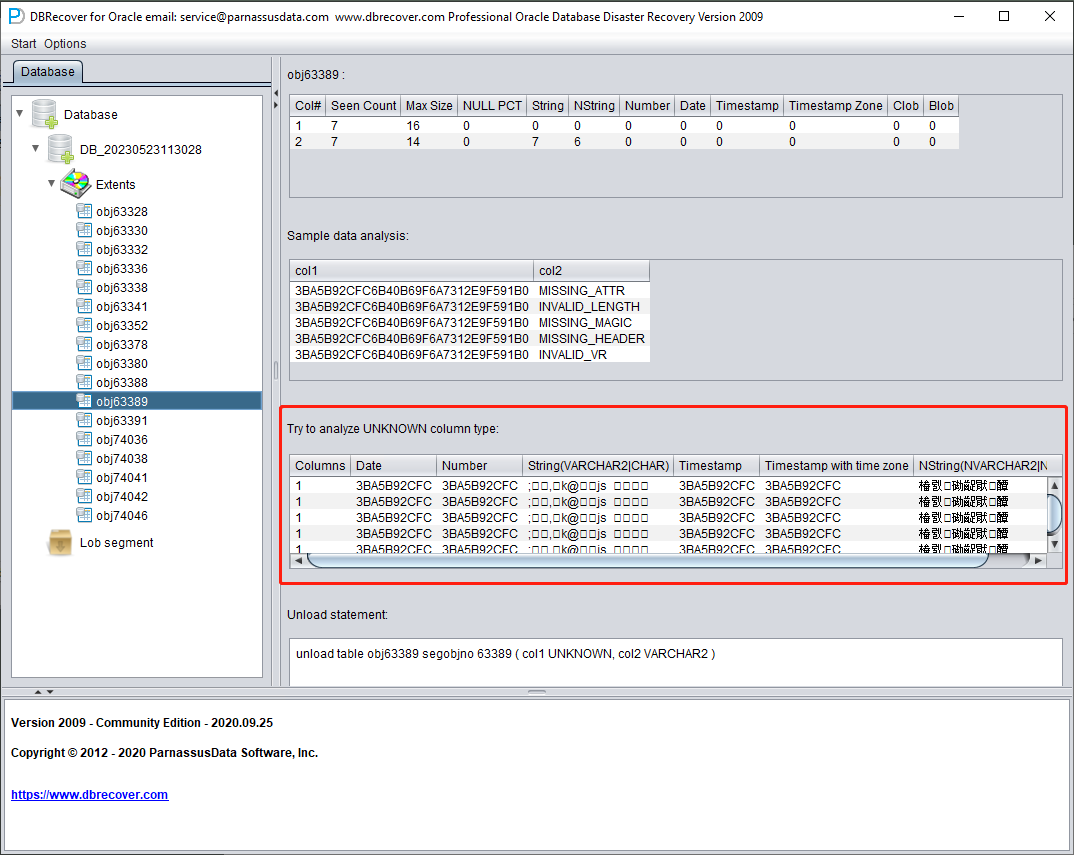
TRY TO ANALYZE UNKNOWN 列类型:
此部分针对的是字段解析功能无法完全确定类型的字段。它会尝试用多种字段类型进行解析并呈现给用户,便于用户判断实际类型。
无法确认类型的字段大致包括以下几种情况:
- RAW 或 LONG RAW
- 不支持的数据类型,包括:XDB.XDB$RAW_LIST_T、XMLTYPE、用户自定义类型等
- 数据块本身严重损坏
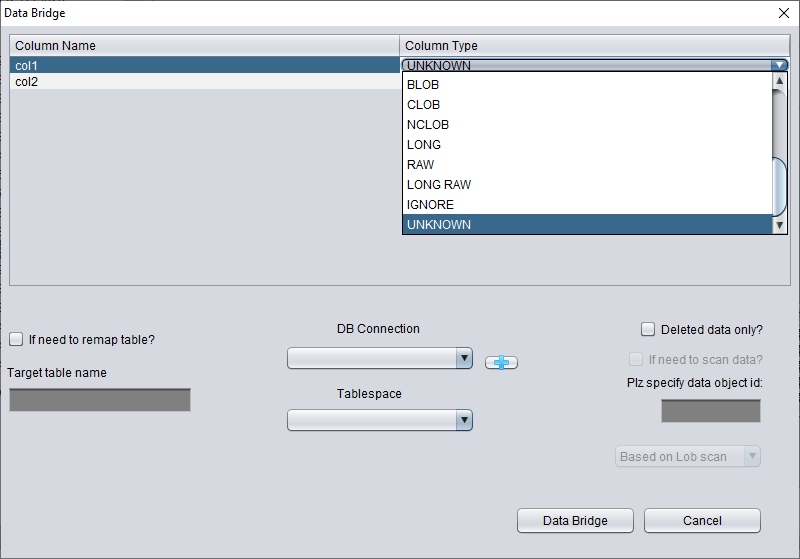
在 "Non-Dictionary Mode" 下,同样可以采用常规模式和 Data Bridge 模式。与字典模式相比,主要区别在于:在非字典模式下进行 Data Bridge 时,用户可以自行决定字段的类型。如下图所示,部分字段类型为 UNKNOWN,即未知。
如果用户了解该表设计时的结构(也可来自应用开发者的文档),可以自行填写正确的 Column Type,以便成功地将表数据 Data Bridge 到目标数据库。
恢复场景 3:勒索软件加密或破坏数据文件
勒索软件会加密 ORACLE 数据文件的部分或全部内容。由于 ORACLE 数据文件通常体积较大,加密整个文件耗时较长,因此部分勒索软件可能只对 ORACLE 数据文件头部的连续或随机空间进行加密。
针对这种局部加密的损坏情况,我们可以尝试使用 DBRECOVER 恢复其中的数据。
由于数据文件头损坏,我们需要通过观察 SYSTEM01.DBF 的内容,推断出每个数据文件的表空间号(TS#)和相对文件号(RFILE#)。
以下是数据文件列表:
O1_MF_APP01_L782YY4Y_.DBF.eking
O1_MF_APP01_L782ZBM3_.DBF.eking
O1_MF_APP01_L782ZCP1_.DBF.eking
O1_MF_APP02_L782ZO7W_.DBF.eking
O1_MF_APP02_L7830DTG_.DBF.eking
O1_MF_APP02_L7830FJ6_.DBF.eking
O1_MF_DBRECOVE_L6G7B1Q3_.DBF.eking
O1_MF_SYSAUX_L5VP5QJ8_.DBF.eking
O1_MF_SYSTEM_L5VP4N7Y_.DBF.eking
O1_MF_TEMP_L5VPCQGO_.TMP.eking
O1_MF_UNDOTBS1_L5VP66PM_.DBF.eking
O1_MF_USERS_L5VP67TJ_.DBF.eking
上面的示例中加密后的后缀是 eking。
注意:TEMP、UNDOTBS1 和 SYSAUX 与本次恢复无关,可以忽略这些文件。
先启动 DBRECOVER,使用 Dictionary mode(DICT-MODE 字典模式)。
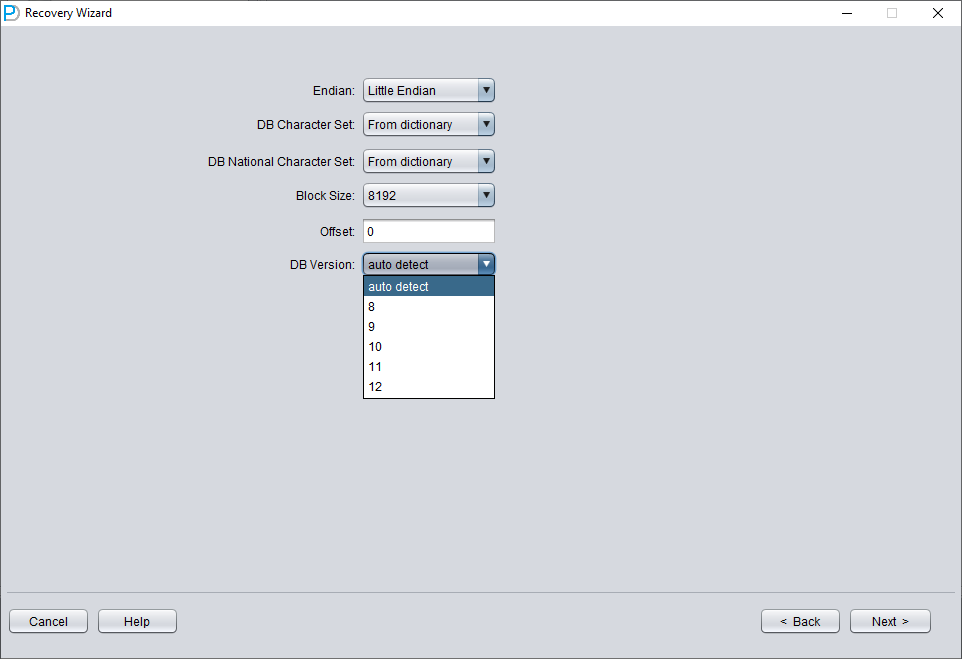
根据实际情况选择 DB VERSION。对于高于 12c 的实例(如 18c、19c 等),选择 12。
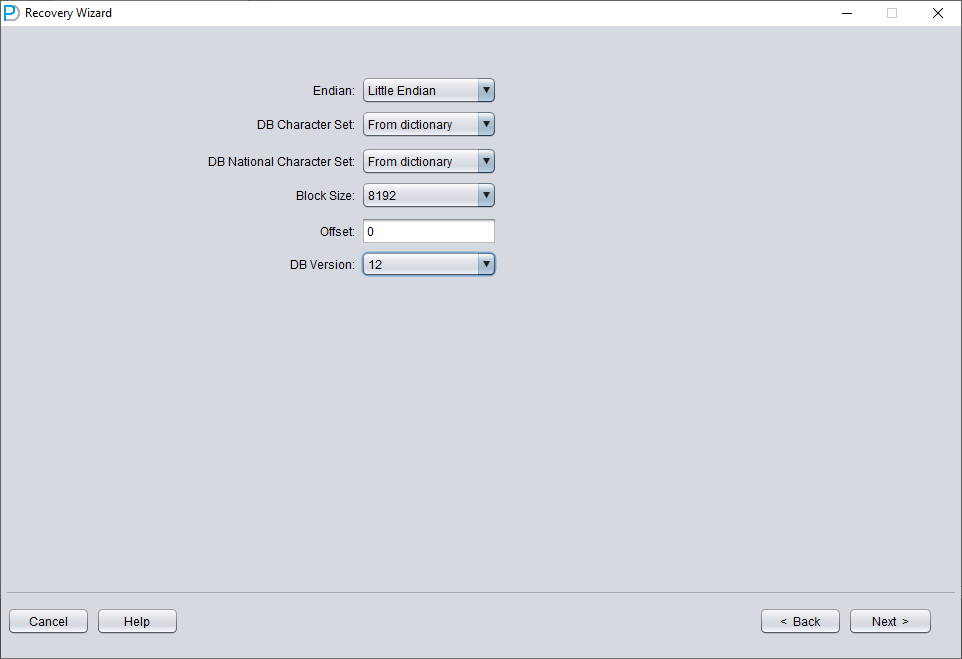
仅添加 SYSTEM01.DBF,并指定其 TS# = 0、rFILE# = 1(注意这是固定值)。
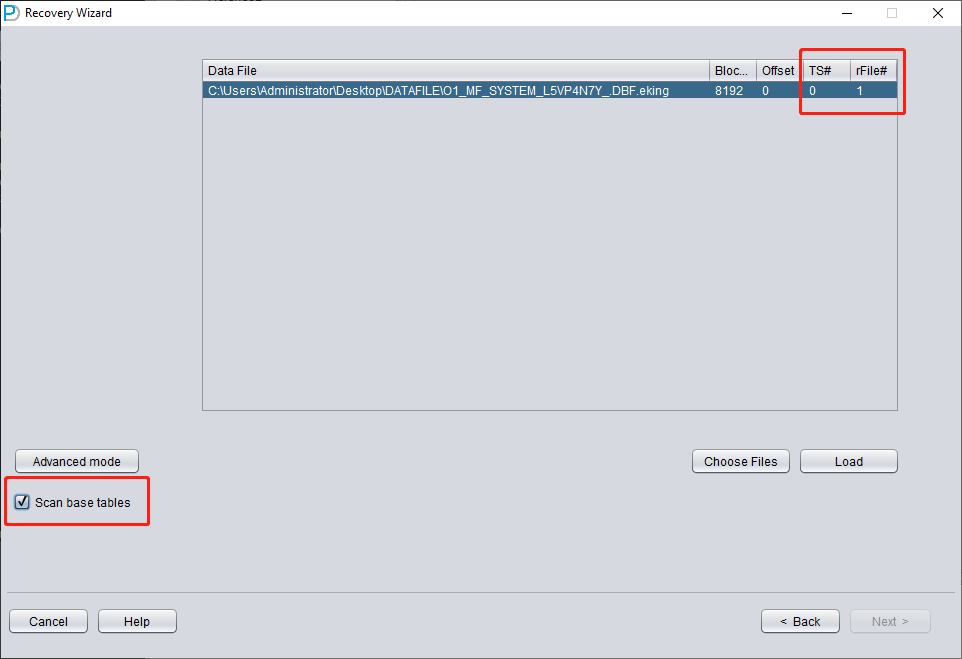
勾选上图中的 "SCAN BASE TABLES" 选项,可以更强力地处理损坏情况。
