Voici le manuel utilisateur officiel de DBRECOVER for Oracle. Utilisez la table des matières à gauche pour accéder à un scénario de récupération précis ; pour une vue d'ensemble complète, lisez le manuel de haut en bas.
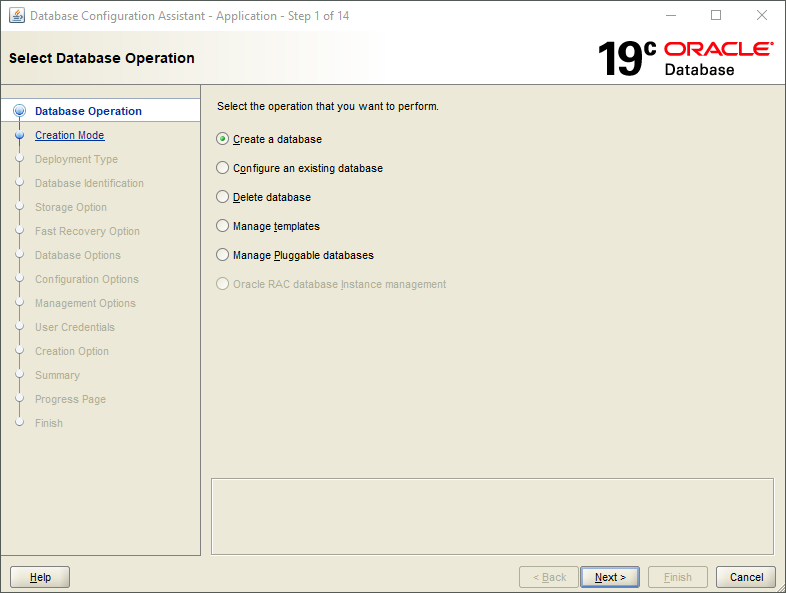
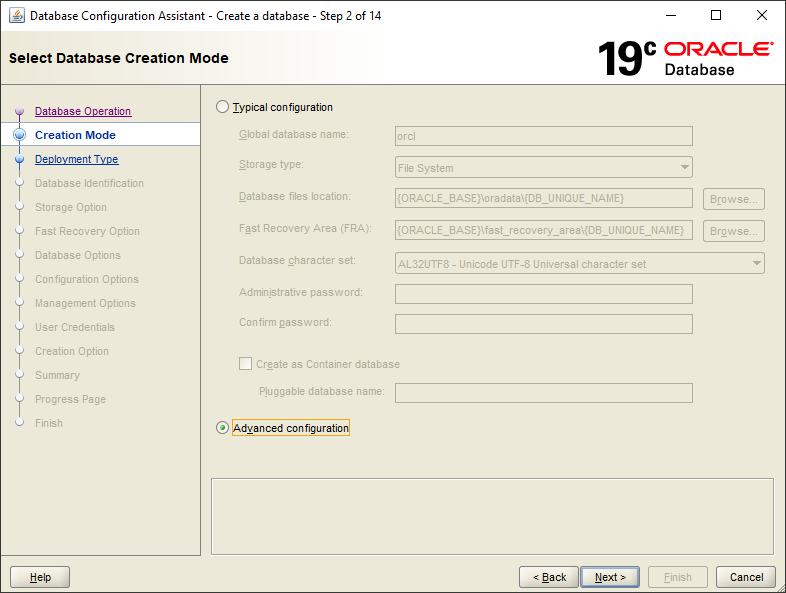
Vue d'ensemble
DBRECOVER for Oracle est un logiciel de reprise après sinistre de qualité professionnelle pour les données Oracle. Il peut extraire et récupérer directement les données à partir des fichiers de données Oracle des bases de données d'Oracle 8i à 21c, sans nécessiter de requêtes SQL via une instance Oracle en cours d'exécution. DBRECOVER repose sur Java, ne requiert aucune installation supplémentaire et peut être utilisé directement après téléchargement et décompression.
DBRECOVER propose une interface graphique intuitive pour une utilisation simple et pratique. Les utilisateurs n'ont pas besoin d'apprendre un ensemble de commandes distinct ni de comprendre les structures de stockage internes d'Oracle ; le Recovery Wizard (assistant de récupération) guide tout le processus.
Pourquoi choisir DBRECOVER ?
Une question fréquente est de savoir si la récupération à partir de sauvegardes Oracle Recovery Manager (RMAN) traditionnelle suffit et pourquoi DBRECOVER est nécessaire. La réponse provient de scénarios de récupération concrets.
Avec la croissance rapide des systèmes informatiques d'entreprise, la capacité des données augmente de manière exponentielle. Les DBA Oracle sont souvent confrontés à des problèmes tels que l'insuffisance du système de stockage sur disque existant pour conserver des sauvegardes complètes, et le temps moyen de réparation requis lors d'une restauration à partir de sauvegardes sur bande, qui dépasse largement les attentes.
« La sauvegarde est primordiale pour les bases de données » est une maxime que chaque DBA garde à l'esprit. Pourtant, la réalité coopère rarement : capacité de sauvegarde insuffisante, équipements de stockage impossibles à se procurer à temps et sauvegardes qui s'avèrent inutilisables au moment de la restauration sont autant de scénarios courants.
Pour résoudre ces dilemmes courants de récupération de données dans le monde réel, le logiciel DBRECOVER tire pleinement parti de sa connaissance de la structure interne des données, du processus de démarrage central et d'autres principes internes des bases Oracle. Il peut gérer les situations où la base ne peut pas s'ouvrir correctement en raison de problèmes tels que la perte du tablespace SYSTEM, des opérations incorrectes sur les tables du dictionnaire de données Oracle ou un dictionnaire de données incohérent causé par des coupures de courant, et ce même en l'absence totale de sauvegarde. Il permet de remédier aux erreurs humaines telles que les troncatures, suppressions ou suppressions (DROP) de tables métier, et de récupérer les données avec moins d'étapes manuelles.
Même un personnel non DBA, qui n'a été exposé aux bases de données Oracle que depuis quelques jours, peut utiliser facilement DBRECOVER. Cela est rendu possible grâce à l'installation simple de DBRECOVER et à son interface utilisateur entièrement graphique. La personne qui réalise la récupération n'a pas besoin d'une expertise approfondie en récupération de bases de données, n'a pas besoin d'apprendre les procédures de récupération en ligne de commande et n'a pas besoin de comprendre la structure de stockage sous-jacente de la base de données. Quelques clics de souris suffisent pour récupérer les données avec moins d'étapes manuelles. DBRECOVER lève la limite selon laquelle seuls quelques professionnels peuvent mener à bien des tâches de récupération de bases de données, raccourcissant considérablement le délai entre la panne et la récupération complète des données, et réduisant le coût total de la récupération de données pour l'entreprise.
Les données récupérables par DBRECOVER peuvent être livrées sous deux formes. La méthode d'extraction traditionnelle extrait les données du fichier de données et les écrit dans un fichier texte plat, lequel est ensuite importé dans la base à l'aide d'outils comme SQLLDR. Cette méthode est simple et intuitive, mais elle requiert un espace équivalent au double de la capacité de données existante : d'une part l'espace occupé par les données texte plat, et d'autre part l'espace nécessaire à l'import de ces données dans la base ; elle prend également deux fois plus de temps, puisque les données originales doivent être extraites du fichier de données avant de pouvoir être importées dans la nouvelle base.
Nous recommandons fortement une autre méthode, à savoir la méthode innovante Data Bridge (pont de données) de DBRECOVER. Cette méthode charge directement les données extraites dans une nouvelle base ou dans une autre base disponible via DBRECOVER, en évitant tout stockage intermédiaire des données. Par rapport à la méthode traditionnelle, elle permet d'économiser efficacement le coût en espace et en temps requis pour la récupération.
La technologie ASM (Automatic Storage Management) d'Oracle est adoptée par un nombre croissant d'entreprises. Par rapport aux systèmes de fichiers traditionnels, les bases utilisant le stockage ASM offrent de hautes performances, prennent en charge les clusters et facilitent l'administration. Toutefois, le problème d'ASM tient à la complexité de sa structure de stockage, difficile à comprendre pour les utilisateurs ordinaires. Dès lors que la structure interne d'un Disk Group ASM est endommagée et ne peut plus être MOUNT correctement, les données importantes de l'utilisateur se retrouvent « verrouillées » dans cette « boîte noire » ASM. Dans ce cas, il faut généralement faire intervenir des ingénieurs Oracle expérimentés, familiers avec la structure interne d'ASM, sur le site du client afin de réparer manuellement la structure interne d'ASM ; et l'achat de prestations sur site Oracle s'avère souvent à la fois coûteux et long pour les utilisateurs ordinaires.
Les développeurs de DBRECOVER ayant une connaissance approfondie de la structure interne d'Oracle ASM, DBRECOVER a intégré une fonction de récupération de données spécifiquement dédiée à ASM.
À ce jour, les fonctions de récupération de données ASM prises en charge par DBRECOVER comprennent :
Même lorsque le Disk Group ne peut pas être MOUNT correctement, DBRECOVER peut lire directement les métadonnées disponibles sur le disque ASM et copier les fichiers ASM contenus dans le Disk Group à partir de ces métadonnées.
Même lorsque le Disk Group ne peut pas être MOUNT correctement, DBRECOVER peut lire directement les fichiers de données présents sur ASM et en extraire les données, en prenant en charge à la fois les méthodes d'extraction traditionnelles et la méthode Data Bridge.
Présentation de DBRECOVER for Oracle
DBRECOVER for Oracle est développé en JAVA, ce qui garantit son exécution multi-plateforme, qu'il s'agisse de plateformes Unix telles qu'AIX, Solaris ou HP-UX, de plateformes Linux comme Red Hat, Oracle Linux ou SUSE, ou encore de la plateforme Windows.
Plateformes de systèmes d'exploitation prises en charge par DBRECOVER :
| Nom de la plateforme | Pris en charge |
| Windows | OUI |
| AIX | OUI |
| Solaris Sparc/X86 | OUI |
| Linux x86/64 | OUI |
| HPUX | OUI |
| MacOS | OUI |
Versions de base de données actuellement prises en charge par DBRECOVER : 8i ~ 21C
DBRECOVER est livré avec l'environnement JAVA nécessaire à son exécution, il n'est donc pas nécessaire d'installer séparément JAVA sous Windows/Linux.
Sous Windows, double-cliquez pour exécuter start_dbrecover_windows_local_java.bat
Sous Linux, exécutez : sh start_dbrecover_linux_local_java.sh
Pour les environnements de type UNIX tels qu'AIX/HP-UX/Solaris, l'utilisateur doit installer lui-même l'environnement JAVA 8.
Jeux de caractères de base de données pris en charge par DBRECOVER :
| Langue | Caractère | Codage |
| Chinois | ZHS16GBK | GBK |
| Chinois | ZHS16DBCS | CP935 |
| Chinois | ZHT16BIG5 | BIG5 |
| Chinois | ZHT16DBCS | CP937 |
| Chinois | ZHT16HKSCS | CP950 |
| Chinois | ZHS16CGB231280 | GB2312 |
| Chinois | ZHS32GB18030 | GB18030 |
| Japonais | JA16SJIS | SJIS |
| Japonais | JA16EUC | EUC_JP |
| Japonais | JA16DBCS | CP939 |
| Coréen | KO16MSWIN949 | MS649 |
| Coréen | KO16KSC5601 | EUC_KR |
| Coréen | KO16DBCS | CP933 |
| Français | WE8MSWIN1252 | CP1252 |
| Français | WE8ISO8859P15 | ISO8859_15 |
| Français | WE8PC850 | CP850 |
| Français | WE8EBCDIC1148 | CP1148 |
| Français | WE8ISO8859P1 | ISO8859_1 |
| Français | WE8PC863 | CP863 |
| Français | WE8EBCDIC1047 | CP1047 |
| Français | WE8EBCDIC1147 | CP1147 |
| Allemand | WE8MSWIN1252 | CP1252 |
| Allemand | WE8ISO8859P15 | ISO8859_15 |
| Allemand | WE8PC850 | CP850 |
| Allemand | WE8EBCDIC1141 | CP1141 |
| Allemand | WE8ISO8859P1 | ISO8859_1 |
| Allemand | WE8EBCDIC1148 | CP1148 |
| Italien | WE8MSWIN1252 | CP1252 |
| Italien | WE8ISO8859P15 | ISO8859_15 |
| Italien | WE8PC850 | CP850 |
| Italien | WE8EBCDIC1144 | CP1144 |
| Thaï | TH8TISASCII | CP874 |
| Thaï | TH8TISEBCDIC | TIS620 |
| Arabe | AR8MSWIN1256 | CP1256 |
| Arabe | AR8ISO8859P6 | ISO8859_6 |
| Arabe | AR8ADOS720 | CP864 |
| Espagnol | WE8MSWIN1252 | CP1252 |
| Espagnol | WE8ISO8859P1 | ISO8859_1 |
| Espagnol | WE8PC850 | CP850 |
| Espagnol | WE8EBCDIC1047 | CP1047 |
| Portugais | WE8MSWIN1252 | CP1252 |
| Portugais | WE8ISO8859P1 | ISO8859_1 |
| Portugais | WE8PC850 | CP850 |
| Portugais | WE8EBCDIC1047 | CP1047 |
| Portugais | WE8ISO8859P15 | ISO8859_15 |
| Portugais | WE8PC860 | CP860 |
Types de stockage de tables pris en charge par DBRECOVER :
| Type de stockage de table | Pris en charge |
| Table en cluster | OUI |
| Table organisée par index, partitionnée ou non | NON |
| Table organisée en tas (heap), partitionnée ou non | OUI |
| Table organisée en tas avec Basic Compression | NON |
| Table organisée en tas avec Advanced Compression | NON |
| Table organisée en tas avec Hybrid Columnar Compression | NON |
| Table organisée en tas avec chiffrement | NON |
| Table avec colonnes virtuelles | NON |
| Lignes chaînées, lignes migrées | OUI |
Remarque : pour les colonnes virtuelles et les colonnes par défaut optimisées en 11g, l'extraction des données s'effectue généralement sans erreur, mais les champs correspondants sont perdus. Ces deux fonctionnalités sont postérieures à 11g et peu utilisées.
Types de données de colonnes pris en charge par DBRECOVER :
| Type de données | Pris en charge |
| BFILE | Non |
| Binary XML | Non |
| BINARY_DOUBLE | Oui |
| BINARY_FLOAT | Oui |
| BLOB | Oui |
| CHAR | Oui |
| CLOB et NCLOB | Oui |
| Collections (y compris VARRAYS et tables imbriquées) | Non |
| Date | Oui |
| INTERVAL DAY TO SECOND | Oui |
| INTERVAL YEAR TO MONTH | Oui |
| LOB stockés en SecureFiles | Oui |
| LONG | Oui |
| LONG RAW | Oui |
| Types de données multimédias (Spatial, Image et Oracle Text inclus) | Non |
| NCHAR | Oui |
| Number | Oui |
| NVARCHAR2 | Oui |
| RAW | Oui |
| ROWID, UROWID | Oui |
| TIMESTAMP | Oui |
| TIMESTAMP WITH LOCAL TIMEZONE | Oui |
| TIMESTAMP WITH TIMEZONE | Oui |
| Types définis par l'utilisateur | Non |
| VARCHAR2 et VARCHAR | Oui |
| XMLType stocké en CLOB | Non |
| XMLType stocké en Object Relational | Non |
Prise en charge d'ASM par DBRECOVER :
| Fonction | Pris en charge |
| Prend en charge l'extraction directe des données depuis ASM, sans avoir à copier sur le système de fichiers | OUI |
| Prend en charge la copie des fichiers de données depuis ASM | OUI |
Installation et démarrage de DBRECOVER
DBRECOVER est un logiciel portable basé sur Java et ne nécessite pas de processus d'installation distinct. Les utilisateurs peuvent l'utiliser pour récupérer des données dès qu'ils ont décompressé l'archive ZIP téléchargée.
Pour démarrer DBRECOVER :
- Sous Windows : double-cliquez pour exécuter
start_dbrecover_windows_local_java.bat
- Sous Linux : vous pouvez utiliser le logiciel sur votre machine locale avec une interface graphique, ou recourir à des outils graphiques distants tels que Xmanager ou VNC. Avant d'exécuter le logiciel, assurez-vous de pouvoir ouvrir l'application d'horloge graphique
xclock. Puis, dans le répertoire où le logiciel a été décompressé, exécutez :sh start_dbrecover_linux_local_java.sh
Pour les environnements AIX/HP-UX/Solaris, DBRECOVER peut être utilisé sur une machine locale dotée d'une interface graphique ou via des outils graphiques distants comme Xmanager ou VNC. Voici les étapes pour démarrer DBRECOVER :
- Vérifiez que l'environnement Java 8 correspondant à la plateforme est bien installé. Vous pouvez utiliser la commande
java -versionpour le confirmer.
- Vérifiez que vous pouvez ouvrir l'application d'horloge graphique
xclock.
- Dans le répertoire où le logiciel a été décompressé, exécutez :
sh start_dbrecover.sh
Enregistrer la licence DBRECOVER
DBRECOVER for Oracle est un logiciel commercial. Une édition communautaire de DBRECOVER est mise à disposition pour permettre aux utilisateurs de le tester et de l'apprendre.
À ce jour, un seul type de licence est proposé : la licence entreprise. Consultez la page tarifaire DBRECOVER for Oracle pour les informations d'achat.