点击 LOAD 按钮后,DBRECOVER 会整体扫描 SYSTEM01.DBF,并在其中查找数据字典基表数据。
展开 SYS 用户节点,查找 TS$ 和 FILE$ 这两张基表:
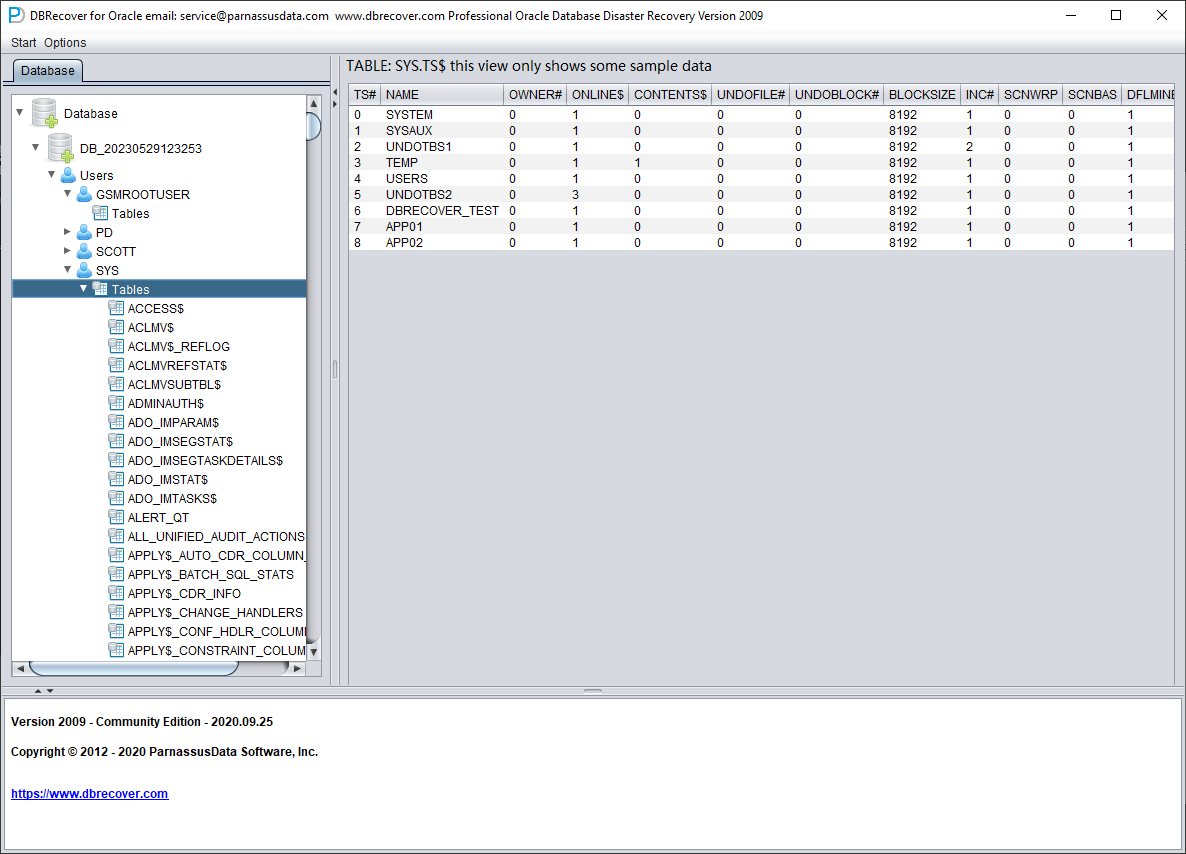
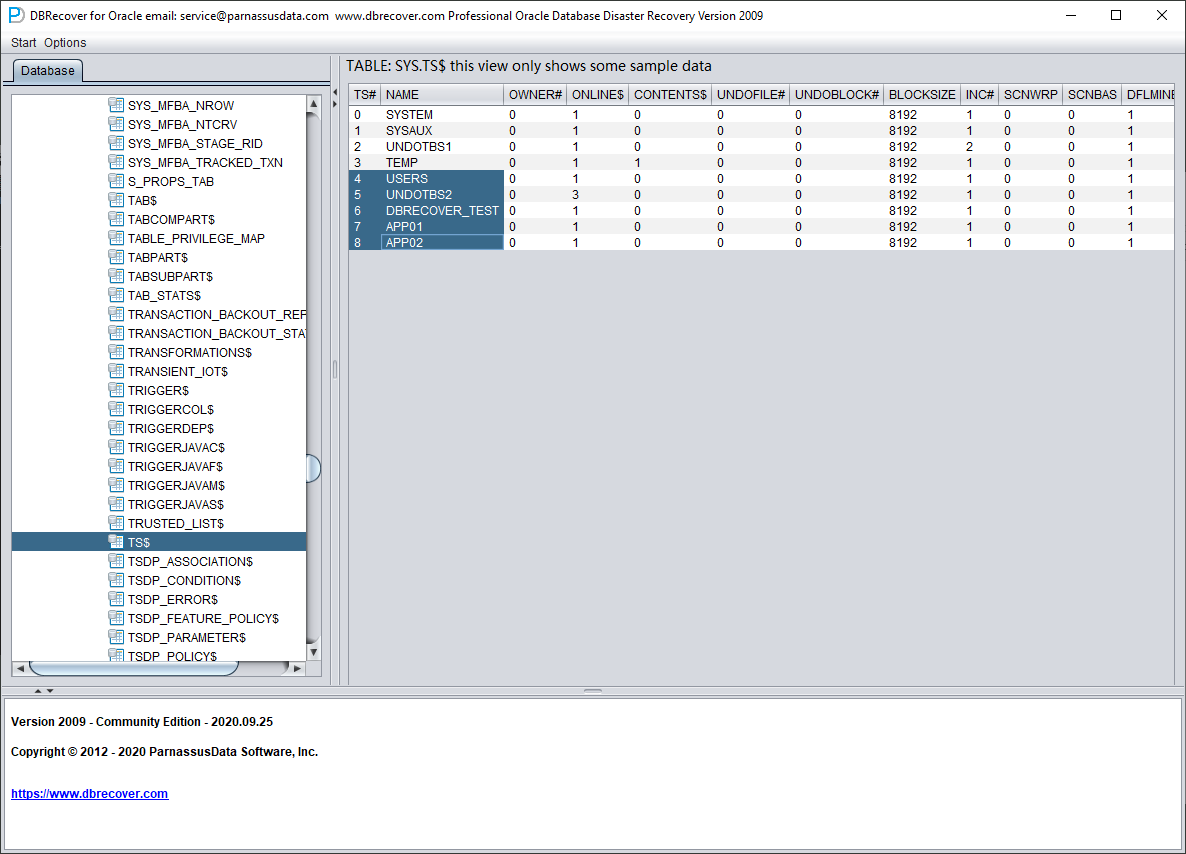
TS$ 表保存表空间信息,TS# 列即表空间号,可以获得如下信息:
| TS# | 名称 |
| 0 | SYSTEM |
| 1 | SYSAUX |
| 2 | UNDOTBS1 |
| 3 | TEMP |
| 4 | USERS |
| 5 | UNDOTBS2 |
| 6 | DBRECOVER_TEST |
| 7 | APP01 |
| 8 | APP02 |
即 APP01 表空间的 TS# 为 7,APP02 表空间的 TS# 为 8。
FILE$ 表保存数据文件信息:
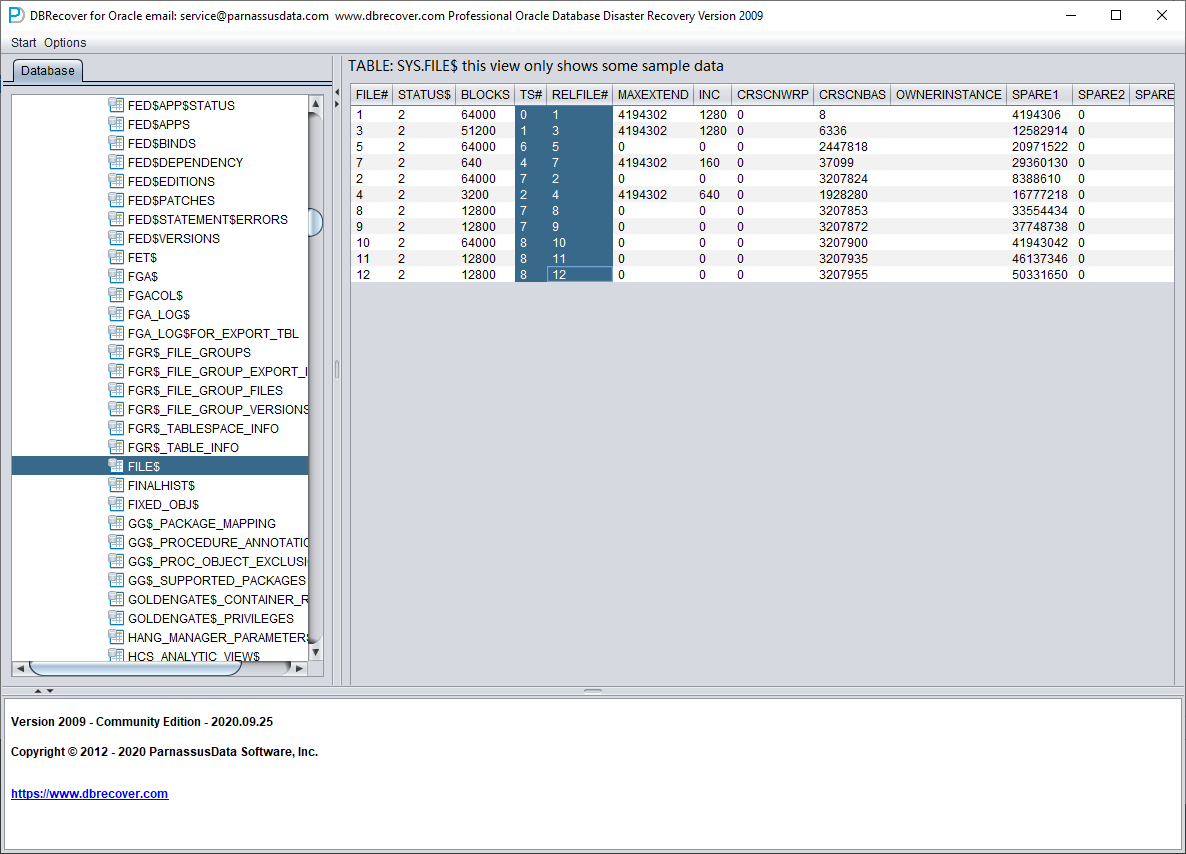
我们需要的是 TS# 和 RELFILE# 列。
| TS# | RELFILE# |
| 0 | 1 |
| 1 | 3 |
| 6 | 5 |
| 4 | 7 |
| 7 | 2 |
| 2 | 4 |
| 7 | 8 |
| 7 | 9 |
| 8 | 10 |
| 8 | 11 |
| 8 | 12 |
通过将两张表的数据进行映射合并,可以得到:
| TS# | RELFILE# | 表空间名称 |
| 0 | 1 | SYSTEM |
| 1 | 3 | SYSAUX |
| 6 | 5 | DBRECOVER_TEST |
| 4 | 7 | USERS |
| 7 | 2 | APP01 |
| 2 | 4 | UNDOTBS1 |
| 7 | 8 | APP01 |
| 7 | 9 | APP01 |
| 8 | 10 | APP02 |
| 8 | 11 | APP02 |
| 8 | 12 | APP02 |
删除不必要的 SYSAUX、UNDOTBS1 以及已知的 SYSTEM 表空间后,只剩下以下内容:
| TS# | RELFILE# | 表空间名称 |
| 6 | 5 | DBRECOVER_TEST |
| 4 | 7 | USERS |
| 7 | 2 | APP01 |
| 7 | 8 | APP01 |
| 7 | 9 | APP01 |
| 8 | 10 | APP02 |
| 8 | 11 | APP02 |
| 8 | 12 | APP02 |
对应的数据文件名列表:
O1_MF_APP01_L782YY4Y_.DBF.eking
O1_MF_APP01_L782ZBM3_.DBF.eking
O1_MF_APP01_L782ZCP1_.DBF.eking
O1_MF_APP02_L782ZO7W_.DBF.eking
O1_MF_APP02_L7830DTG_.DBF.eking
O1_MF_APP02_L7830FJ6_.DBF.eking
O1_MF_DBRECOVE_L6G7B1Q3_.DBF.eking
O1_MF_USERS_L5VP67TJ_.DBF.eking
将两张表配对即可得到文件到表空间的映射关系。对于使用 Oracle Managed Files(OMF,由 db_create_file_dest 控制)的数据库,可以将一个表空间中的多个数据文件按文件名排序,排序顺序即与 RELFILE# 对应。对于使用用户自管理文件名的数据库,现场通常会遵循类似 APP01{XX}(如 APP0101、APP0102)的命名约定,同样可以由文件名推导出该映射。