Après avoir obtenu la clé de licence, les utilisateurs peuvent l'enregistrer eux-mêmes dans le logiciel. La marche à suivre est la suivante :
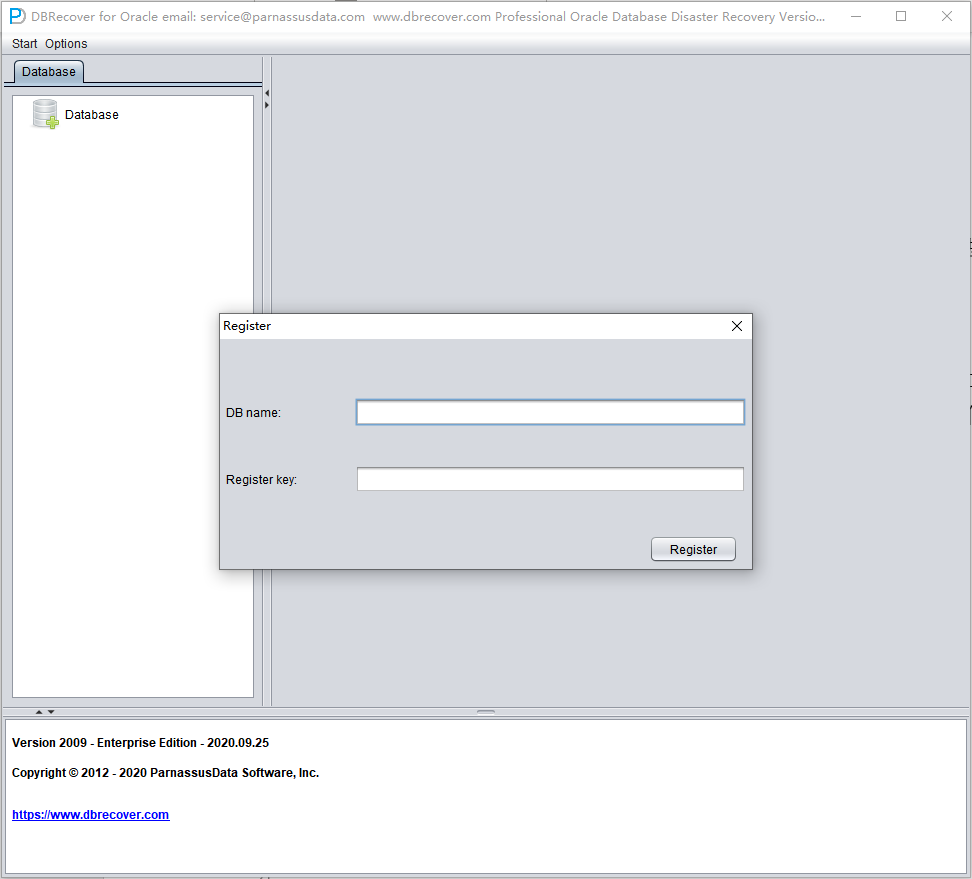
Pour enregistrer votre licence DBRECOVER, suivez ces étapes :
- Dans la barre de menu, cliquez sur « Help » puis sélectionnez « Register ».
- À l'aide des informations transmises après votre achat, saisissez votre DB NAME et votre clé, puis cliquez sur le bouton « Register ».
- Une fois l'enregistrement terminé, à chaque redémarrage de DBRECOVER, le logiciel vérifiera automatiquement les informations d'enregistrement de la licence : vous n'avez donc pas besoin de les saisir de nouveau.
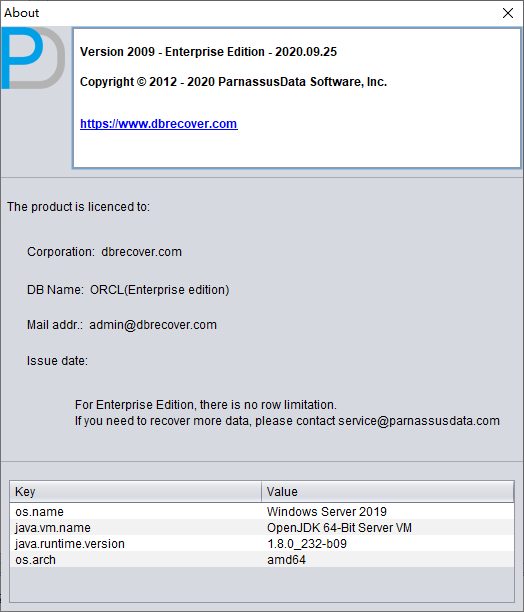
Vous pouvez consulter les informations d'enregistrement réussi via « Help » => « About ».
Utiliser DBRECOVER dans les scénarios de récupération Oracle
Scénario de récupération 1 : Corruption d'un fichier de données Oracle empêchant l'ouverture de la base
La base de production de l'entreprise A fonctionne toute l'année en mode non-archive, en réalisant occasionnellement des sauvegardes logiques EXP, mais jamais de sauvegardes physiques. Un jour, après une coupure de courant du serveur et un redémarrage, la base ne peut plus s'ouvrir normalement. À l'inspection, on constate que le tablespace SYSTEM est gravement endommagé. À ce stade, DBRECOVER peut être utilisé pour transférer rapidement les données de la base endommagée vers une base nouvellement créée, et ainsi rétablir rapidement l'activité.
Dans des scénarios similaires, si vous rencontrez des erreurs telles que ORA-01194, ORA-01110, ORA-01033, ORA-01115, ORA-00368, ORA-00600 kcbzib_kcrsds_1, ORA-00333, ORA-01113, ORA-01122, ORA-27027, etc., qui empêchent l'ouverture de la base, vous pouvez tenter de récupérer les données à l'aide des méthodes employées dans ce scénario.
Les grandes étapes sont les suivantes :
- Utilisez dbca pour créer une nouvelle base ORACLE, en veillant à ce que le jeu de caractères corresponde à celui de la base endommagée
- Créez les utilisateurs et tablespaces correspondants dans la nouvelle base ; il est recommandé d'octroyer temporairement le rôle DBA à ces utilisateurs
- Démarrez le listener (LISTENER) en vous assurant que le service de base est enregistré auprès de celui-ci
- Démarrez DBRECOVER en mode dictionnaire et chargez tous les fichiers de données de la base endommagée d'origine
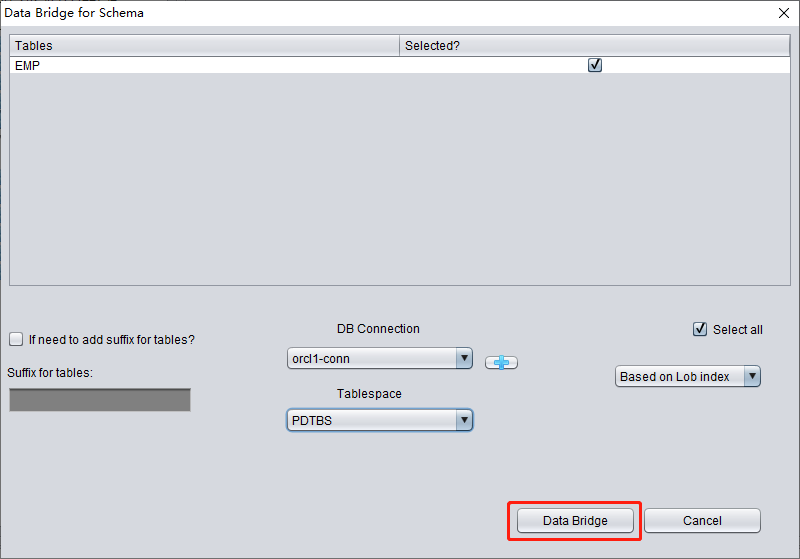
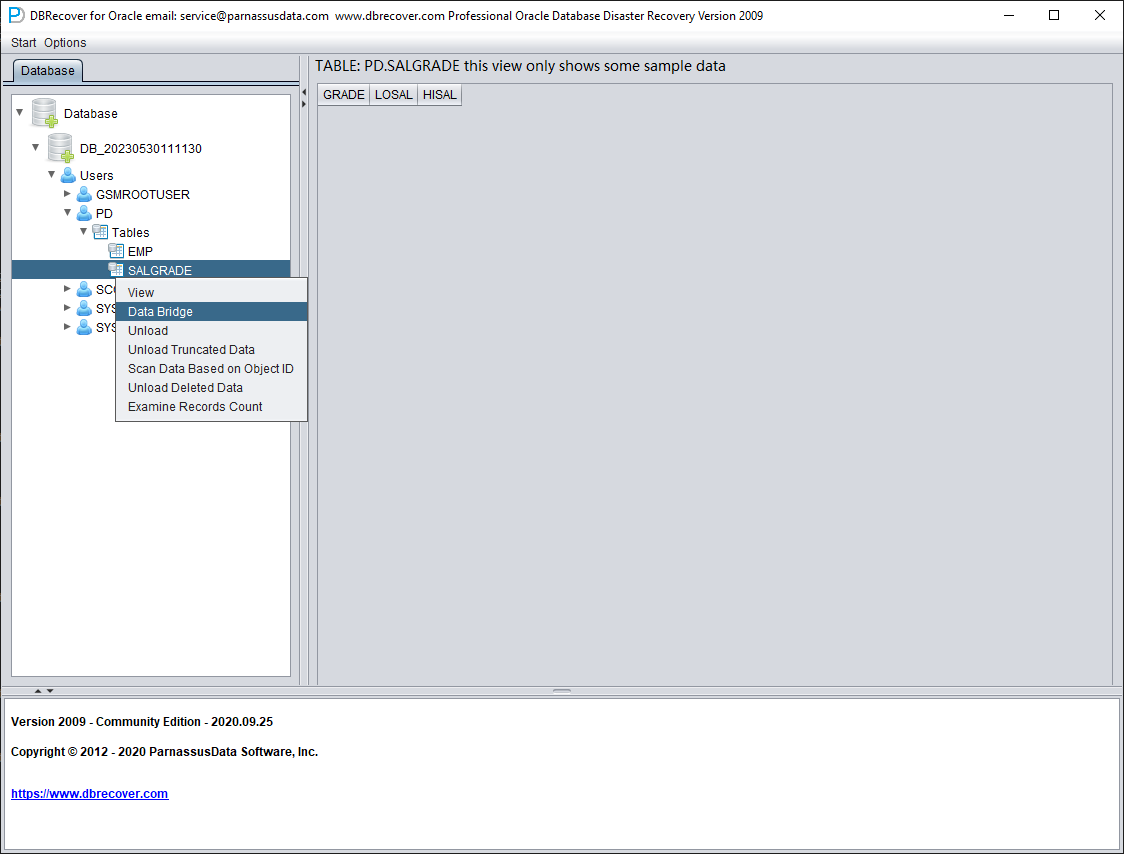
- Dans DBRECOVER, sélectionnez le nom d'utilisateur à récupérer, faites un clic droit et choisissez Data Bridge
- Dans l'interface Data Bridge, cliquez sur l'icône « + » pour ajouter les informations de connexion à la nouvelle base (Connection)
- Cliquez sur Data Bridge pour lancer le transfert et attendez que toutes les tables du SCHEMA soient transférées vers le SCHEMA cible de la base cible
- Sélectionnez le SCHEMA correspondant, faites un clic droit et choisissez la fonction d'export DDL EXPORTDDL ; sélectionnez les types d'objets à récupérer et cliquez sur EXPORT
- À partir du fichier SQL DDL généré par EXPORTDDL, exécutez-le manuellement dans le SCHEMA cible de la base cible
Note de récupération : démarrez le listener (LISTENER) pour vous assurer que le service de base est enregistré auprès de celui-ci.
C:\Users\testenv>lsnrctl status
LSNRCTL for 64-bit Windows: Version 11.2.0.1.0 - Production on 12-MAY-2023 10:01:48
Copyright (c) 1991, 2010, Oracle. All rights reserved.
Connecting to (DESCRIPTION=(ADDRESS=(PROTOCOL=TCP)(HOST=DESKTOP-testenv)(PORT=1521)))
STATUS of the LISTENER
-----------------------
Alias LISTENER
Version TNSLSNR for 64-bit Windows: Version 11.2.0.1.0 - Production
Start Date 12-MAY-2023 10:00:49
Uptime 0 days 0 hr. 0 min. 59 sec
Trace Level off
Security ON: Local OS Authentication
SNMP OFF
Listener Parameter File D:\app\testenv\product\11.2.0\dbhome_2\network\admin\listener.ora
Listener Log File d:\app\testenv\diag\tnslsnr\DESKTOP-testenv\listener\alert\log.xml
Listening Endpoints Summary...
(DESCRIPTION=(ADDRESS=(PROTOCOL=tcp)(HOST=DESKTOP-testenv)(PORT=1521)))
(DESCRIPTION=(ADDRESS=(PROTOCOL=ipc)(PIPENAME=\\.\pipe\EXTPROC1521ipc)))
Services Summary...
Service "CLRExtProc" has 1 instance(s).
Instance "CLRExtProc", status UNKNOWN, has 1 handler(s) for this service...
Service "ORCL1XDB" has 1 instance(s).
Instance "orcl1", status READY, has 1 handler(s) for this service...
Service "ORCLXDB" has 1 instance(s).
Instance "orcl", status READY, has 1 handler(s) for this service...
Service "orcl" has 1 instance(s).
Instance "orcl", status READY, has 1 handler(s) for this service...
Service "orcl1" has 1 instance(s).
Instance "orcl1", status READY, has 1 handler(s) for this service...
The command completed successfully
Note de récupération : créez les utilisateurs et tablespaces correspondants dans la nouvelle base ; il est recommandé d'octroyer temporairement le rôle DBA à ces utilisateurs.
set ORACLE_SID=ORCL1
sqlplus / as sysdba
SQL> create user pd identified by oracle;
User created.
SQL> grant dba to pd;
Grant succeeded.
SQL> create tablespace pdtbs datafile size 500M autoextend on next 100M;
Tablespace created.
SQL> alter user pd default tablespace pdtbs;
User altered.
Démarrez DBRECOVER, puis sélectionnez Tools => Recovery Wizard
Cliquez sur Next.
L'étape suivante consiste à choisir le bon ordre des octets ENDIAN. Les fichiers de données Oracle adoptent des formats endian différents selon les plateformes des systèmes d'exploitation.
L'endian est la méthode de stockage en mémoire des types de données multi-octets. Il détermine l'ordre des octets de la donnée. Il existe deux variantes d'endian : Little et Big. En Little Endian, les données sont stockées avec l'extrémité de poids faible en premier ; autrement dit, le premier octet est le plus important. En Big Endian, les données sont stockées avec l'extrémité de poids fort en premier ; autrement dit, le premier octet est le plus petit.
Dans les bases Oracle, le format endian est déterminé par les informations endian de l'environnement dans lequel la base s'exécute. Le format endian de la base indique vers quels environnements elle peut être déplacée. Il n'est pas possible de déplacer la base par les méthodes habituelles entre des environnements d'endians différents. Par exemple, vous ne pouvez pas transférer une base sous Data Guard d'un système Little Endian vers un système Big Endian.
Vous pouvez consulter le format endian actuel de votre base avec la requête suivante :
Le résultat vous donnera le format endian de votre base actuelle.
Pour le format Big Endian, les plateformes incluent IBM AIX, Apple Mac OS, HP-UX (64 bits), HP-UX IA (64 bits), IBM Power Based Linux, IBM zSeries Based Linux et Solaris OE (32 bits comme 64 bits).
Pour le format Little Endian, les plateformes incluent Linux x86 64 bits, Apple Mac OS (x86-64), HP IA Open VMS, HP Open VMS, HP Tru64 UNIX, Linux IA (32 bits), Linux IA (64 bits), Microsoft Windows IA (32 bits), Microsoft Windows IA (64 bits), Microsoft Windows x86 64 bits et Solaris Operating System (x86 et x86-64).
L'ordre des octets selon la plateforme est le suivant :
| plateforme | endian |
| Solaris[tm] OE (32-bit) | Big |
| Solaris[tm] OE (64-bit) | Big |
| Microsoft Windows IA (32-bit) | Little |
| Linux IA (32-bit) | Little |
| AIX-Based Systems (64-bit) | Big |
| HP-UX (64-bit) | Big |
| HP Tru64 UNIX | Little |
| HP-UX IA (64-bit) | Big |
| Linux IA (64-bit) | Little |
| HP Open VMS | Little |
| Microsoft Windows IA (64-bit) | Little |
| IBM zSeries Based Linux | Big |
| Linux x86 64-bit | Little |
| Apple Mac OS | Big |
| Microsoft Windows x86 64-bit | Little |
| Solaris Operating System (x86) | Little |
| IBM Power Based Linux | Big |
| HP IA Open VMS | Little |
| Solaris Operating System (x86-64) | Little |
| Apple Mac OS (x86-64) | Little |
Il suffit de noter que les plateformes les plus couramment utilisées, Windows et Linux, sont toutes deux en Little Endian : aucun réglage n'est nécessaire, on conserve la valeur par défaut.
Sur les plateformes Unix de gamme intermédiaire, notamment AIX-Based Systems (64 bits) et HP-UX (64 bits), c'est le Big Endian qui est utilisé : il faut donc sélectionner Big Endian.
Remarque : si votre fichier de données a été généré sous AIX (donc en Big Endian) et que vous avez copié ces fichiers de données sur un serveur Windows par commodité afin d'utiliser DBRECOVER pour récupérer les données, vous devez tout de même choisir son format Big Endian d'origine.
Ici, puisque nous récupérons des fichiers de base Oracle issus de la plateforme Linux x86-64, nous choisissons Little Endian pour l'Endian.