通过上述推断,我们得到一份完整的信息表:
| TS# | RFILE# | 表空间名称 | 文件名 |
| 6 | 5 | DBRECOVER_TEST | O1_MF_DBRECOVE_L6G7B1Q3_.DBF.eking |
| 4 | 7 | USERS | O1_MF_USERS_L5VP67TJ_.DBF.eking |
| 7 | 2 | APP01 | O1_MF_APP01_L782YY4Y_.DBF.eking |
| 7 | 8 | APP01 | O1_MF_APP01_L782ZBM3_.DBF.eking |
| 7 | 9 | APP01 | O1_MF_APP01_L782ZCP1_.DBF.eking |
| 8 | 10 | APP02 | O1_MF_APP02_L782ZO7W_.DBF.eking |
| 8 | 11 | APP02 | O1_MF_APP02_L7830DTG_.DBF.eking |
| 8 | 12 | APP02 | O1_MF_APP02_L7830FJ6_.DBF.eking |
重新打开 DBRECOVER 并切换到 Dictionary mode(字典模式):
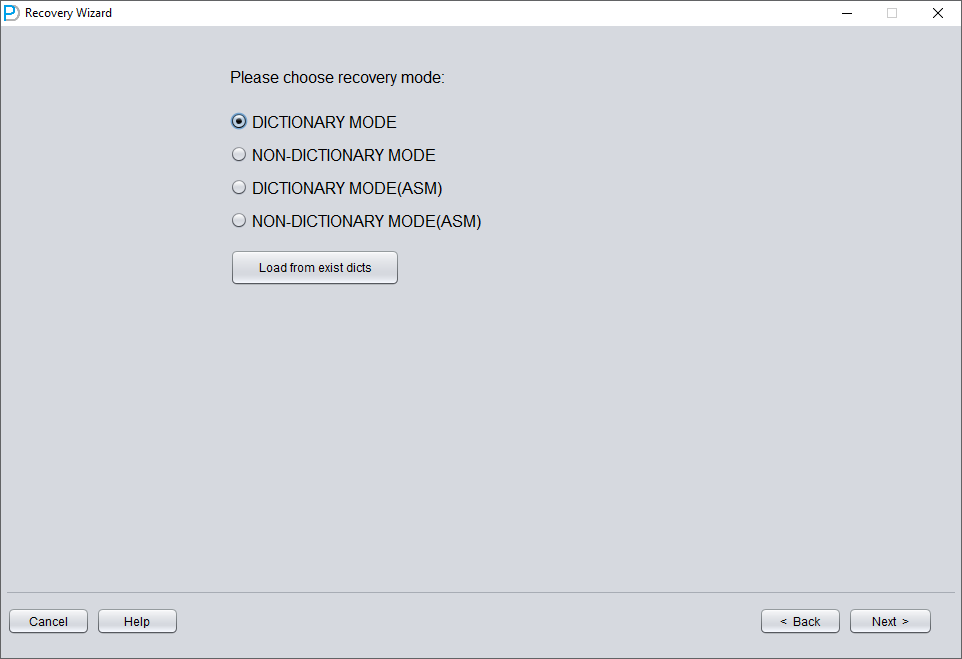
仍然需要选择数据库版本(DB VERSION)。
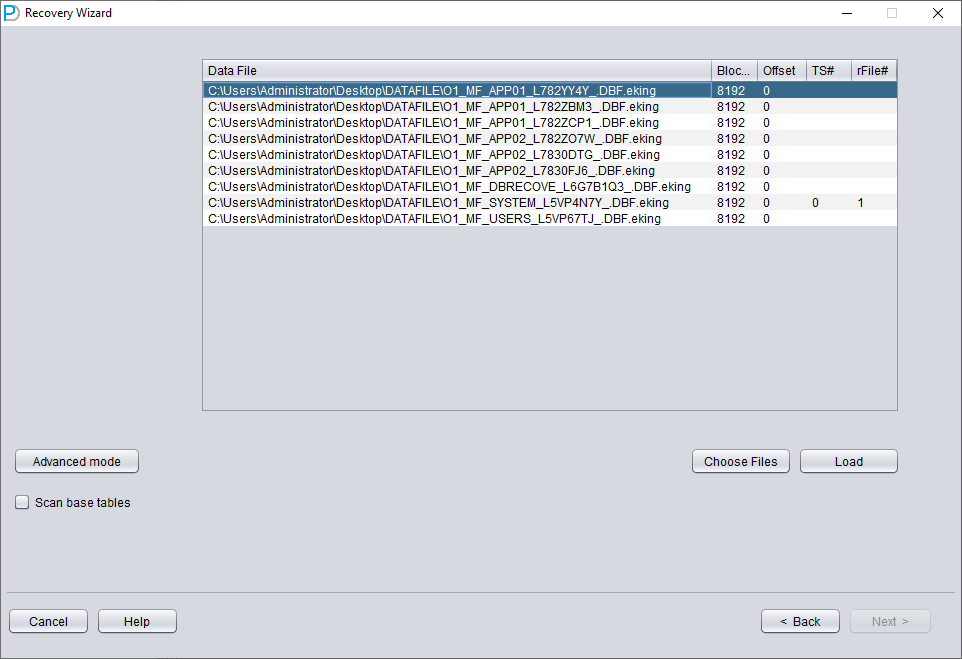
添加所有必要的数据文件(所有可能存放用户数据的文件,UNDOTBS1、TEMP、SYSAUX 无需添加),并确保不要遗漏 SYSTEM01.DBF(必须添加)。
根据前面整理的表格填入 TS# 和 RFILE# 信息:
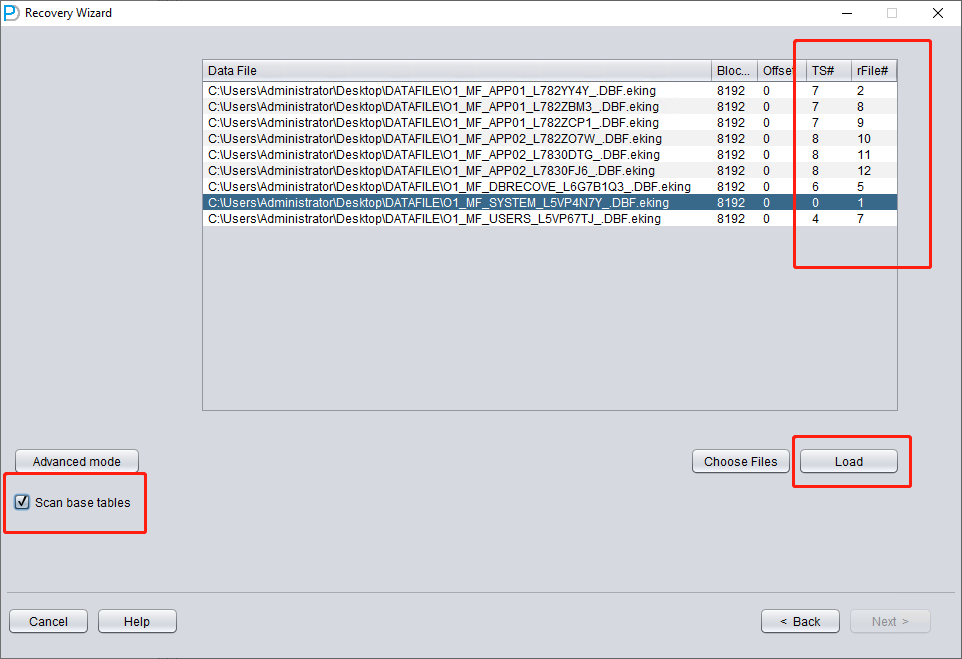
如果所需信息填写正确且加密损坏不严重,可以直接读取数据:
勒索软件的变种各不相同,实际恢复可能需要本文未涉及的额外步骤。如需帮助,请发送邮件至 liu.maclean@gmail.com。
恢复场景 4:恢复被 DELETE FROM TABLE 删除的行
D 公司的某开发人员执行了一个用于测试环境删除数据的脚本,但误连接到生产环境(PROD DATABASE),从而删除了某张表中的全部数据。
在上述场景中,我们可以使用 DBRECOVER 找回被删除的行。
不过用户需要先执行以下操作,尽可能保护数据不被覆盖:
- 将该表所在的表空间设置为 READ ONLY。命令为:ALTER TABLESPACE {TABLESPACE_NAME} READ ONLY
- 关闭数据库实例:SHUTDOWN IMMEDIATE
用户可在以上两种方案中任选其一。
复现该场景:
SQL> select count(*) from pd.emp;
COUNT(*)
---------
114688
SQL> delete from pd.emp;
114688 rows deleted.
SQL> commit;
Commit complete.
SQL> alter system checkpoint;
System altered.
SQL> select count(*) from pd.emp;
COUNT(*)
---------
0
开始恢复前,我们先将表空间设置为只读,以保护恢复环境:
SQL> select tablespace_name from dba_segments where owner='PD' and segment_name='EMP';
TABLESPACE_NAME
-----------------------------
DBRECOVER_TEST
SQL> alter tablespace DBRECOVER_TEST read only;
Tablespace altered.
启动 DBRECOVER,选择 Dictionary mode(字典模式),添加所有可用的数据文件:
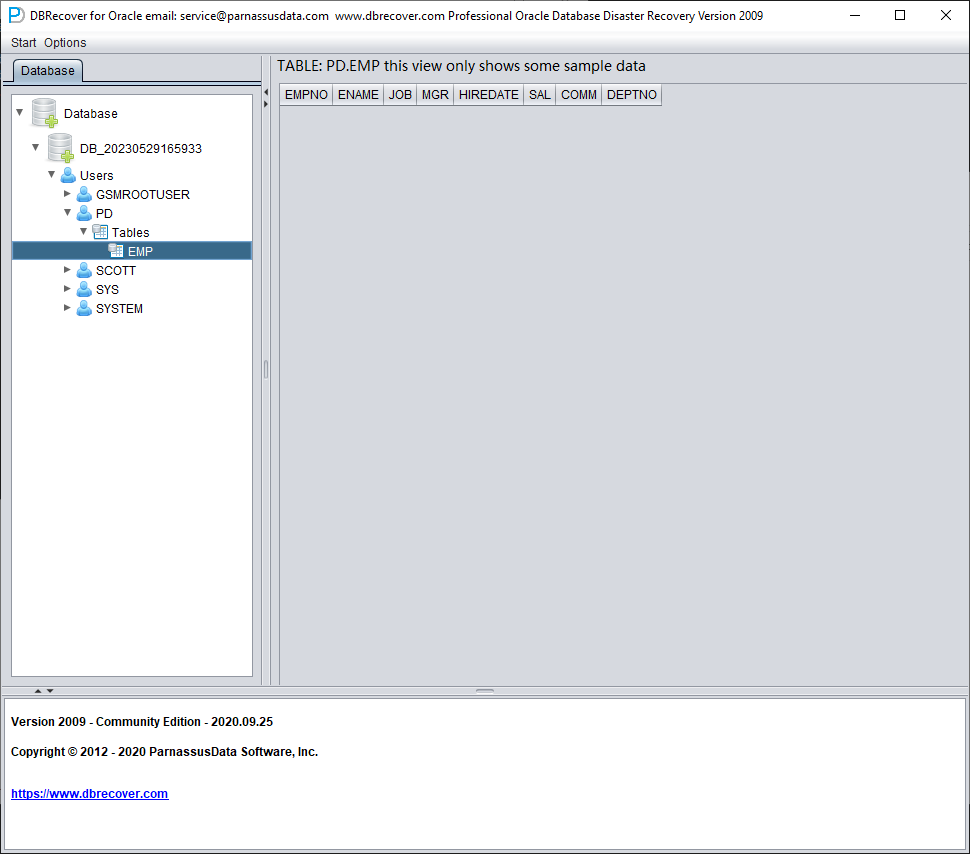
示例表中的数据看起来是空的。右键点击该表并选择 Unload Deleted Data(卸载已删除数据)。
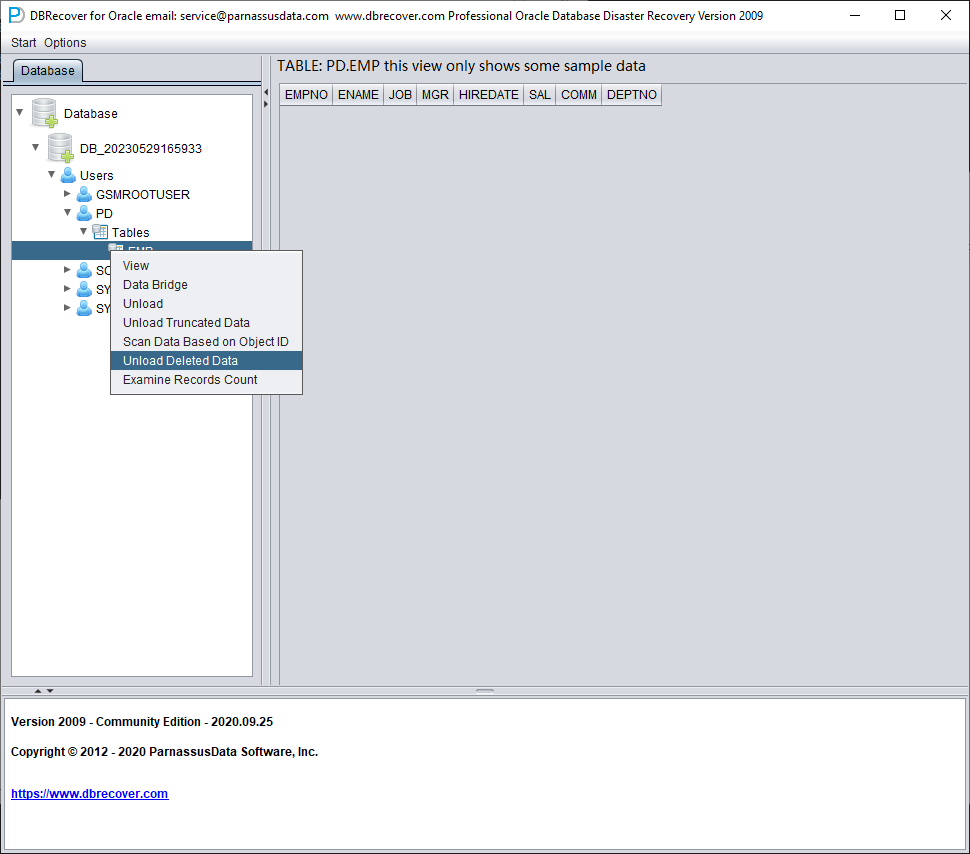
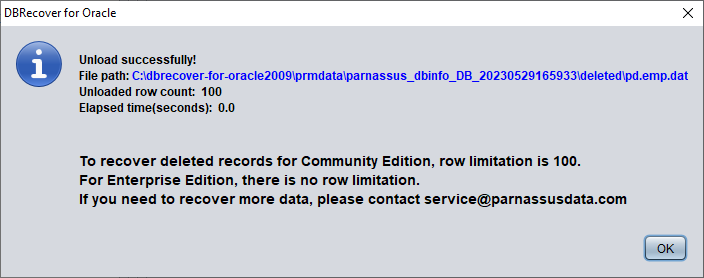
在没有有效企业许可证的情况下,UNLOAD DELETED DATA 功能的限制是每张表 100 行数据。
恢复出的数据存放在弹出窗口所显示的路径中:
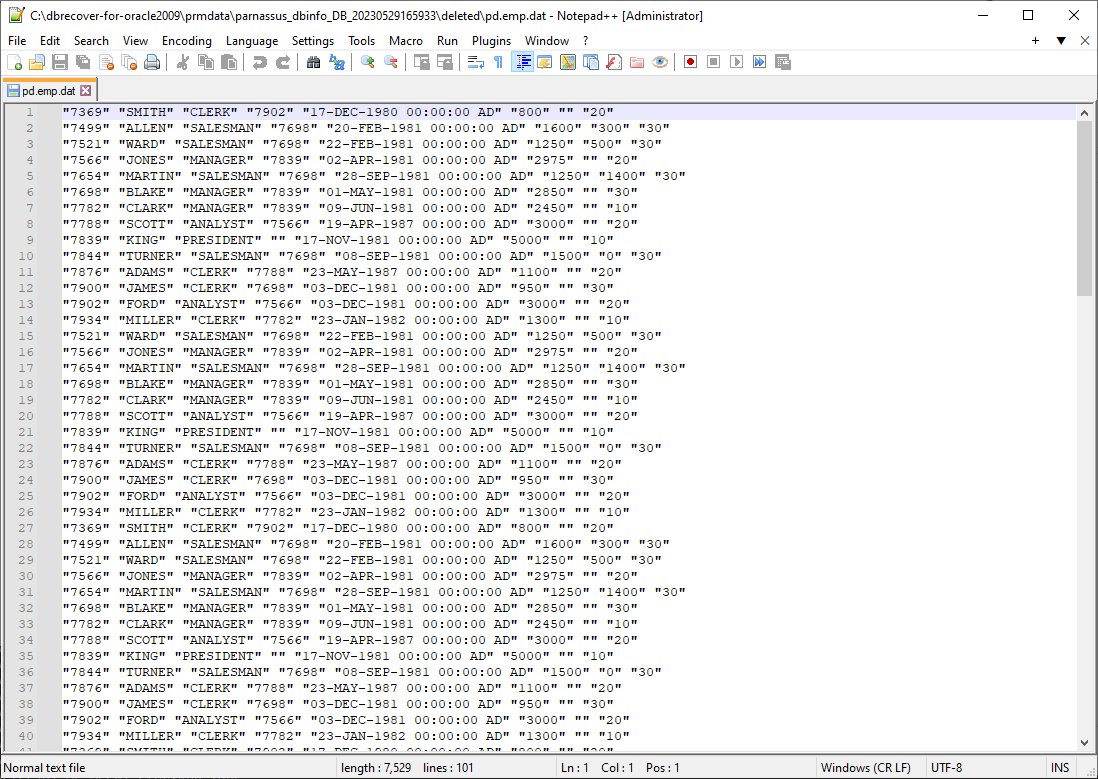
用户需要自行检查恢复结果,并使用 SQLLDR 或 SQLDEVELOPER 等工具将文本数据重新插入数据库。
恢复场景 5:误执行 TRUNCATE TABLE 操作的恢复
D 公司的业务维护人员误将生产数据库当作测试环境数据库,错误地 TRUNCATE 了某张表中的所有数据。DBA 尝试恢复时却发现最近的备份不可用,无法从备份数据中恢复该表的记录。此时 DBA 决定使用 DBRECOVER 来恢复被 TRUNCATE 的数据。
此环境下所有数据库文件均可用且完好。用户只需在 Dictionary mode 下加载 SYSTEM 表空间以及被 TRUNCATE 表所在的数据文件即可。例如:
SQL> select count(*) From pd.salgrade;
COUNT(*)
---------
655360
SQL> select tablespace_name from dba_segments where owner='PD' and segment_name='SALGRADE';
TABLESPACE_NAME
-----------------------------
APP01
SQL> truncate table pd.salgrade;
Table truncated.
SQL> alter system checkpoint;
System altered.
SQL> select count(*) from pd.salgrade;
COUNT(*)
---------
0
本 TRUNCATE 场景未使用 ASM 存储,因此只需选择 "Dictionary Mode":
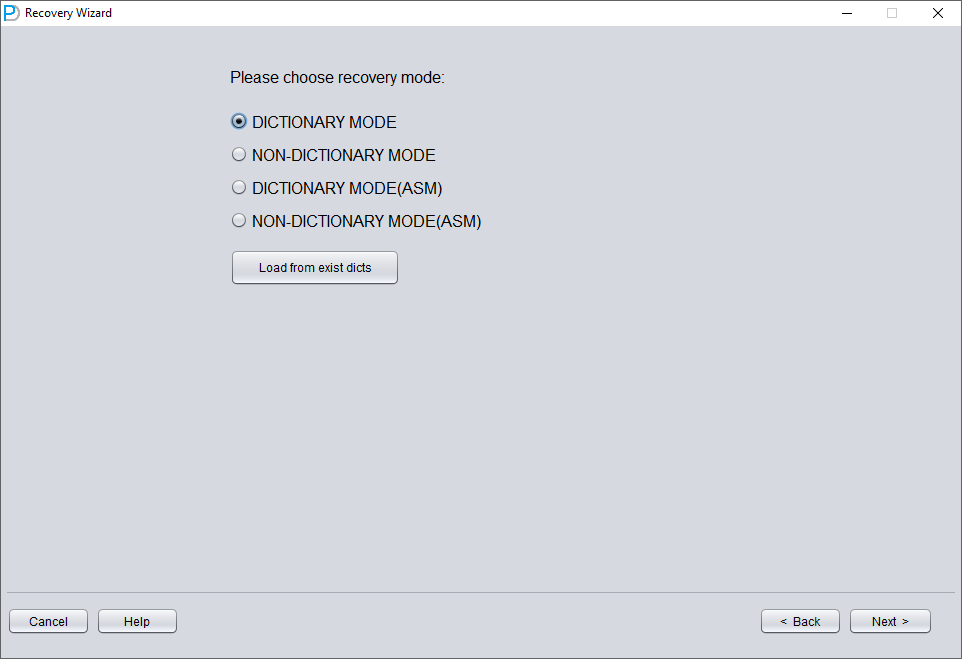
大多数情况下无需修改任何参数:
添加所有可用的数据文件:
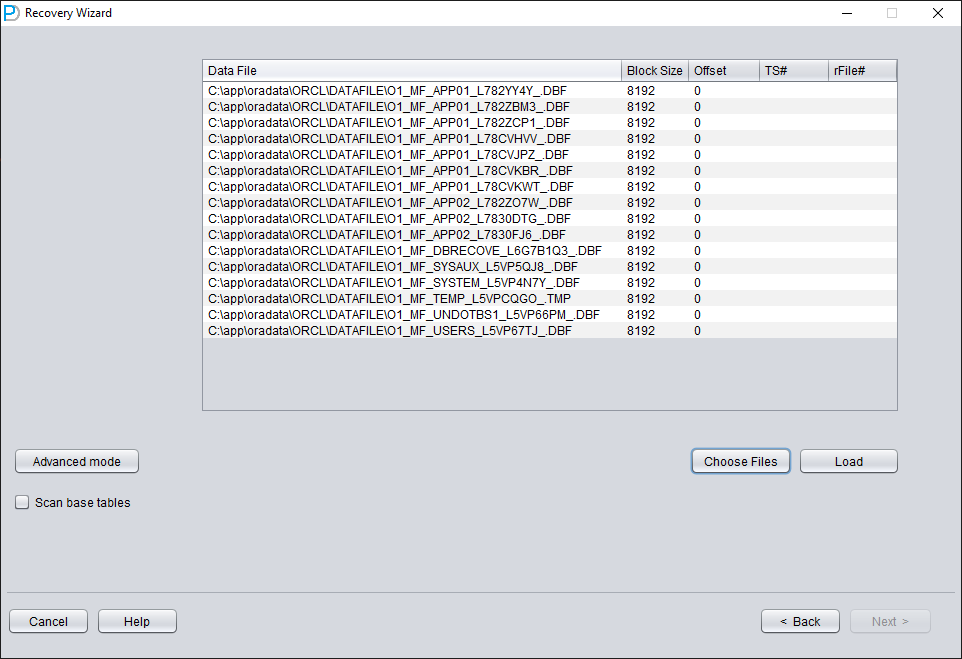
展开 USERS 可以看到多个用户名。如果用户需要恢复 PD SCHEMA 下的某张表,展开 PD 并双击表名:
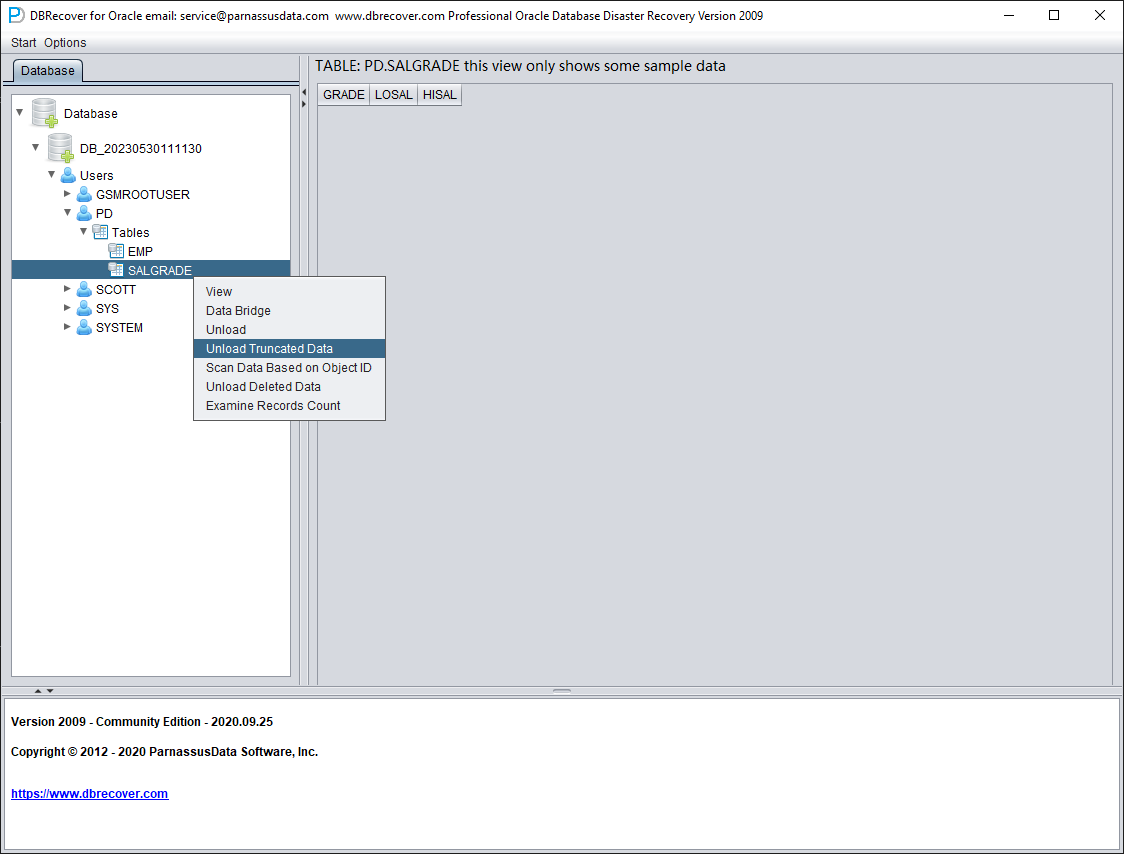
由于该表已被 TRUNCATE,双击后不显示任何数据。此时右键点击表,选择 "Unload truncated data"(卸载被 TRUNCATE 的数据):
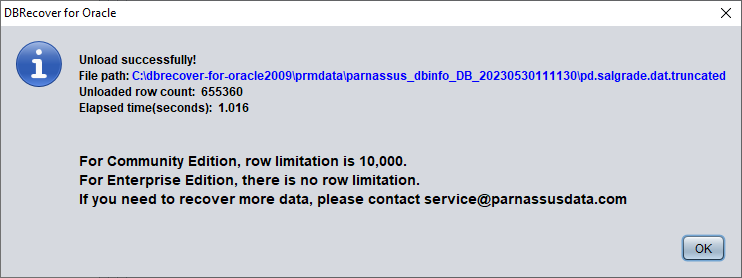
DBRECOVER 会尝试扫描该表所在的表空间并提取被 TRUNCATE 的数据。如上图所示,从被 TRUNCATE 的表中完整提取出 655360 条记录,并存放到指定路径中。
用户可检查 DAT 文件以确认恢复结果。
恢复 TRUNCATE 数据的关键是确认表被 TRUNCATE 之前的 DATA_OBJECT_ID。本例中:
SQL> select object_id ,data_object_id from dba_objects where owner='PD' and object_name='SALGRADE';
OBJECT_ID DATA_OBJECT_ID
--------- --------------
76112 76113
TRUNCATE 之前,表的 OBJECT_ID 和 DATA_OBJECT_ID 都是 76112。TRUNCATE 操作将 DATA_OBJECT_ID 递增到 76113,而 OBJECT_ID 保持不变。
因此本例中原始的 DATA_OBJECT_ID 是 76112。但如果一张表已经被 TRUNCATE 多次,需要恢复更早一次 TRUNCATE 之前的数据,就不能简单地通过当前 OBJECT_ID 推算出原始 DATA_OBJECT_ID。
可以使用闪回查询、数据字典检索、日志挖掘等技术来确定 DATA_OBJECT_ID;以下是闪回查询的示例:
SQL> select user# from sys.user$ where name='PD';
USER#
---------
106
SQL> select obj#,dataobj# from sys.obj$ as of timestamp systimestamp -1/24 where name='SALGRADE' and owner#=106;
OBJ# DATAOBJ#
--------- ----------
76112 76112
通过上述闪回查询可获得原始的 DATAOBJ#,即 DATA_OBJECT_ID。
接下来使用 Data Bridge 功能将恢复出的数据插入目标数据库。
当 Data Bridge 写回源数据库时务必注意:如果 Data Bridge 写入的是被 TRUNCATE 表所在的同一个数据库,目标表空间不能是存放被 TRUNCATE 数据的表空间,目标表也不能是源表。写入源表空间可能覆盖 DBRECOVER 正在读取的残留区段,导致数据无法恢复。(如果桥接到另外一个完全不同的数据库,则不存在该问题。)
因此这里先创建一个新表空间用于存放恢复出的数据表:
SQL> create tablespace pd_recover_data datafile size 600M;
Tablespace created.
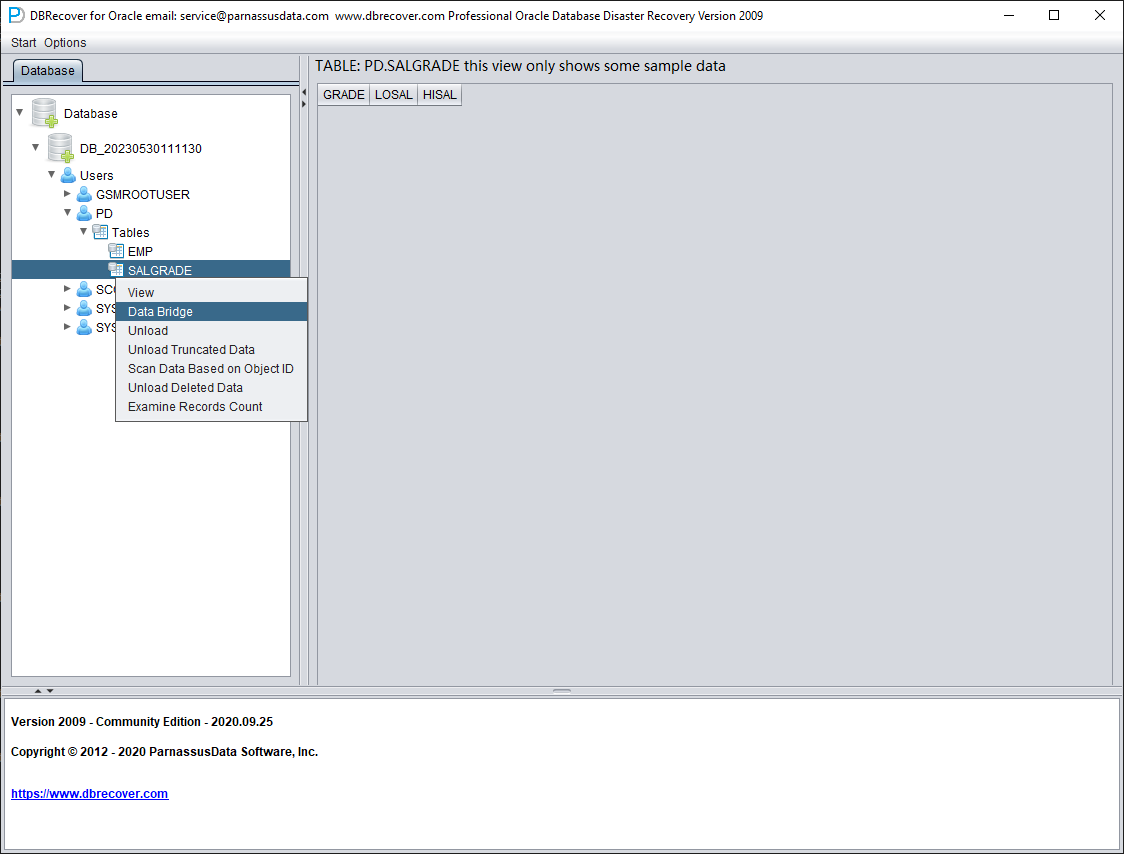
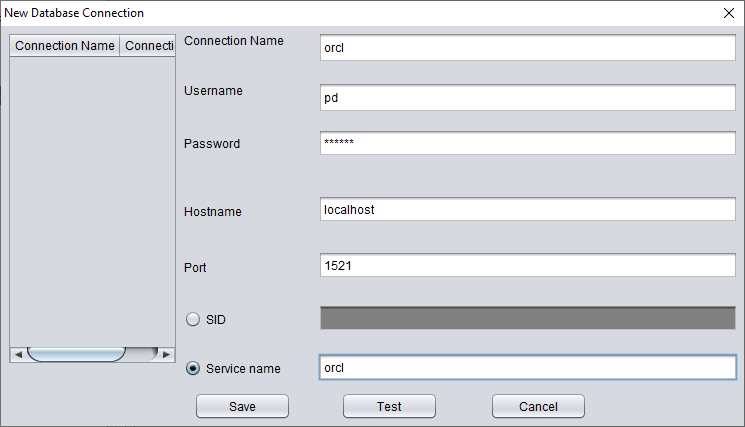
创建必要的登录信息,注意该数据库用户应具备必要权限(建议授予 DBA 角色)。
测试成功后,点击 SAVE 保存。
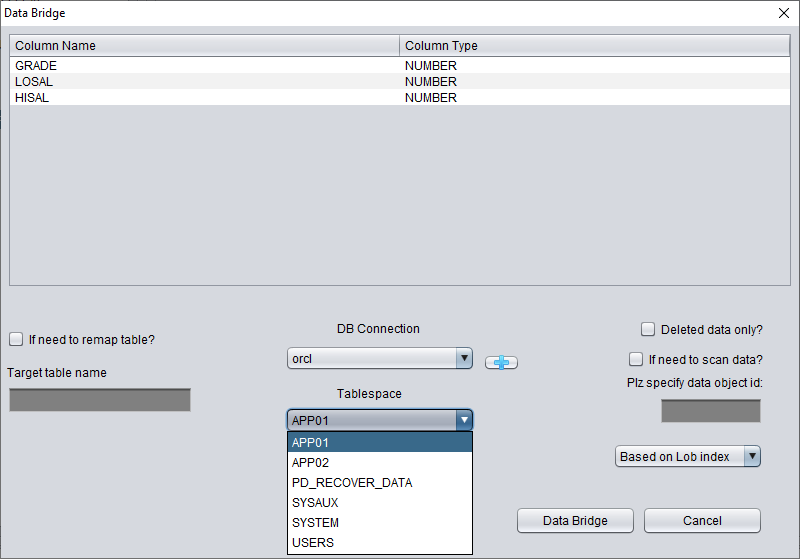
在上图中选择用于存放恢复出的 TRUNCATE 数据表的表空间。
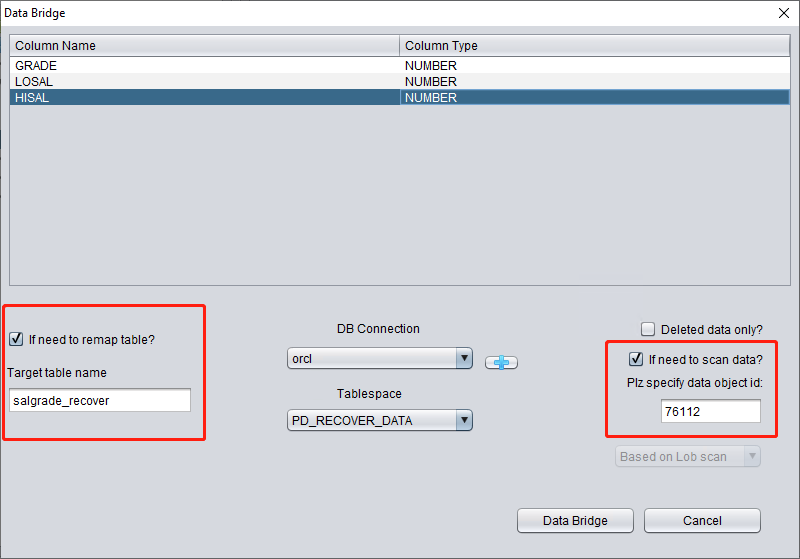