Cliquez sur Next
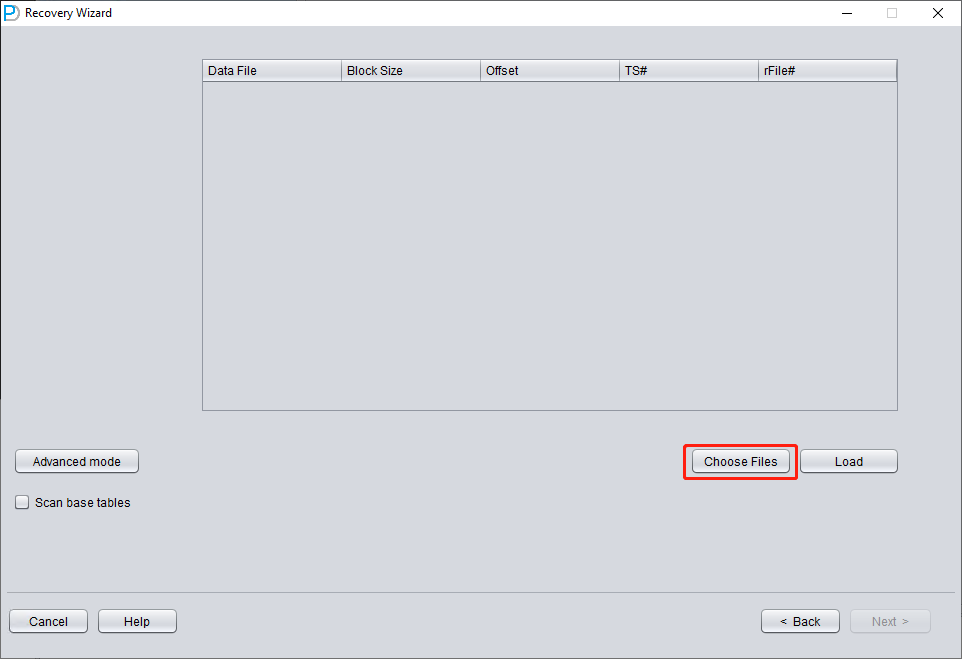
Cliquez sur « Choose Files ». De manière générale, si la base n'est pas volumineuse, nous recommandons de sélectionner tous ses fichiers de données. Si votre base est très volumineuse et que vous savez sur quels fichiers de données se trouvent vos tables, vous pouvez ne sélectionner que les fichiers de données du tablespace SYSTEM (indispensable !) et les fichiers de données où se trouvent les données.
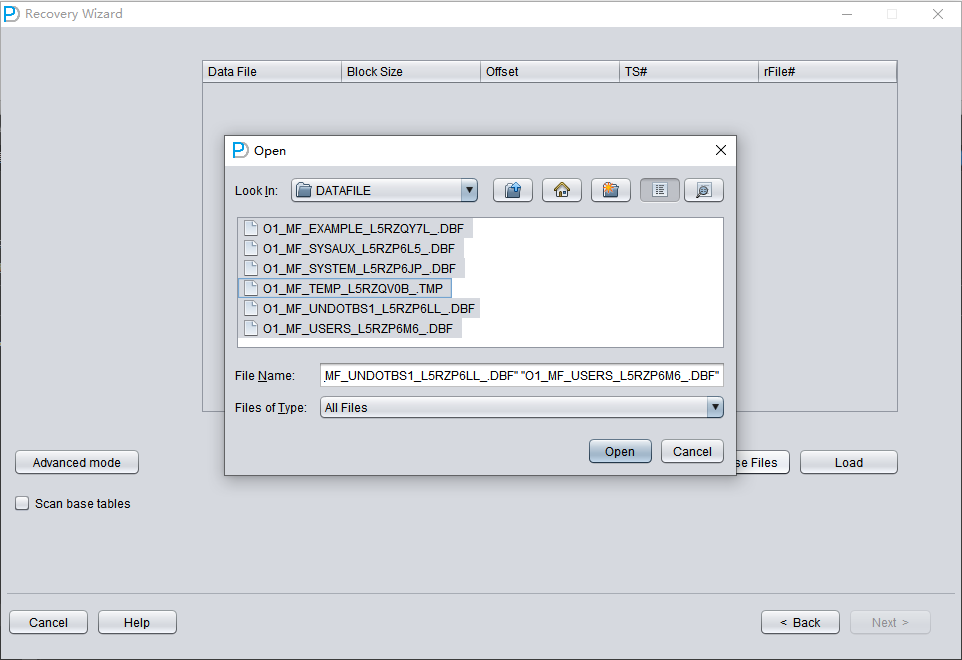
Notez que l'interface Choose prend en charge les raccourcis clavier Ctrl + A et Shift.
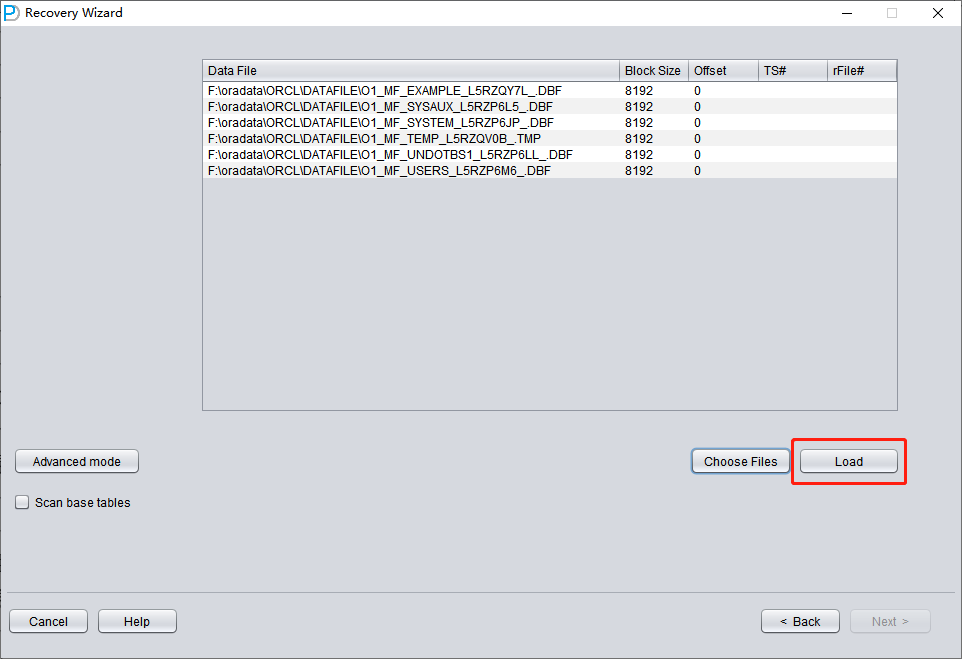
Remarque : après avoir ajouté tous les fichiers de données, si vous ne comprenez pas les autres paramètres de cet écran, conservez les valeurs par défaut et ne les modifiez pas.
Vous devez ensuite spécifier la Block Size (taille de bloc) pour le fichier de données indiqué, c'est-à-dire la taille du bloc de données ORACLE. Vous pouvez la modifier ici selon la situation réelle. Par exemple, si votre DB_BLOCK_SIZE est de 8K mais que certains tablespaces spécifient 16K comme taille de bloc de données, il vous suffit de modifier le BLOCK_SIZE pour les fichiers de données qui ne sont pas en 8K.
Lorsque l'on utilise un système de fichiers classique, il n'est pas nécessaire de spécifier d'OFFSET ici. Le paramètre OFFSET est principalement destiné aux scénarios où des raw devices sont utilisés pour stocker les fichiers de données. Par exemple, sous AIX, si la LV d'un VG ordinaire sert de fichier de données, un OFFSET de 4 Ko doit être indiqué ici.
Si vous utilisez justement des fichiers de données sur raw device et que vous ne connaissez pas la valeur de l'OFFSET, vous pouvez utiliser l'outil dbfsize fourni dans $ORACLE_HOME/bin pour le vérifier. L'exemple suivant montre que ce raw device n'a pas d'OFFSET de 4 Ko :
$ dbfsize /dev/lv_control_01
Database file: /dev/lv_control_01
Database file type: raw device without 4K starting offset
Database file size: 334 blocs de 16384 octets
Comme tous les fichiers de données de ce scénario ont une BLOCK SIZE de 8K et reposent sur un système de fichiers, aucun n'a d'OFFSET ; cliquez sur « Load ».
Durant l'étape Load, DBRECOVER lit les informations du dictionnaire de données ORACLE depuis le tablespace SYSTEM et construit un dictionnaire de données dans sa base Derby intégrée. Cela permet à DBRECOVER d'analyser les différentes données contenues dans la base ORACLE.
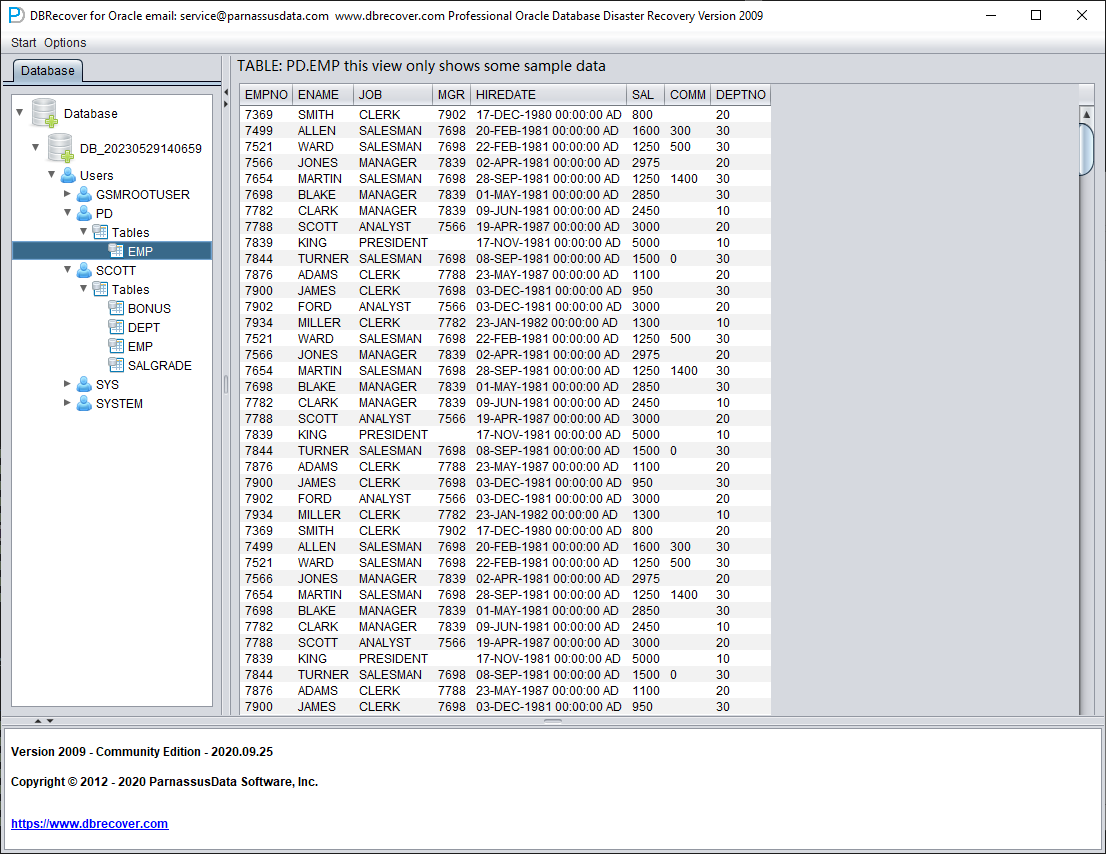
Une fois le chargement terminé, l'interface de DBRECOVER affiche à gauche une arborescence regroupée par utilisateurs de la base :
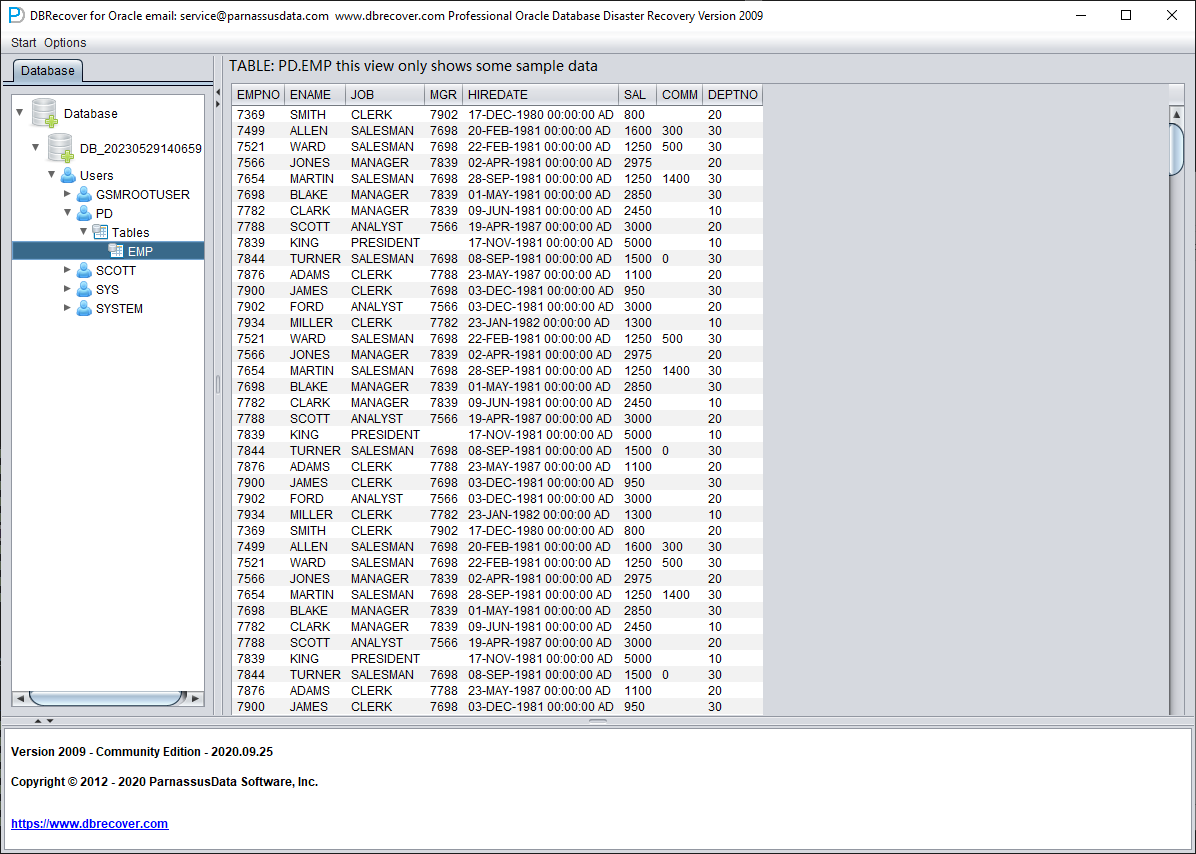
Sélectionnez une table à récupérer et double-cliquez pour visualiser les données :
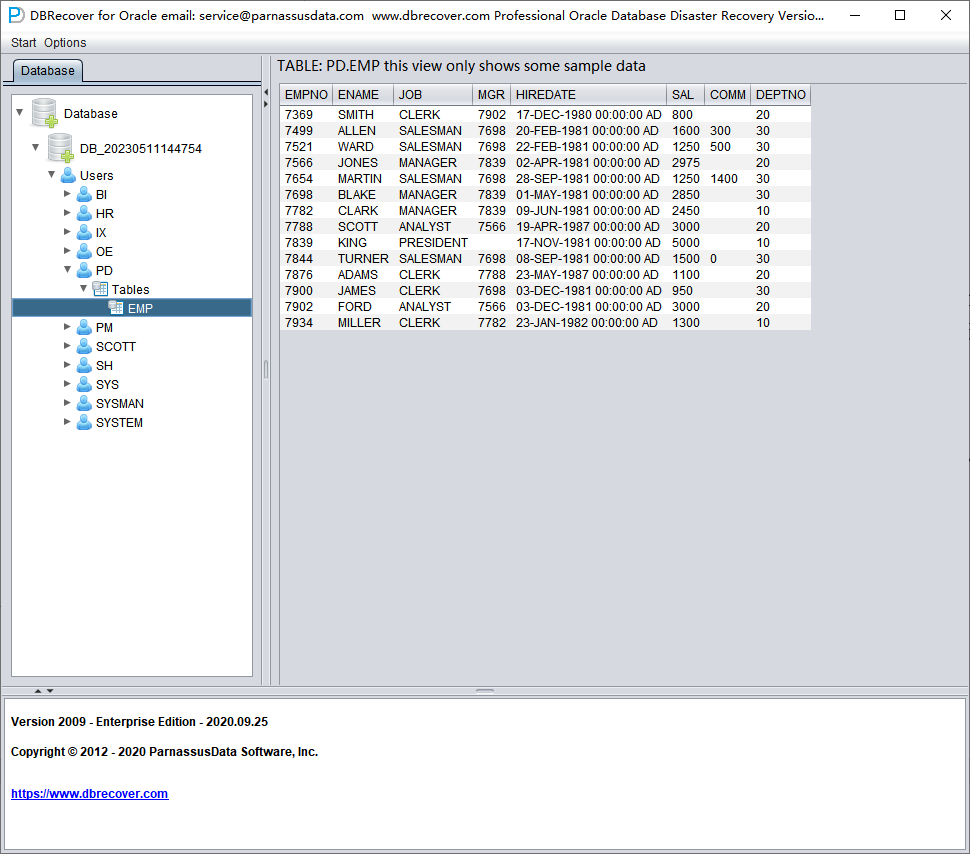
Sans avoir acheté de licence logicielle, on peut évaluer la capacité de DBRECOVER à récupérer suffisamment de données en consultant les tables, en extrayant au moins 10 000 lignes et en vérifiant le nombre de lignes récupérables.
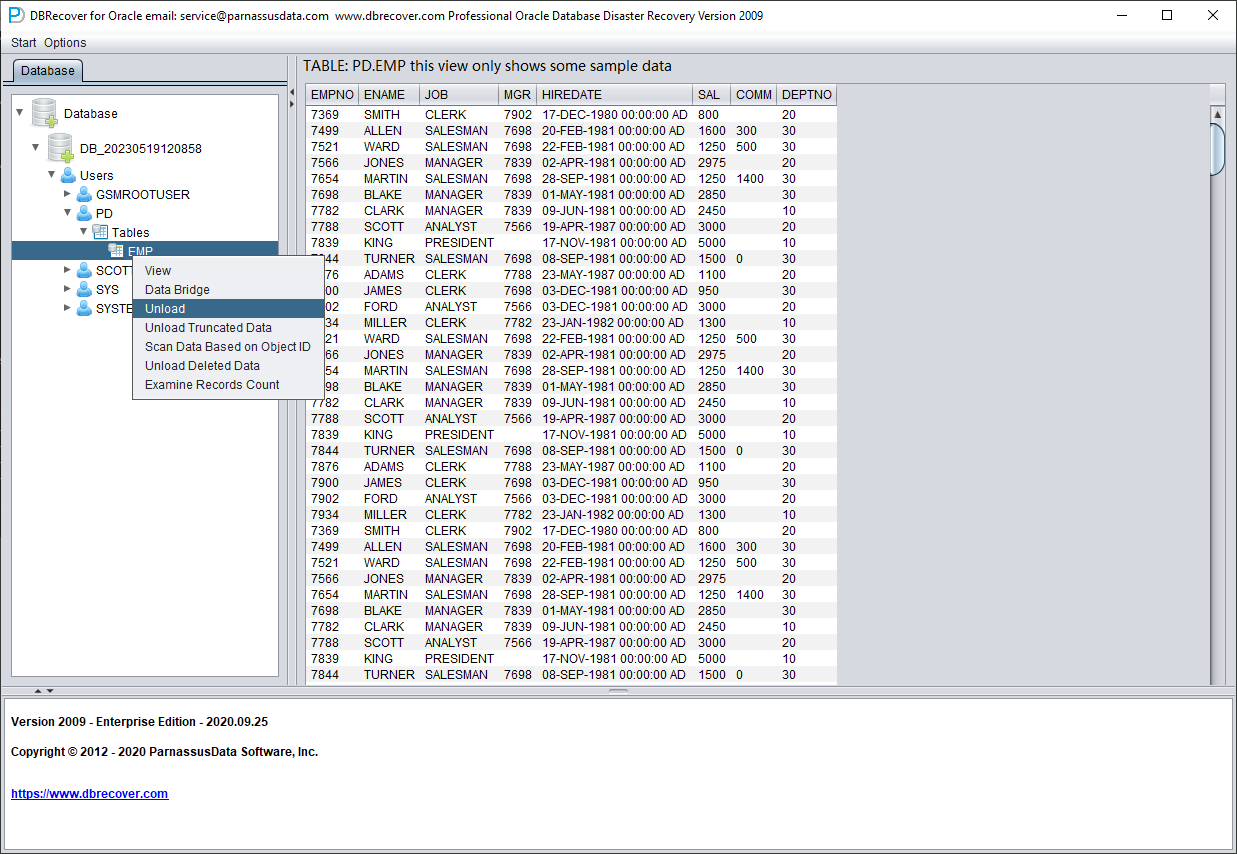
Après avoir sélectionné la table, faites un clic droit sur UNLOAD : la table sera exportée au format texte :
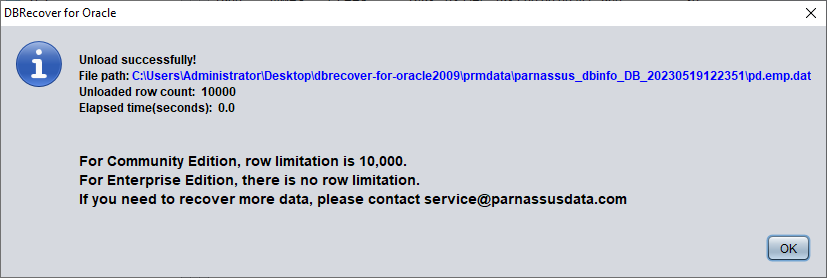
Sans licence logicielle enregistrée, l'extraction est limitée à 10 000 lignes par table.
Pour les tables contenant plus de 10 000 lignes, la fonction de vérification du nombre de lignes récupérables permet d'aller plus loin. Sélectionnez la table à vérifier, puis faites un clic droit sur EXAMINE RECORDS COUNT :
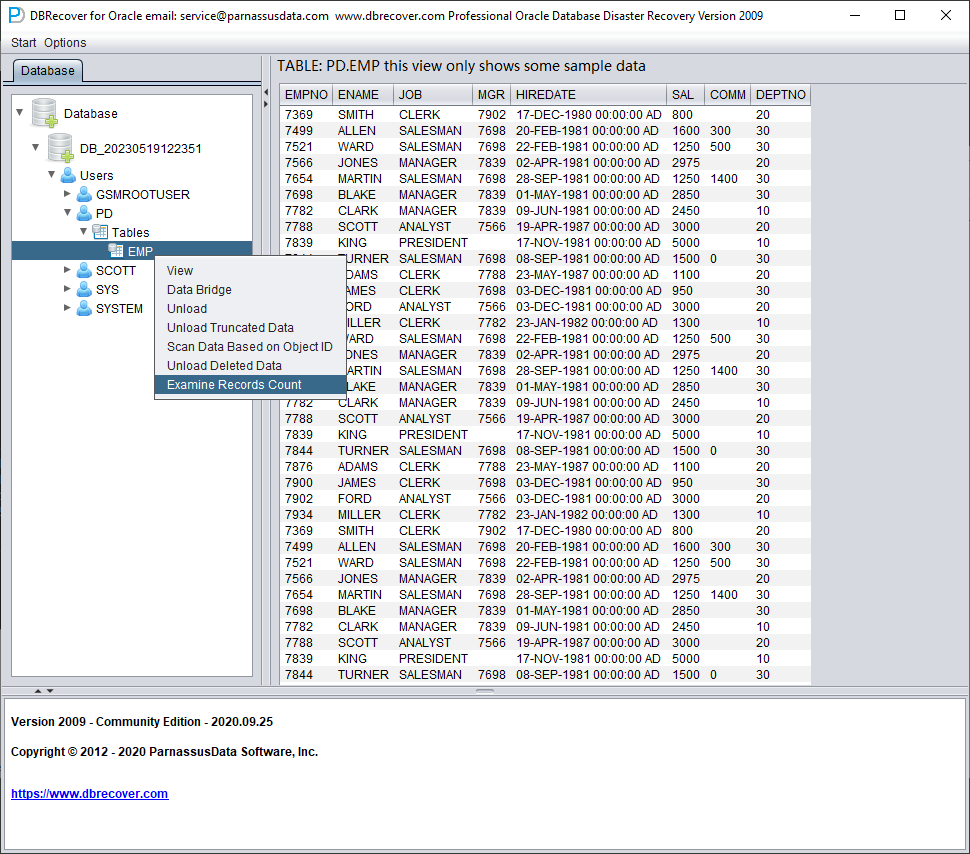
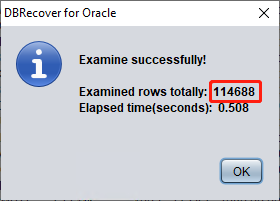
Depuis Oracle 10g, une fonctionnalité de jobs de collecte automatique des statistiques a été introduite. Grâce à elle, on peut consulter l'historique des statistiques de la table, y compris le nombre de lignes. En mode dictionnaire, le logiciel écrit les métadonnées de la table dans son fichier journal log_dbrecover.txt à chaque consultation, extraction ou vérification d'une table. Le fichier journal est stocké dans le répertoire du logiciel :
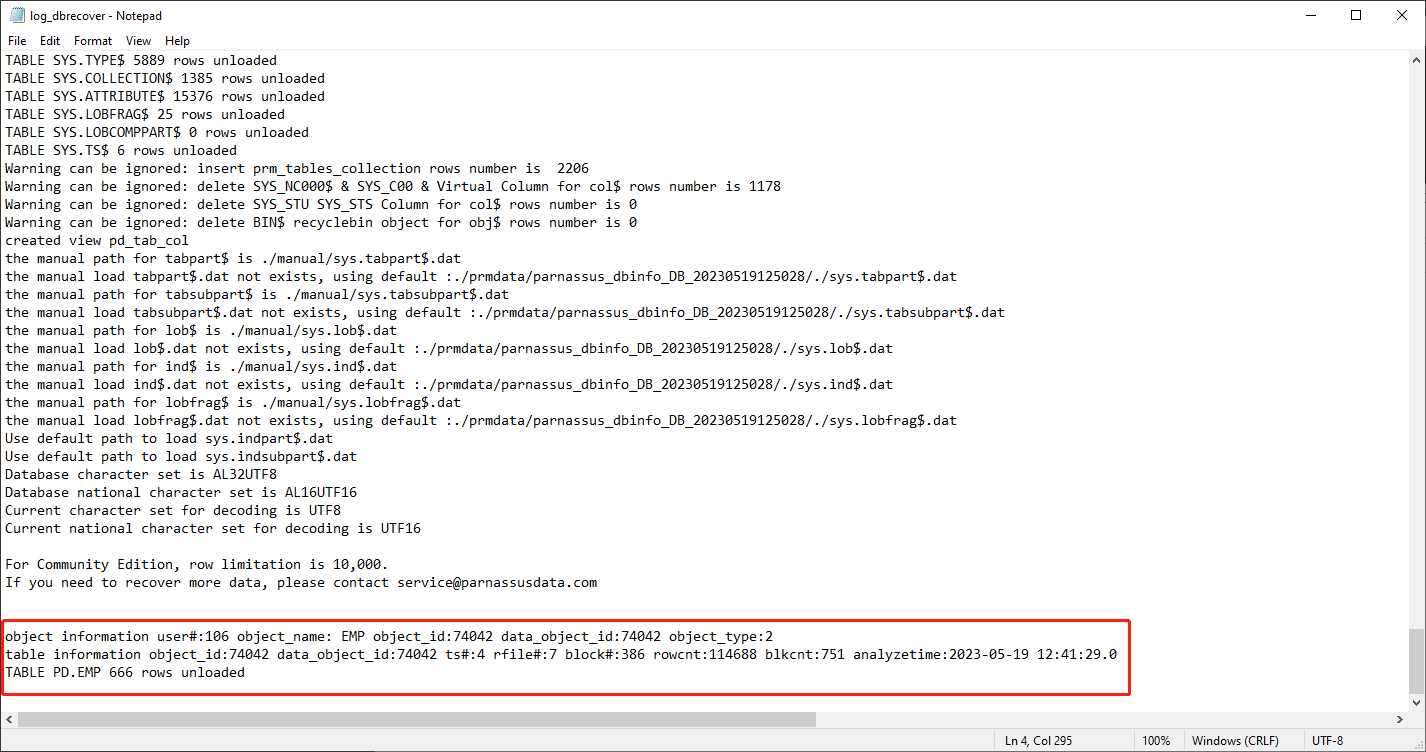
consultez le fichier journal :
object information user#:106 object_name: EMP object_id:74042 data_object_id:74042 object_type:2
table information object_id:74042 data_object_id:74042 ts#:4 rfile#:7 block#:386 rowcnt:114688 blkcnt:751 analyzetime:2023-05-19 12:41:29.0
TABLE PD.EMP 666 rows unloaded
De nombreuses informations utiles apparaissent dans le journal :
| object_id | 74042 |
| data_object_id | 74042 |
| ts# | 4 |
| rfile# | 7 |
| block# | 386 |
| rowcnt | 114688 |
| blkcnt | 751 |
| analyzetime | 2023-05-19 12:41:29.0 |
En général, la marge d'erreur des statistiques ne dépasse pas 10 % : on peut donc comparer le résultat de la vérification du nombre de lignes au rowcnt indiqué ici. Par exemple, le rowcnt vaut 114688 (la marge d'erreur des statistiques est très faible pour les tables de moins d'un million de lignes) et le résultat d'EXAMINE est de 114688 lignes, ce qui confirme la fiabilité de ce résultat.
Les utilisateurs peuvent effectuer les vérifications ci-dessus sur chaque table importante en fonction de leurs besoins. Nous suggérons de bien vérifier l'intégrité des données récupérables avant tout achat de licence logicielle.
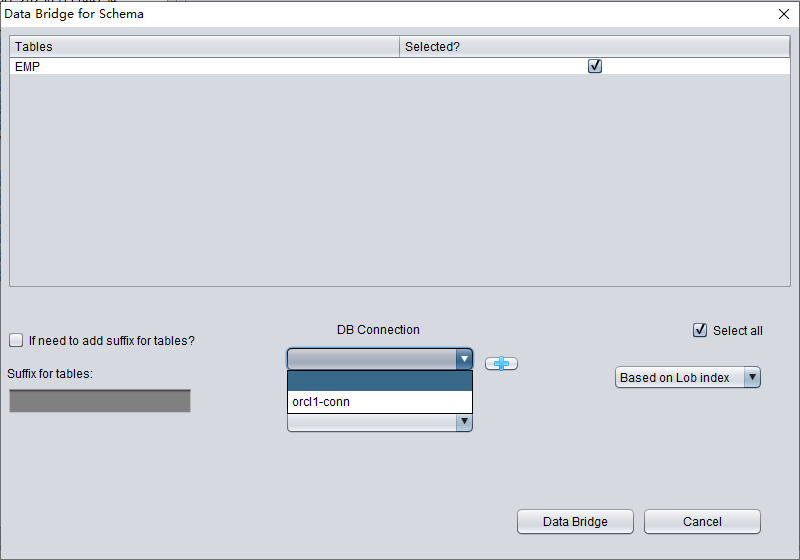
Après ces vérifications, nous lançons le transfert via Data Bridge au niveau de l'utilisateur SCHEMA. Faites un clic droit sur le nom d'utilisateur à récupérer puis sélectionnez Data Bridge.
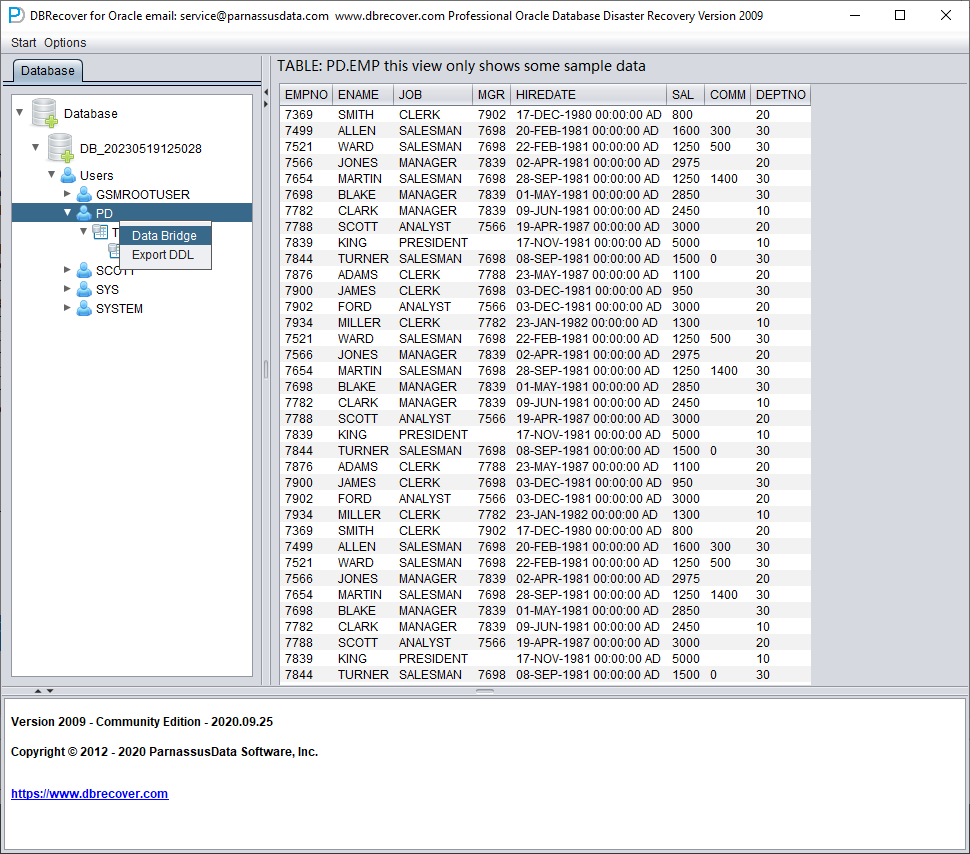
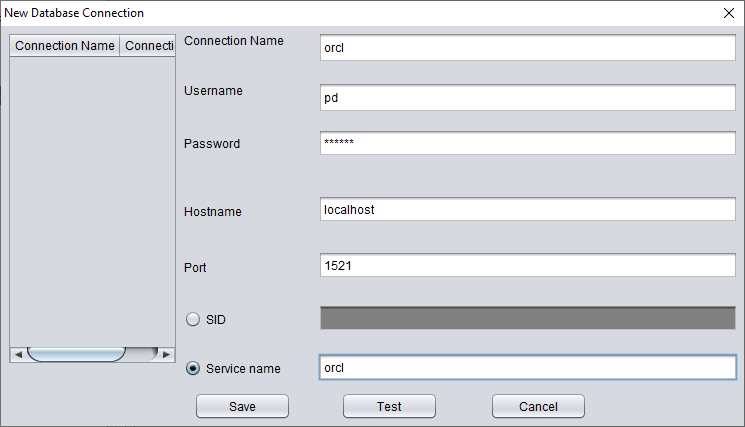
Dans l'interface Data Bridge au niveau du SCHEMA, cliquez sur le bouton « + » pour ajouter les informations de connexion de la base cible :
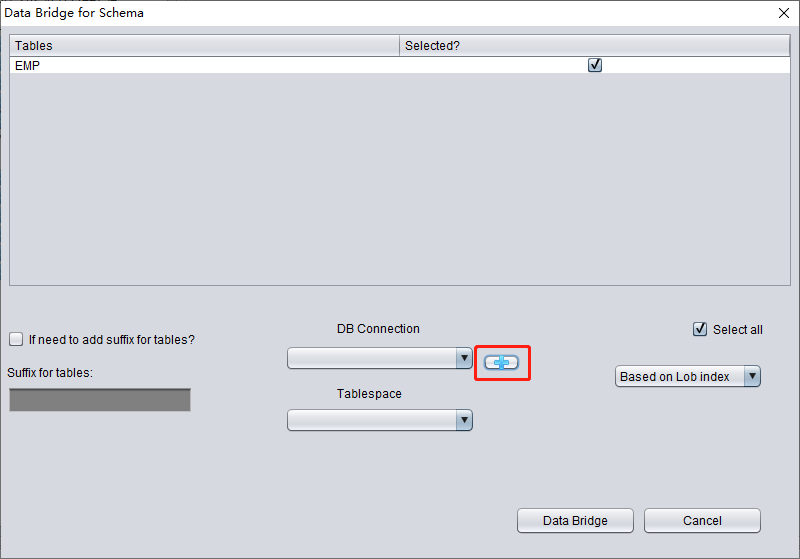
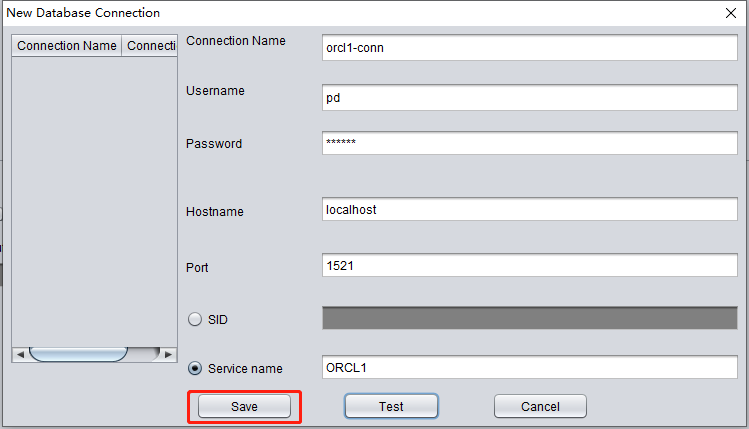
Saisissez les informations de connexion de l'instance nouvellement créée ; nous utilisons ici l'utilisateur PD.