这里需要勾选 "if need to scan data",并填入前面获得的原始 DATA_OBJECT_ID。这样 DBRECOVER 就会专门扫描该 ID 对应的数据。
同时需要勾选 "if need to remap table",并输入新的表名,使数据能够插入到新表(在新表空间下),从而排除任何覆盖数据的可能。
注意:
- 如果对应的表名已经存在于目标实例中,DBRECOVER 不会重建该表,而是在现有表的基础上插入必要的恢复数据。由于表已存在,指定的表空间设置将无效。
- 如果对应的表名不存在于目标数据库 SCHEMA 中,DBRECOVER 会尝试在指定的表空间上建表并插入恢复数据。
完成上述步骤后,点击 Data Bridge 按钮。
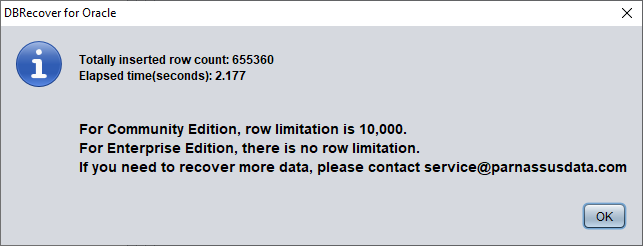
确认恢复的行数:
SQL> select count(*) from pd.salgrade_recover;
COUNT(*)
---------
655360
TRUNCATE 数据的基本原理是:执行 TRUNCATE 时,ORACLE 只更新数据字典和 Segment Header 中表的 Data Object ID,而数据块中实际数据部分并未被修改。由于数据字典和 segment header 中的 DATA_OBJECT_ID 与后续数据块中的不一致,ORACLE 服务进程在读取整张表数据时,不会读取那些已被 TRUNCATE 但实际尚未被覆盖的数据。因此 DBRECOVER 可以通过尚未被修改或覆盖的数据区段(Data Extent)来恢复其中的数据。
恢复场景 6:误执行 DROP TABLE 操作的恢复
D 公司的应用开发人员在没有任何备份的情况下,DROP 了系统中的一张核心应用表。此时可以使用 DBRECOVER 恢复被 DROP 表的大部分数据。从 10g 开始 Oracle 提供了回收站特性,可以先通过 DBA_RECYCLEBIN 视图查询,确认被 DROP 的表是否在回收站中。若在回收站中,优先通过回收站执行 flashback to before drop;若不在回收站中,请立即使用 DBRECOVER 进行恢复。
与 TRUNCATE 恢复类似,DROP 表的恢复也需要确定原始的 DATA_OBJECT_ID。
简要的恢复流程如下:
- 首先使用
ALTER TABLESPACE {TABLESPACE_NAME} READ ONLY将被 DROP 表所在的表空间设为只读模式,或立即复制该表空间下所有数据文件。
- 通过查询数据字典或 LOGMINER 来定位被 DROP 表的 DATA_OBJECT_ID。
- 以 NON-DICT 非字典模式启动 DBRECOVER,添加被 DROP 表所在表空间的所有数据文件,然后执行 SCAN DATABASE + SCAN TABLE from Extent MAP。
- 在展开的对象树形图中通过 DATA_OBJECT_ID 找到对应的表,并以 Data Bridge 模式将其插回源数据库。
可以使用 LogMiner 恢复出近似的 DATA_OBJECT_ID。脚本骨架如下:
EXECUTE DBMS_LOGMNR.ADD_LOGFILE( LOGFILENAME => '/oracle/logs/log1.f', OPTIONS => DBMS_LOGMNR.NEW);
EXECUTE DBMS_LOGMNR.ADD_LOGFILE( LOGFILENAME => '/oracle/logs/log2.f', OPTIONS => DBMS_LOGMNR.ADDFILE);