Remarque : le logiciel DBRECOVER ne transfère les données qu'à l'utilisateur indiqué dans les informations de connexion à la base : autrement dit, si vous saisissez PD ici, les données seront transférées vers PD. Les clients doivent suivre un principe simple de correspondance un à un : s'il y a un utilisateur de base à récupérer, par exemple EAS, créez un utilisateur EAS et son tablespace dans la base cible, attribuez-lui les permissions nécessaires (rôle DBA) et saisissez EAS dans cette connexion pour garantir que les données soient transférées vers EAS. Le PD utilisé ici n'est qu'un exemple. Si un client souhaite récupérer plusieurs utilisateurs de base, par exemple EAS, MES, NC001, etc., il doit créer en conséquence ces comptes et leurs tablespaces dans la base cible, leur attribuer les permissions requises (rôle DBA), puis créer plusieurs informations de connexion à la base (DB Connection) dans DBRECOVER, en précisant la connexion (DB Connection) correspondante lors du transfert d'un SCHEMA utilisateur particulier.
Cliquez sur TEST pour vérifier la disponibilité de la connexion à la base cible :
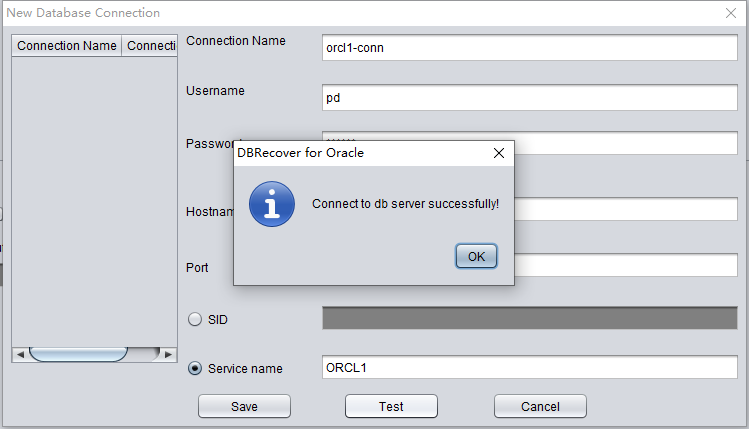
Si le test réussit, cliquez sur SAVE pour enregistrer :
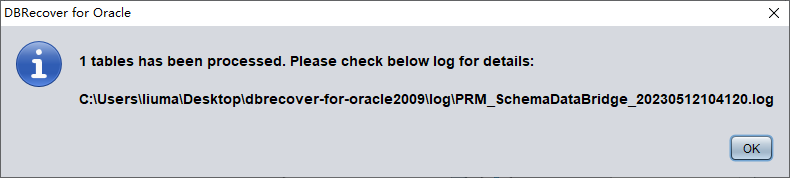
vérifiez les données
SQL> show parameter db_name
NAME TYPE VALUE
----------------------------------- ---------------------- ------------------------------
db_name string ORCL1
SQL> select count(*) from pd.emp;
COUNT(*)
---------
14
Présentation du mode WIDE TABLE
Remarque : le Data Bridge ci-dessus utilise par défaut le mode WIDE TABLE pour transférer les données, c'est-à-dire qu'il convertit tous les types de champs CHAR, NCHAR, VARCHAR, NVARCHAR à leur longueur maximale par défaut, soit 2000 ou 4000. L'objectif est d'éviter qu'une chaîne récupérée ne puisse pas être insérée correctement parce que le champ serait trop court.
Si vous ne souhaitez pas utiliser le mode WIDE TABLE, cliquez dans la barre de menu sur Options => Preferences.
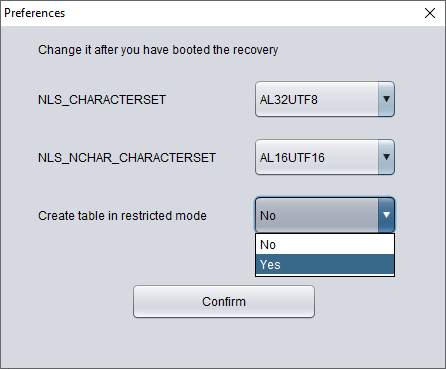
Ci-dessus, sélectionner « Yes » dans la liste déroulante « Create table in restricted mode » empêchera l'utilisation du mode WIDE TABLE pour créer les tables.
Présentation de la fonction EXPORT DDL
L'opération de récupération ci-dessus portait sur des tables individuelles d'un SCHEMA. Les objets récupérés incluent : la création des tables correspondantes et l'insertion des données récupérables.
Pour la récupération des index, contraintes, vues, déclencheurs et autres objets, on peut utiliser la fonction EXPORT DDL.
Sélectionnez le SCHEMA à récupérer, faites un clic droit et choisissez la fonction EXPORT DDL :
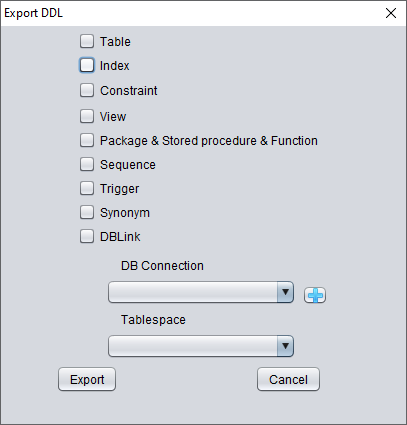
Les types d'objets pouvant être récupérés sont :
- Instructions CREATE TABLE (à noter : elles n'incluent pas les informations de partitionnement)
- Instructions CREATE INDEX (à noter : elles n'incluent pas les informations de partitionnement)
- Contraintes
- Vues
- Packages, procédures stockées et fonctions
- Séquences
- Déclencheurs (triggers)
- Synonymes
- DBlinks
Ici, sélectionnez les informations de connexion à la base saisies précédemment pour le traitement temporaire des informations DDL.

Une fenêtre contextuelle indiquera le chemin du fichier SQL DDL. Examinez ce fichier :
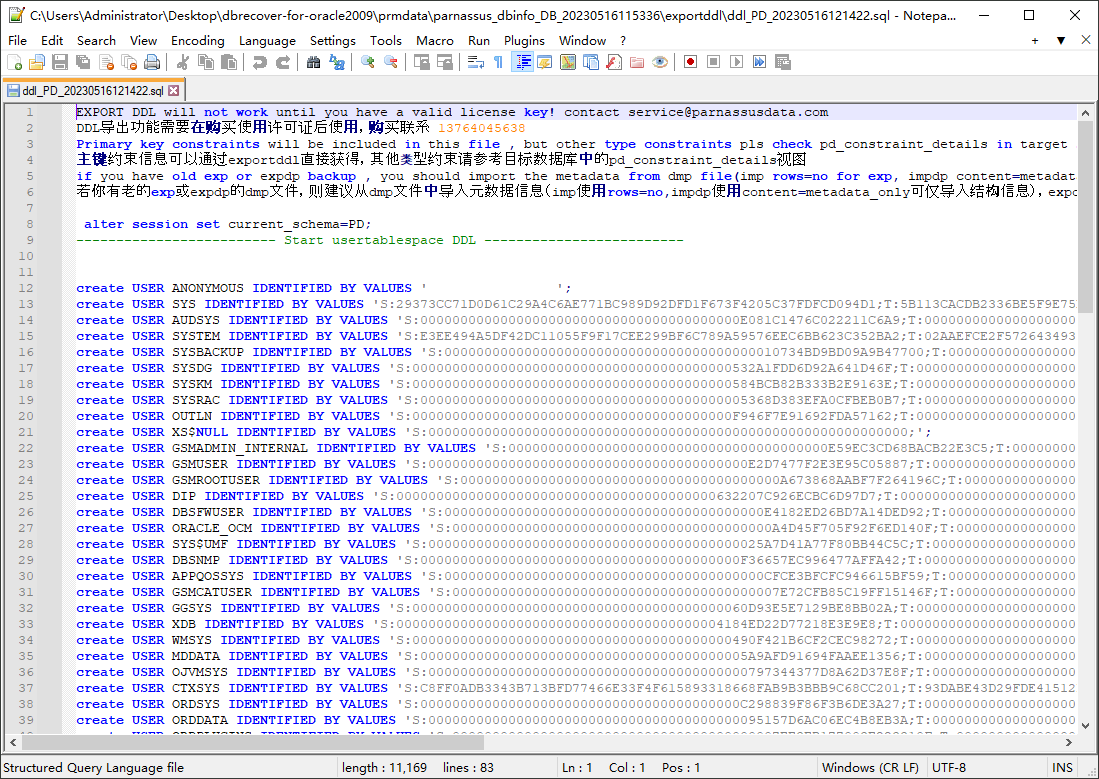
Remarque : la fonction EXPORTDDL ne peut être utilisée normalement qu'après l'enregistrement d'une licence édition entreprise (LICENSE KEY) valide !
Les instructions contenues dans le fichier SQL DDL ci-dessus pour créer index, vues et autres objets doivent être copiées par l'utilisateur et exécutées sous l'utilisateur de base correspondant.
Si l'utilisateur dispose d'anciens fichiers dmp issus d'exp ou d'expdp, il est recommandé d'importer les métadonnées depuis le fichier dmp (utilisez rows=no pour imp, content=metadata_only pour impdp afin de n'importer que les informations de structure). La fonction exportddl ne couvre pas une petite partie des métadonnées, comme les droits sur les objets ou les clés étrangères, etc.
Présentation de la fonction LOAD FROM EXIST DICTS :
Lors de la récupération effective, si vous rencontrez des situations où le programme ne répond plus, se bloque ou signale une erreur, vous pouvez utiliser la fonction LOAD FROM EXIST DICTS pour recharger directement l'état précédent de récupération après avoir redémarré DBRECOVER.
Les états de récupération sont triés par date. Après votre sélection, cliquez sur le bouton LOAD pour charger. Le mode dictionnaire (DICTIONARY-MODE) comme le mode non dictionnaire (NON-DICTIONARY MODE) peuvent utiliser cette fonction de chargement rapide afin d'éviter des opérations répétitives.
Scénario de récupération 2 : Suppression accidentelle ou perte totale du tablespace SYSTEM
L'administrateur système (SA) de l'entreprise D a accidentellement supprimé le fichier de données contenant le tablespace SYSTEM d'une certaine base, ce qui a rendu la base totalement inutilisable et empêché l'extraction des données. En l'absence de sauvegarde, DBRECOVER peut être utilisé pour fouiller les données.
Dans ce scénario, après avoir démarré DBRECOVER et ouvert le Recovery Wizard, sélectionnez « Non-Dictionary mode » (mode hors dictionnaire) :
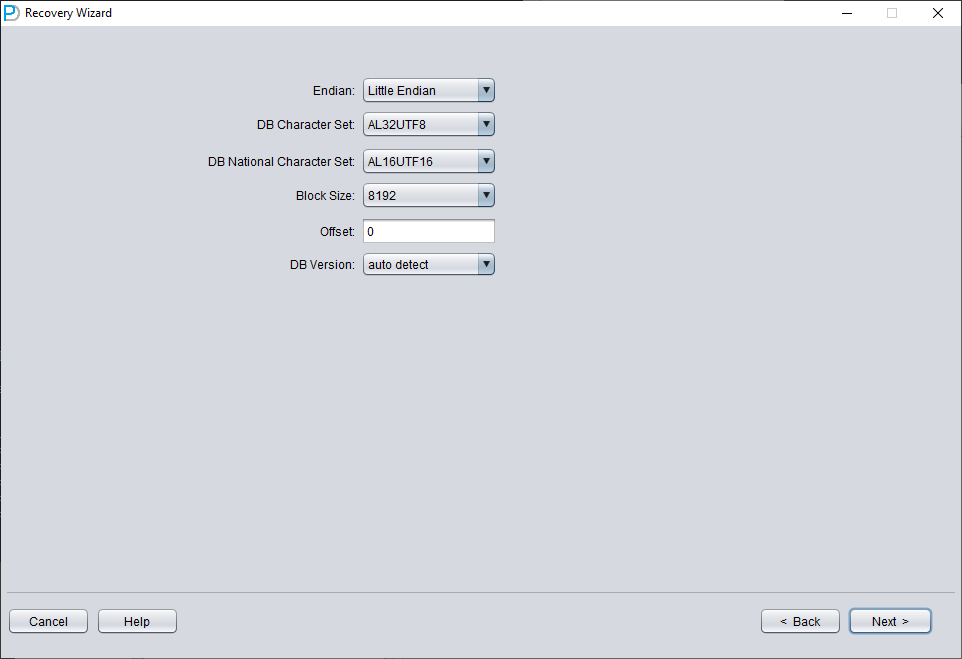
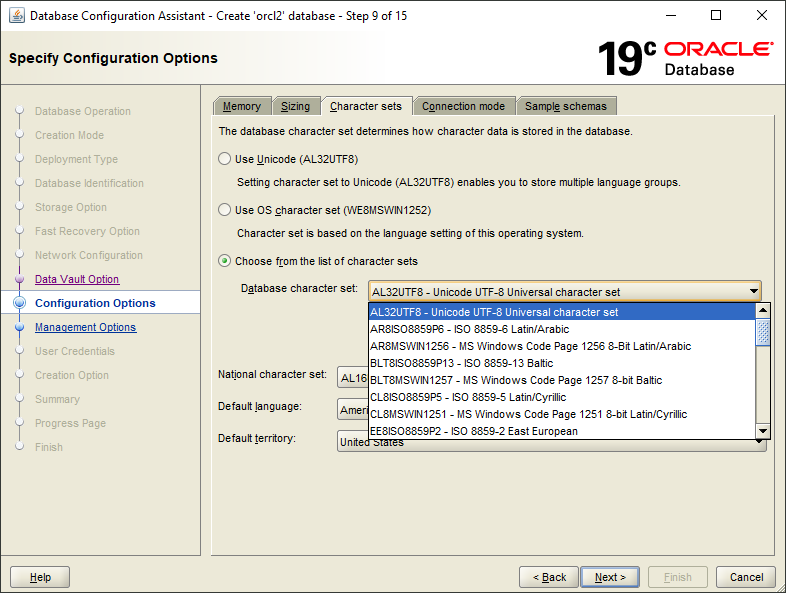
Vous devez ensuite choisir le bon jeu de caractères, faute de quoi les données ultérieures seront illisibles.
En mode Non-Dictionary, vous devez préciser le jeu de caractères et le jeu de caractères national. Une fois le tablespace SYSTEM perdu, les métadonnées du jeu de caractères de la base ne peuvent plus être lues : DBRECOVER vous demande donc de les fournir. L'extraction multilingue en mode Non-Dictionary ne fonctionne correctement que si le jeu de caractères et les paquets linguistiques correspondants sont configurés.
Comme dans la démonstration du scénario 1, ajoutez tous les fichiers de données actuellement disponibles pour l'utilisateur (à l'exclusion des fichiers temporaires) et indiquez la bonne Block Size ainsi que l'OFFSET :
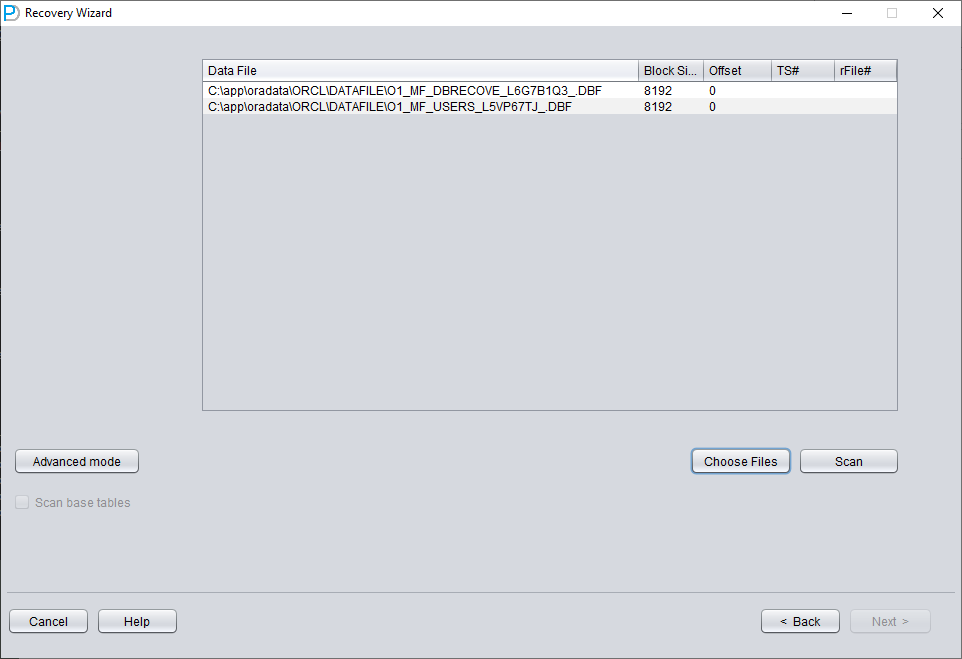
Cliquez ensuite sur SCAN. La fonction SCAN parcourt les informations de données sur l'ensemble des fichiers de données.
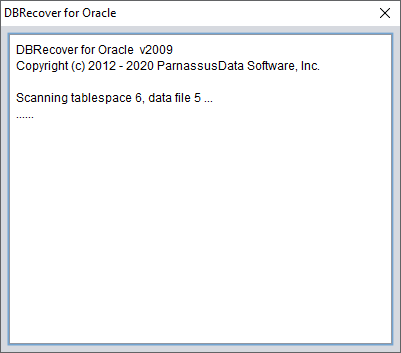
Faites ensuite un clic droit sur le nœud de la base dans l'arborescence à gauche pour lancer SCAN EXTENT. N'utilisez le mode SCAN TABLE FROM SEGMENTS que lorsque vous êtes certain que tous les fichiers de données (à l'exception de SYSTEM01.DBF) sont disponibles. Ce mode présente l'avantage d'être légèrement plus rapide, mais son taux de récupération est inférieur à celui du mode SCAN EXTENT en cas de fichiers de données incomplets ou endommagés.
Une fois Scan Tables From Extents terminé, vous pouvez ouvrir l'arborescence à gauche de l'interface principale :
Chaque nœud de l'arborescence représente un segment de données d'une table heap ordinaire ou d'une partition, et son nom est obj + DATA OBJECT ID enregistré sur ce segment.
Cliquez sur un nœud et observez le panneau latéral à droite de l'interface principale :
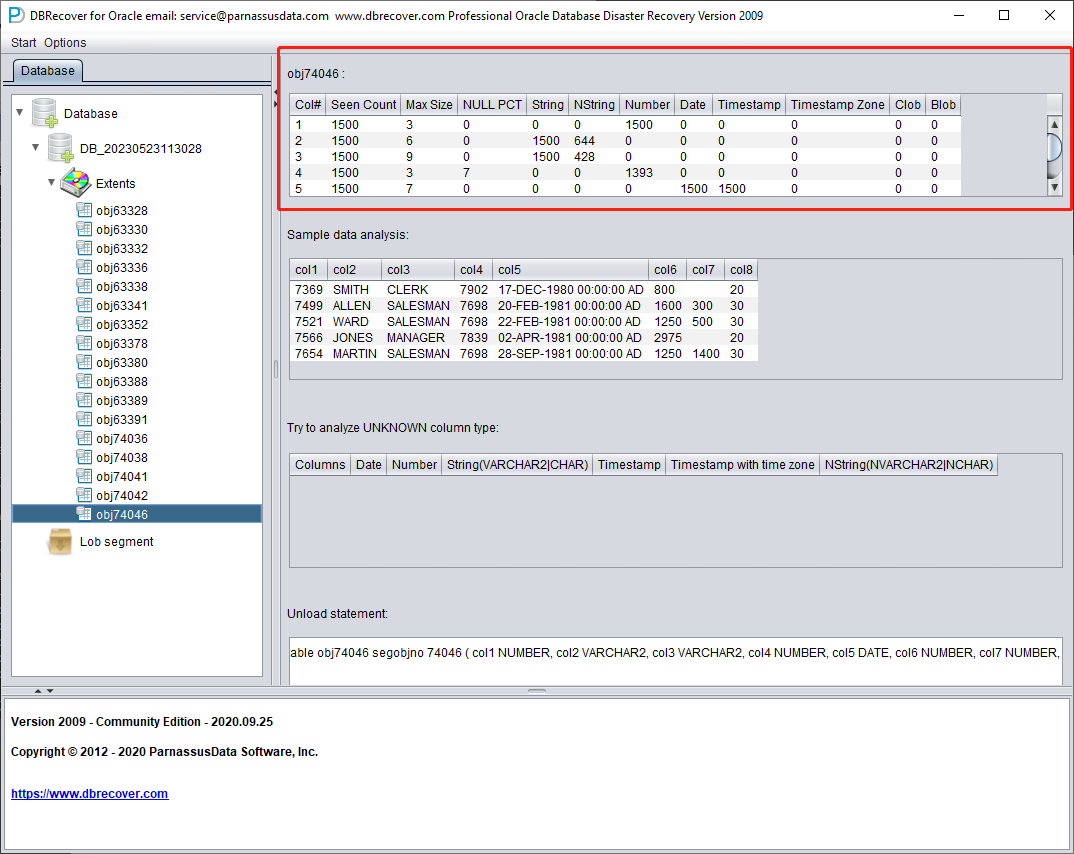
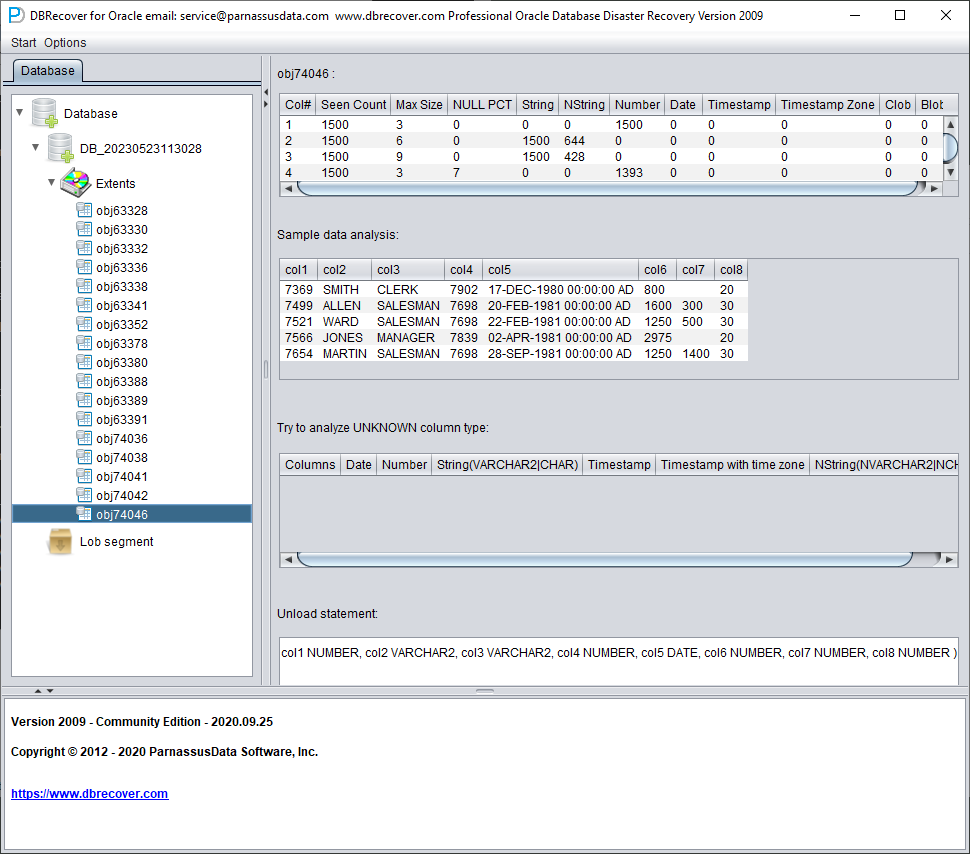
Analyse du type des champs
En raison de la perte du tablespace SYSTEM, le mode Non-Dictionary ne dispose pas des informations de structure des tables. Ces informations comprennent les noms et types des champs ; or, dans ORACLE, elles ne sont conservées que sous forme de dictionnaire et ne sont pas stockées dans la table elle-même. Lorsque l'utilisateur ne dispose que du tablespace contenant les données applicatives, il faut deviner le type de chaque champ à partir des lignes ROW présentes dans le segment de données. Nous savons ici reconnaître plus de 10 types de données courants :
- Chaîne : inclut char, varchar
- Chaîne nationale (NString) : nchar, nvarchar
- Type numérique Number
- Type Date
- Type TimeStamp
- Type TimeStamp Zone avec fuseau horaire
- CLOB
- BLOB
Analyse des données échantillons
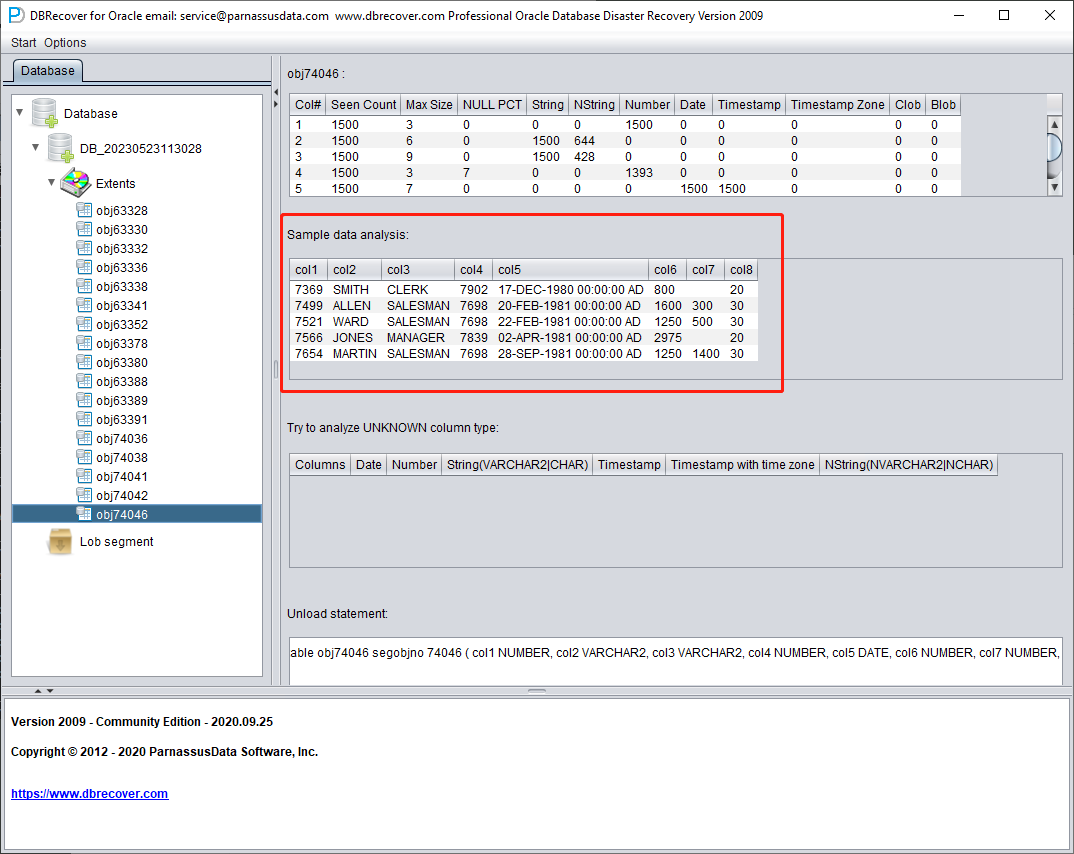
Cette partie analyse 10 enregistrements à partir des résultats de l'analyse des types de champs et affiche les résultats du parsing. Ces données échantillons permettent à l'utilisateur de comprendre les données réellement stockées dans ce segment. S'il y a moins de 10 enregistrements présents dans le segment, tous seront affichés.
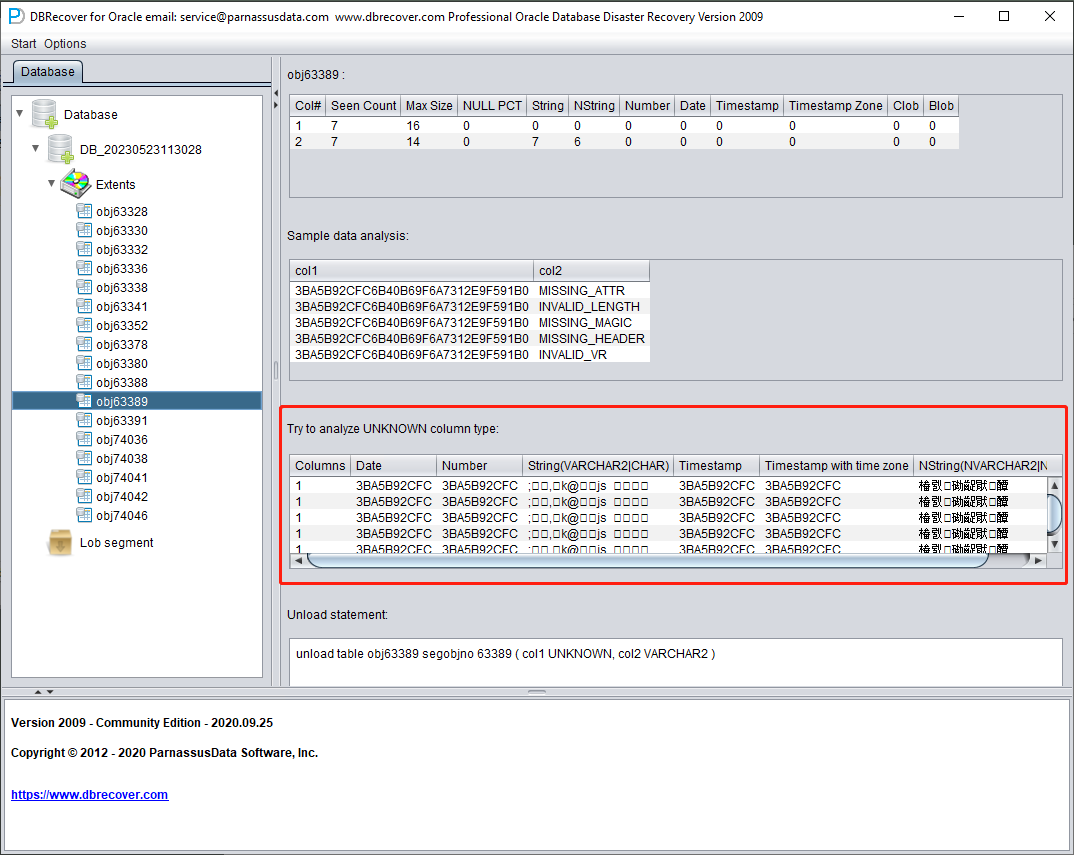
TRY TO ANALYZE UNKNOWN column type :
Cette partie concerne les champs dont la fonction d'analyse des types ne parvient pas à confirmer pleinement le type. Elle tente de les analyser avec différents types de champs et présente les résultats à l'utilisateur pour qu'il détermine le type réel.
Les champs dont le type ne peut pas être confirmé correspondent généralement aux situations suivantes :
- RAW ou LONG RAW
- Types de données non pris en charge, notamment : XDB.XDB$RAW_LIST_T, XMLTYPE, types définis par l'utilisateur, etc.