Execute DBMS_LOGMNR.START_LOGMNR(DBMS_LOGMNR.DICT_FROM_ONLINE_CATALOG+DBMS_LOGMNR.COMMITTED_DATA_ONLY);
SELECT * FROM V$LOGMNR_CONTENTS ;
EXECUTE DBMS_LOGMNR.END_LOGMNR;
也可以通过挖掘 AWR 数据来尝试找出 DATA_OBJECT_ID:
-- Query 1: compare DBA_HIST_SQL_PLAN / GV$SQL_PLAN against OBJ$
Select * from
(select object_name,object# from DBA_HIST_SQL_PLAN
UNION select object_name,object# from GV$SQL_PLAN) V1 where V1.OBJECT# IS
NOT NULL minus select name,obj# from sys.obj$;
-- Query 2: compare WRH$_SEG_STAT_OBJ against OBJ$
select obj#,dataobj#, object_name from WRH$_SEG_STAT_OBJ where object_name
not in (select name from sys.obJ$) order by object_name desc;
-- Query 3: compare DBA_HIST_ACTIVE_SESS_HISTORY against OBJ$
SELECT tab1.SQL_ID,
current_obj#,
tab2.sql_text
FROM DBA_HIST_ACTIVE_SESS_HISTORY tab1,
dba_hist_sqltext tab2
WHERE tab1.current_obj# NOT IN
(SELECT obj# FROM sys.obj$
)
AND current_obj#!=-1
AND tab1.sql_id =tab2.sql_id(+);
// 以上三个查询通过将 AWR 数据与 OBJ$ 字典基表对比来定位被 DROP 的表。
下面进行实际演示:
SQL> create table dropit as select * from dba_objects;
Table created.
SQL> select count(*) from pd.dropit;
COUNT(*)
---------
73095
SQL> select tablespace_name from dba_segments where owner='PD' and segment_name='DROPIT';
TABLESPACE_NAME
-----------------------------
USERS
SQL> select object_id ,data_object_id from dba_objects where owner='PD' and object_name='DROPIT';
OBJECT_ID DATA_OBJECT_ID
--------- --------------
76116 76116
SQL> drop table dropit;
Table dropped.
SQL> alter system checkpoint;
System altered.