- Le bloc de données lui-même est gravement endommagé
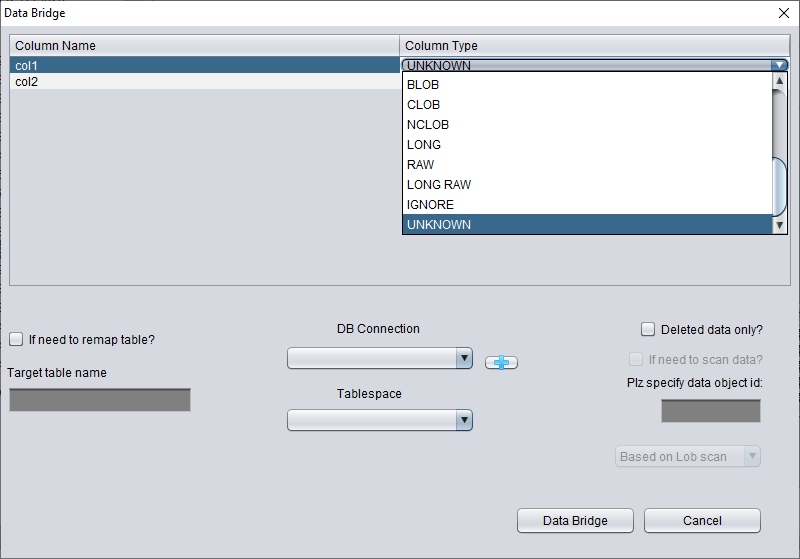
Dans ce « Non-Dictionary Mode », on peut également utiliser les modes conventionnel et Data Bridge. Par rapport au mode dictionnaire, la principale différence est qu'en mode non dictionnaire, l'utilisateur peut décider lui-même du type de chaque champ lors du Data Bridge. Comme le montre la figure ci-dessous, certains types de champs sont UNKNOWN, c'est-à-dire inconnus.
Si l'utilisateur connaît la structure de la table telle qu'elle a été conçue (cela peut aussi provenir de la documentation du développeur applicatif), il peut renseigner lui-même le bon Column Type afin de pouvoir transférer les données de la table vers la base cible.
Scénario de récupération 3 : Chiffrement par rançongiciel ou endommagement des fichiers de données
Les rançongiciels chiffrent une partie ou la totalité du contenu des fichiers de données ORACLE. Comme les fichiers de données ORACLE sont généralement volumineux, chiffrer l'intégralité d'un fichier peut prendre beaucoup de temps : certains rançongiciels choisissent donc de ne chiffrer que des zones contiguës ou aléatoires en début de fichier ORACLE.
Pour ce type d'altération par chiffrement partiel, nous pouvons tenter de récupérer les données qu'ils contiennent à l'aide de DBRECOVER.
L'en-tête du fichier de données étant endommagé, nous devons déterminer le numéro de tablespace (TS#) et le numéro de fichier relatif (RFILE#) de chaque fichier de données en examinant le contenu de SYSTEM01.DBF.
Voici la liste des fichiers de données :
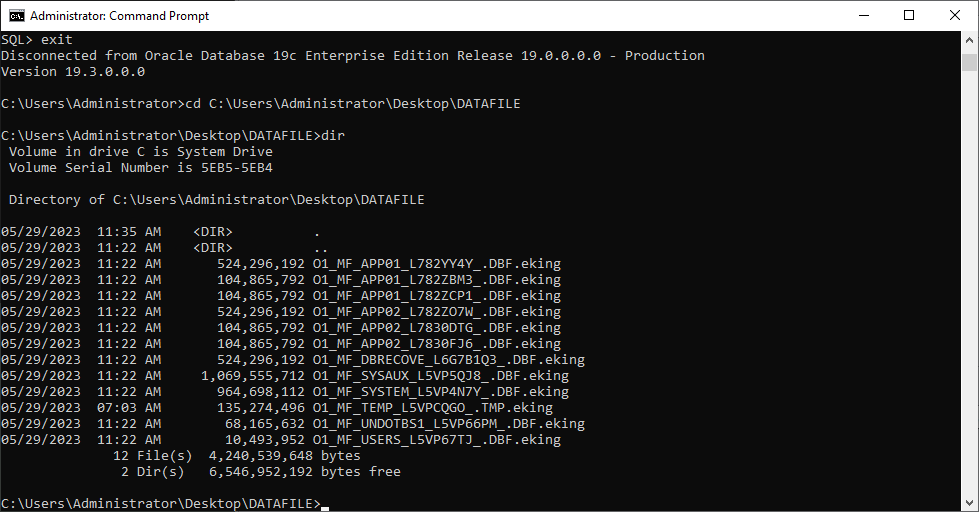
O1_MF_APP01_L782YY4Y_.DBF.eking
O1_MF_APP01_L782ZBM3_.DBF.eking
O1_MF_APP01_L782ZCP1_.DBF.eking
O1_MF_APP02_L782ZO7W_.DBF.eking
O1_MF_APP02_L7830DTG_.DBF.eking
O1_MF_APP02_L7830FJ6_.DBF.eking
O1_MF_DBRECOVE_L6G7B1Q3_.DBF.eking
O1_MF_SYSAUX_L5VP5QJ8_.DBF.eking
O1_MF_SYSTEM_L5VP4N7Y_.DBF.eking
O1_MF_TEMP_L5VPCQGO_.TMP.eking
O1_MF_UNDOTBS1_L5VP66PM_.DBF.eking
O1_MF_USERS_L5VP67TJ_.DBF.eking
L'exemple ci-dessus présente le suffixe de chiffrement eking.
Notez que TEMP, UNDOTBS1 et SYSAUX n'ont pas d'utilité pour notre travail de récupération : vous pouvez ignorer ces fichiers.
Nous lançons d'abord DBRECOVER en mode dictionnaire DICT-MODE.
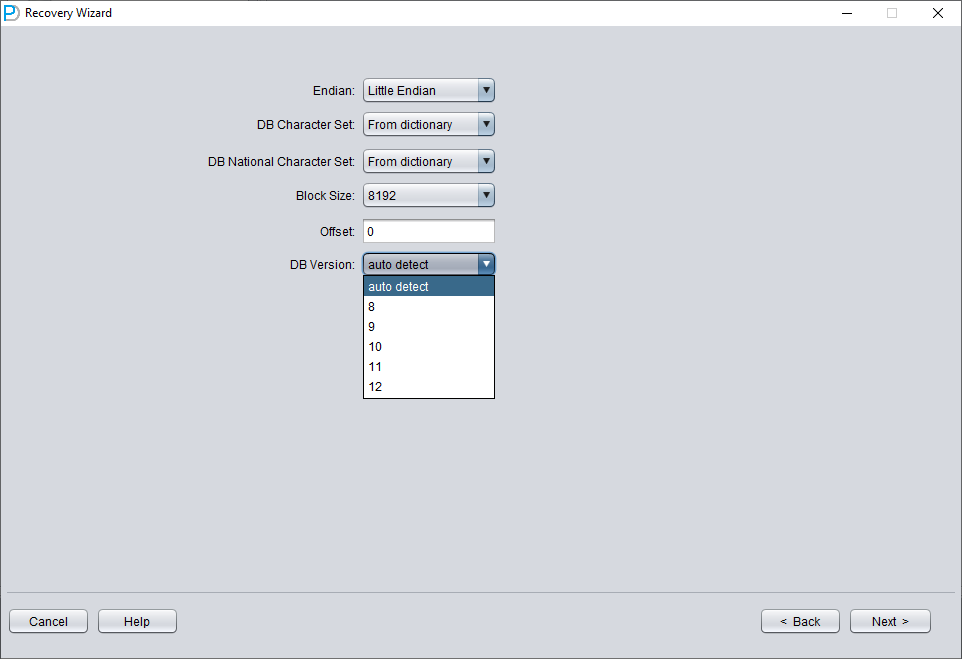
Choisissez la DB VERSION en fonction de votre situation. Pour les instances de version supérieure à 12c (18c, 19c, etc.), choisissez 12.
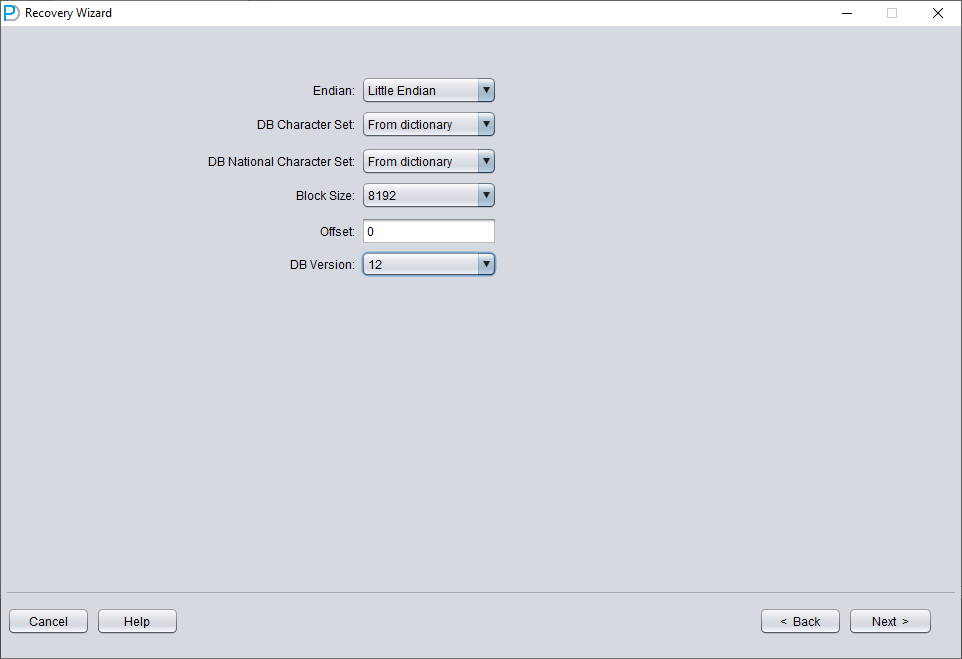
N'ajoutez que SYSTEM01.DBF et précisez TS# = 0, rFILE# = 1 (notez que ces valeurs sont fixes).
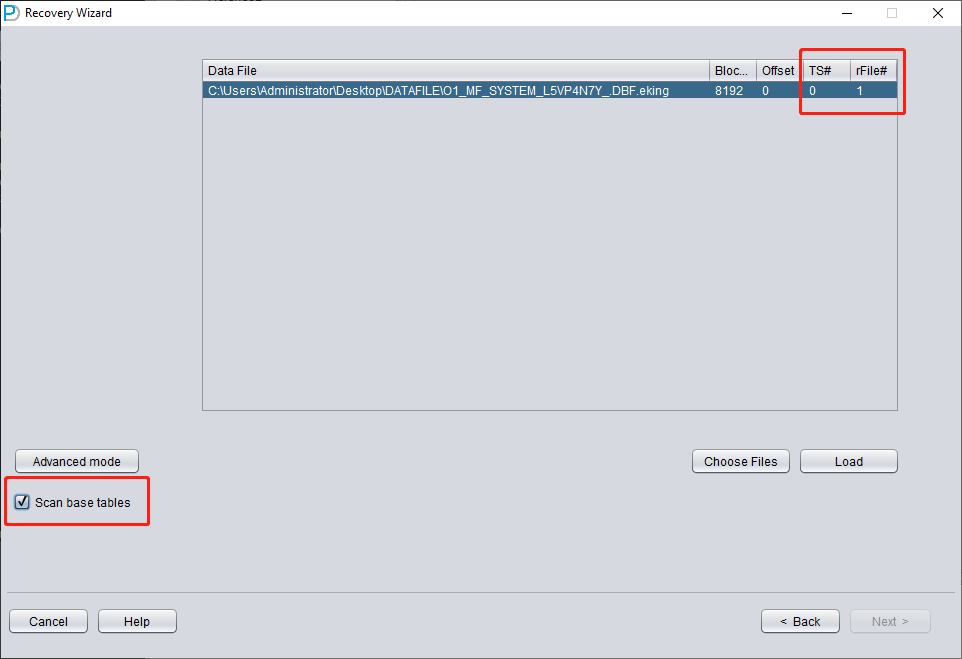
Cocher l'option « SCAN BASE TABLES » ci-dessus permet de mieux gérer les situations d'altération.
Après avoir cliqué sur le bouton LOAD, DBRECOVER analyse SYSTEM01.DBF dans son intégralité et y recherche les données des tables de base du dictionnaire de données.
Nous ouvrons le nœud de l'utilisateur SYS et recherchons les deux tables de base TS$ et FILE$ :
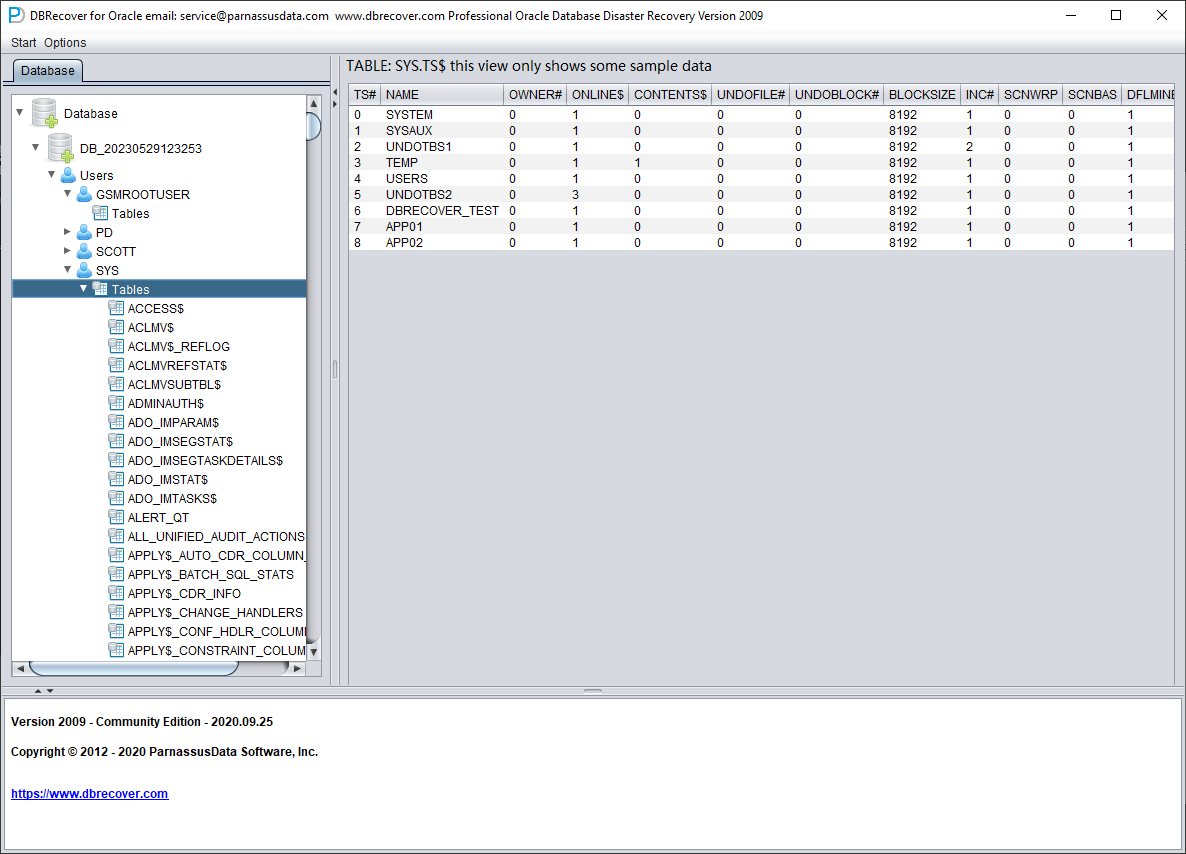
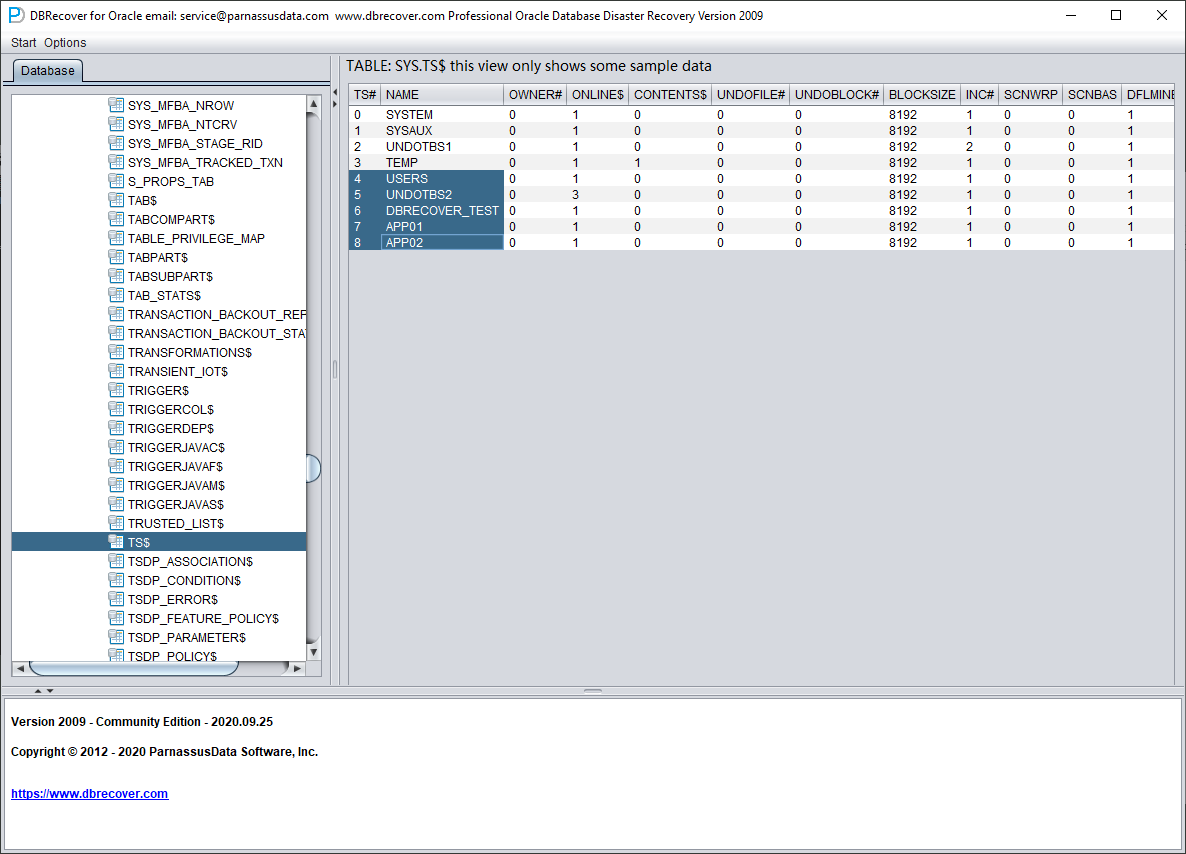
La table TS$ stocke les informations de tablespaces ; la colonne TS# est le numéro de tablespace et nous obtenons les informations suivantes :
| TS# | NOM |
| 0 | SYSTEM |
| 1 | SYSAUX |
| 2 | UNDOTBS1 |
| 3 | TEMP |
| 4 | USERS |
| 5 | UNDOTBS2 |
| 6 | DBRECOVER_TEST |
| 7 | APP01 |
| 8 | APP02 |
Autrement dit, le TS# du tablespace APP01 est 7 et le TS# du tablespace APP02 est 8.