在 Dictionary mode(字典模式)下启动 DBRECOVER,这里只需添加 SYSTEM01.DBF 和位于 USERS 表空间中的相应数据文件:
加载完成后,我们会发现 PD SCHEMA 下没有需要恢复的那张表,这是正常的。
选中数据库节点,右键点击 SCAN Data
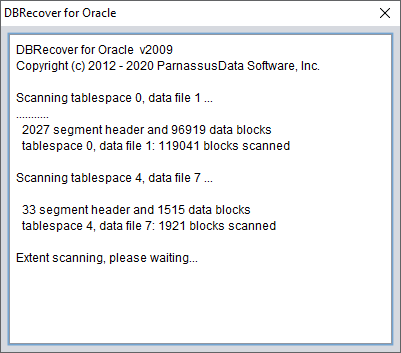
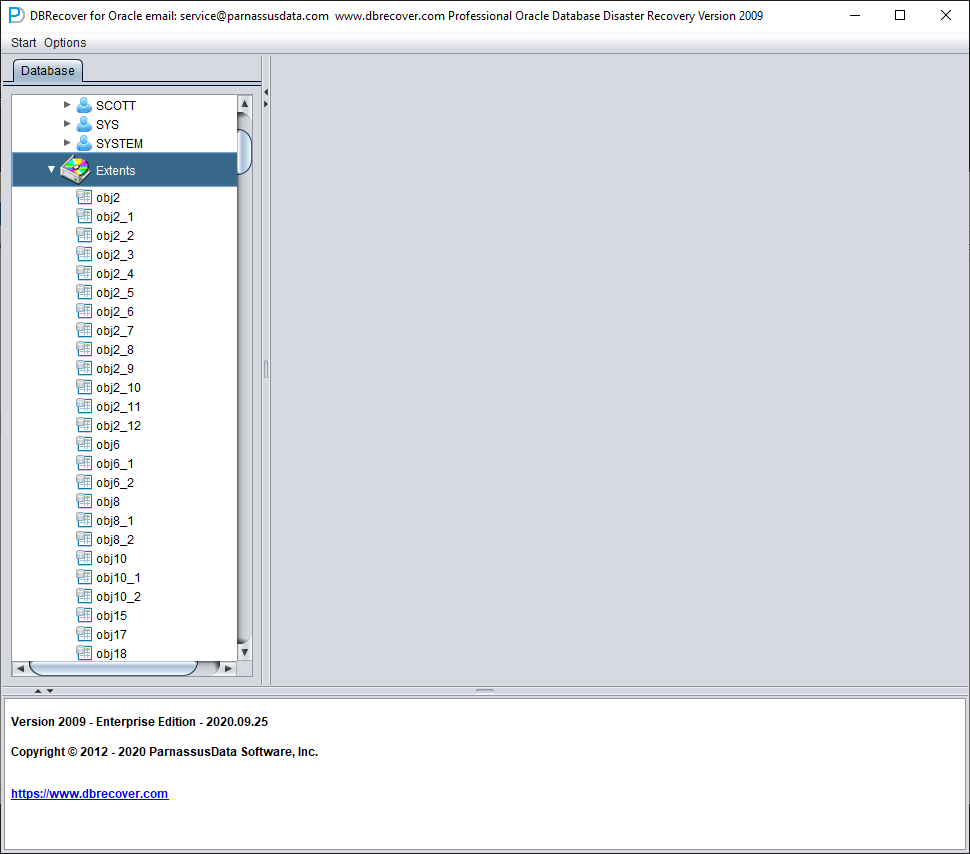
随后会出现一个 EXTENTS 节点,查找 OBJ76116 节点:
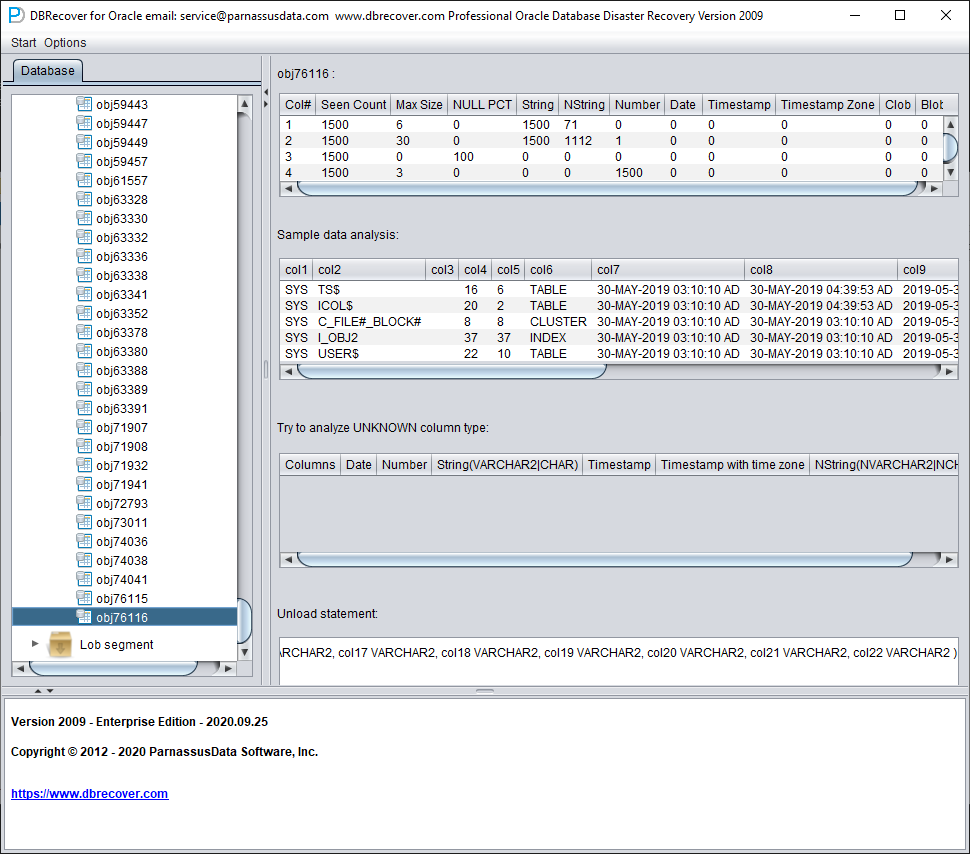
之后即可使用 Data Bridge 功能将其插回源数据库。
恢复场景 7:误执行 DROP TABLESPACE 操作的恢复
D 公司一名员工原本只需通过 DROP TABLESPACE INCLUDING CONTENTS 操作删除一个无用的表空间。然而 DROP TABLESPACE 操作完成后,开发部门反馈被 DROP 的表空间上其实存在某 SCHEMA 的重要数据。现在表空间已被 DROP 且没有备份。
此时可以使用 DBRECOVER 的 Non-Dictionary mode(非字典模式)从被 DROP 表空间对应的所有数据文件中提取数据。使用该方法可以恢复大部分数据。但由于是非字典模式,恢复出的表需要与应用数据表逐一对应。通常需要应用开发和维护人员介入,手动识别哪部分数据属于哪张表。由于 DROP TABLESPACE 操作会修改数据字典并删除 OBJ$ 中对应表空间上的对象,因此无法从 OBJ$ 中获取 DATA_OBJECT_ID 与 OBJECT_NAME 的对应关系。此时可以使用 DROP TABLE 场景中介绍的方法尽量获取 DATA_OBJECT_ID 与 OBJECT_NAME 的对应关系。
总体流程如下:
如果 DROP TABLESPACE 操作时数据文件也被物理删除,则需要先恢复这些数据文件。可尝试使用文件系统级别的恢复软件,或使用 PRMSCAN 软件在 Oracle 数据块级别扫描并重组数据文件。
PRMSCAN 是一款 Oracle 数据块碎片扫描与合并工具,适用于以下场景:
- 在文件系统(任意文件系统:NTFS、FAT、EXT、UFS、JFS 等)或 ASM 上意外手动删除了数据文件。
- 文件系统损坏,数据文件被截断为零字节。
- 文件系统损坏,导致文件系统无法 MOUNT 装载。
- ASM 存储元数据损坏,导致 diskgroup 无法 MOUNT 装载。
- 文件系统或 ASM 的 LV 或 PV 物理损坏或丢失。
- 在上述场景中,prmscan 可以直接扫描文件系统或 ASM 的 PV 和 LV 中尚未被覆盖的残留 Oracle 数据块,实现这些 Oracle 块的合并与重组,从而达到数据恢复的目的。
PRMSCAN 基于 JAVA 语言开发,可以在所有支持 JDK 1.6 及以上的操作系统上跨平台运行,包括 Windows、Linux、Solaris、AIX、HP-UX。
该产品目前不对外零售,可联系我们提供恢复服务。
在下面的示例中,/dev/sdb1 是一个 ext4 分区,存放了一组 Oracle 数据文件。该 ext4 文件系统已损坏,SDB1 无法再挂载,因此 Oracle 数据库也无法使用。
这里我们使用 prmscan 的 Oracle 数据块扫描与合并功能,直接从损坏的文件系统中重组数据文件。
扫描整个磁盘
[oracle@dbdao01 ~]$ java -jar PRMScan.jar –scan /dev/sdb1 –guess 8k
--scan 选项表示扫描 /dev/sdb1 设备,并将 Oracle blocksize 指定为 8k。
[oracle@dbdao01 ~]$ java -jar PRMScan.jar --outputsh ./8kfull.txt--outputsh 选项会输出一个可用于合并扫描信息的 SHELL 文件,本例中文件名为 8kfull.txt。
[oracle@dbdao01 ~]$ sh 8kfull.txt执行 8kfull.txt 后,会在当前目录生成所有需要合并的数据文件。
例如:
[oracle@dbdao01 ~]$ ls -ll PD*
rw-r–r– 1 oracle oinstall 295428096 Jul 28 00:37 PD_DBF1.dbf
rw-r–r– 1 oracle oinstall 83427328 Jul 28 00:37 PD_DBF2.dbf
rw-r–r– 1 oracle oinstall 220266496 Jul 28 00:37 PD_DBF3.dbf
rw-r–r– 1 oracle oinstall 1324482560 Jul 28 00:38 PD_DBF4.dbf
如果数据文件未被物理删除,则可以直接将其添加到 DBRECOVER 中,并在 NON-DICTIONARY MODE 下扫描其中的数据。
后续步骤可参考前面 DROP TABLE 的操作,区别在于 DROP TABLESPACE 的恢复对象会涉及很多表。