La table FILE$ stocke les informations sur les fichiers de données :
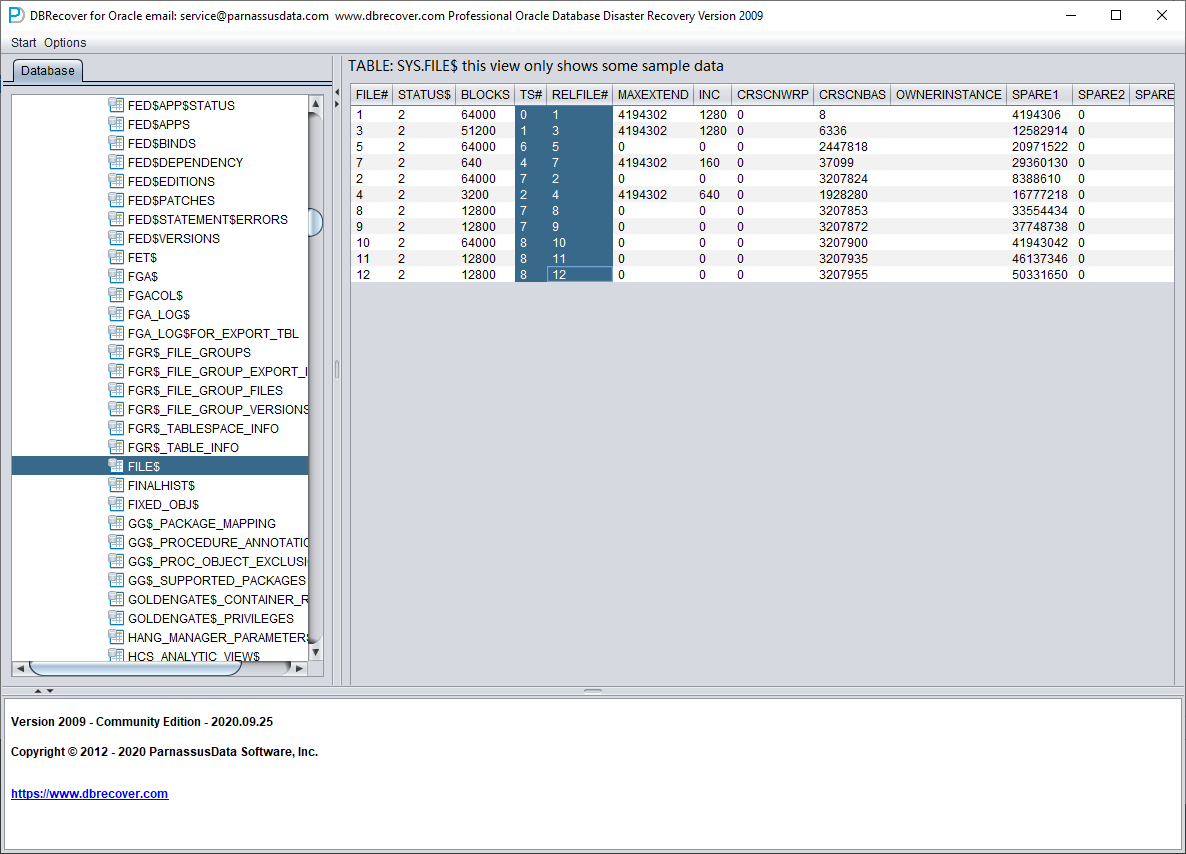
Ce qui nous intéresse, ce sont les colonnes TS# et RELFILE#.
| TS# | RELFILE# |
| 0 | 1 |
| 1 | 3 |
| 6 | 5 |
| 4 | 7 |
| 7 | 2 |
| 2 | 4 |
| 7 | 8 |
| 7 | 9 |
| 8 | 10 |
| 8 | 11 |
| 8 | 12 |
En faisant correspondre et en fusionnant les données des deux tables, on obtient :
| TS# | RELFILE# | Nom du tablespace |
| 0 | 1 | SYSTEM |
| 1 | 3 | SYSAUX |
| 6 | 5 | DBRECOVER_TEST |
| 4 | 7 | USERS |
| 7 | 2 | APP01 |
| 2 | 4 | UNDOTBS1 |
| 7 | 8 | APP01 |
| 7 | 9 | APP01 |
| 8 | 10 | APP02 |
| 8 | 11 | APP02 |
| 8 | 12 | APP02 |
Après avoir éliminé les SYSAUX et UNDOTBS1 inutiles ainsi que le tablespace SYSTEM connu, il ne reste que ce qui suit :
| TS# | RELFILE# | Nom du tablespace |
| 6 | 5 | DBRECOVER_TEST |
| 4 | 7 | USERS |
| 7 | 2 | APP01 |
| 7 | 8 | APP01 |
| 7 | 9 | APP01 |
| 8 | 10 | APP02 |
| 8 | 11 | APP02 |
| 8 | 12 | APP02 |
Liste correspondante des noms de fichiers de données :
O1_MF_APP01_L782YY4Y_.DBF.eking
O1_MF_APP01_L782ZBM3_.DBF.eking
O1_MF_APP01_L782ZCP1_.DBF.eking
O1_MF_APP02_L782ZO7W_.DBF.eking
O1_MF_APP02_L7830DTG_.DBF.eking
O1_MF_APP02_L7830FJ6_.DBF.eking
O1_MF_DBRECOVE_L6G7B1Q3_.DBF.eking
O1_MF_USERS_L5VP67TJ_.DBF.eking
Le rapprochement des deux tables vous fournit la correspondance fichier ↔ tablespace. Pour les bases utilisant Oracle Managed Files (OMF, contrôlé par db_create_file_dest), les fichiers de données d'un même tablespace peuvent être triés par nom et l'ordre de tri correspond à RELFILE#. Pour les bases dont les noms de fichiers sont gérés par l'utilisateur, les sites suivent généralement une convention de type APP01{XX} (par ex. APP0101, APP0102), et la même correspondance peut être déduite des noms.
Ci-dessus, nous avons obtenu un tableau d'informations complet par déduction :
| TS# | RFILE# | Nom du tablespace | NOM DU FICHIER |
| 6 | 5 | DBRECOVER_TEST | O1_MF_DBRECOVE_L6G7B1Q3_.DBF.eking |
| 4 | 7 | USERS | O1_MF_USERS_L5VP67TJ_.DBF.eking |
| 7 | 2 | APP01 | O1_MF_APP01_L782YY4Y_.DBF.eking |
| 7 | 8 | APP01 | O1_MF_APP01_L782ZBM3_.DBF.eking |
| 7 | 9 | APP01 | O1_MF_APP01_L782ZCP1_.DBF.eking |
| 8 | 10 | APP02 | O1_MF_APP02_L782ZO7W_.DBF.eking |
| 8 | 11 | APP02 | O1_MF_APP02_L7830DTG_.DBF.eking |
| 8 | 12 | APP02 | O1_MF_APP02_L7830FJ6_.DBF.eking |
Rouvrez DBRECOVER et passez en mode dictionnaire :
Vous devez toujours sélectionner la version de la base (DB VERSION).
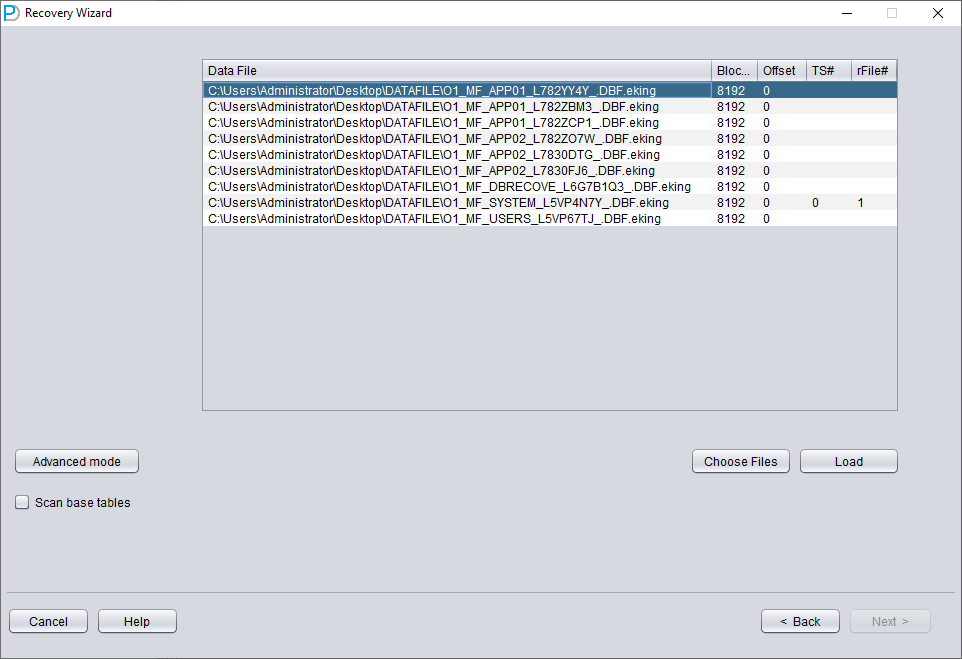
Ajoutez tous les fichiers de données nécessaires (tous les fichiers susceptibles de contenir des données utilisateur ; UNDOTBS1, TEMP et SYSAUX n'ont pas à être ajoutés) et veillez à ne pas omettre SYSTEM01.DBF (il doit obligatoirement être ajouté).
Renseignez les informations TS# et RFILE# selon le tableau établi précédemment :
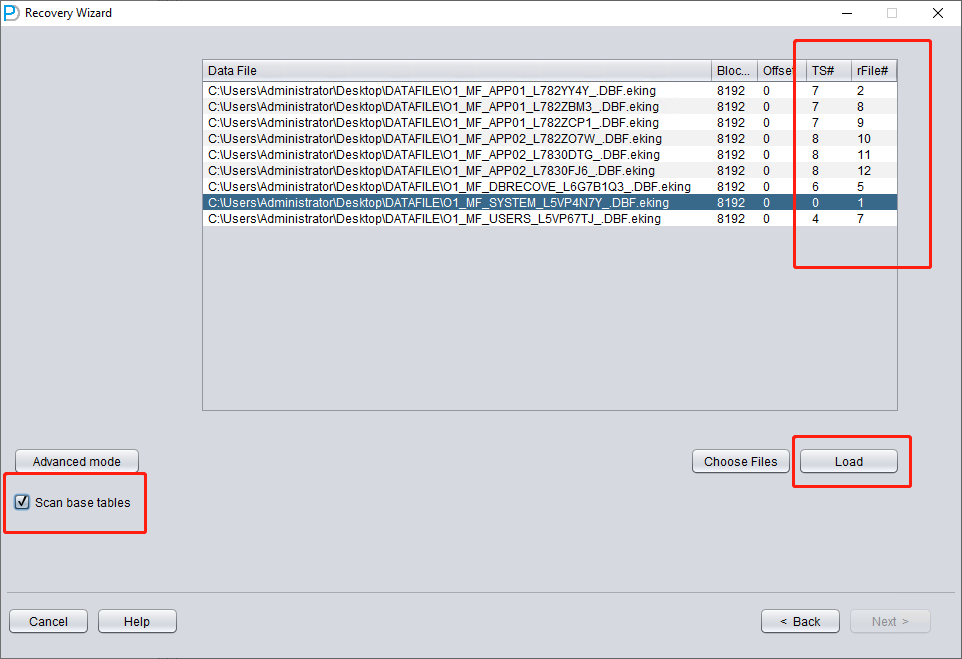
Si les informations requises sont correctement saisies et si l'altération par chiffrement n'est pas trop grave, vous pourrez lire directement les données :
Les variantes de rançongiciels se comportent différemment ; une récupération réelle peut donc nécessiter des étapes supplémentaires non décrites ici. Pour obtenir de l'aide, écrivez à liu.maclean@gmail.com.
Scénario de récupération 4 : Récupération de lignes supprimées par une opération DELETE FROM TABLE
Un développeur de l'entreprise D a exécuté un script destiné à supprimer des données dans l'environnement de test, mais s'est connecté par erreur à l'environnement de production (PROD DATABASE), supprimant ainsi toutes les données d'une table.
Dans ce scénario, nous pouvons utiliser DBRECOVER pour récupérer les lignes supprimées.
Les utilisateurs doivent toutefois effectuer au préalable les opérations suivantes afin d'éviter au maximum l'écrasement des données :
- Passez le tablespace contenant la table en lecture seule (READ ONLY). La commande est : ALTER TABLESPACE {TABLESPACE_NAME} READ ONLY
- Arrêtez l'instance de la base : SHUTDOWN IMMEDIATE
Les utilisateurs peuvent choisir l'une ou l'autre des deux solutions ci-dessus.
Reproduction du scénario :
SQL> select count(*) from pd.emp;
COUNT(*)
---------
114688
SQL> delete from pd.emp;
114688 rows deleted.
SQL> commit;
Commit complete.
SQL> alter system checkpoint;
System altered.
SQL> select count(*) from pd.emp;
COUNT(*)
---------
0
Avant de commencer la récupération, nous passons d'abord le tablespace en lecture seule pour protéger l'environnement de récupération :
SQL> select tablespace_name from dba_segments where owner='PD' and segment_name='EMP';
TABLESPACE_NAME
-----------------------------
DBRECOVER_TEST
SQL> alter tablespace DBRECOVER_TEST read only;
Tablespace altered.
Lancez DBRECOVER, choisissez le mode dictionnaire et ajoutez tous les fichiers de données disponibles :
Les données de la table d'exemple apparaissent comme vides. Faites un clic droit sur la table et sélectionnez Unload Deleted Data.
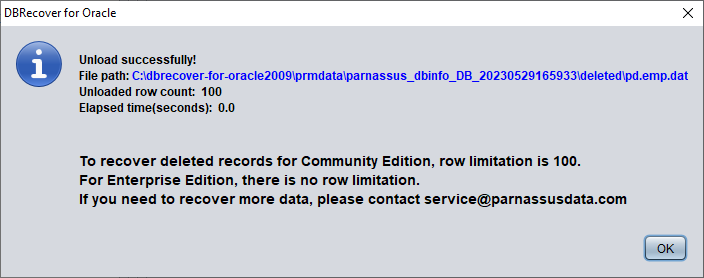
Sans licence entreprise valide, la fonction UNLOAD DELETED DATA est limitée à 100 lignes par table.
Les données récupérées sont stockées au chemin indiqué dans la fenêtre contextuelle :
Les utilisateurs doivent vérifier eux-mêmes les résultats de la récupération et utiliser des outils tels que SQLLDR ou SQLDEVELOPER pour réinjecter les données texte dans la base.
Scénario de récupération 5 : Récupération suite à une opération TRUNCATE TABLE accidentelle
Le personnel d'exploitation métier de l'entreprise D a confondu la base de production avec celle de l'environnement de test et a tronqué par erreur l'ensemble des données d'une table. Le DBA a tenté une restauration mais a constaté que la sauvegarde la plus récente était inutilisable, rendant impossible la restauration des enregistrements de cette table à partir des données de sauvegarde. À ce stade, le DBA a décidé d'utiliser DBRECOVER pour récupérer les données tronquées.
Dans cet environnement, tous les fichiers de la base sont disponibles et sains. L'utilisateur doit simplement charger en mode dictionnaire les fichiers de données du tablespace SYSTEM et de la table tronquée. Par exemple :
SQL> select count(*) From pd.salgrade;
COUNT(*)
---------
655360
SQL> select tablespace_name from dba_segments where owner='PD' and segment_name='SALGRADE';
TABLESPACE_NAME
-----------------------------
APP01
SQL> truncate table pd.salgrade;
Table truncated.
SQL> alter system checkpoint;
System altered.
SQL> select count(*) from pd.salgrade;
COUNT(*)
---------
0
Dans ce scénario TRUNCATE, le stockage ASM n'est pas utilisé : il suffit de sélectionner le « Dictionary Mode » :
Dans la plupart des cas, aucun paramètre n'a besoin d'être modifié :
Ajoutez tous les fichiers de données disponibles :
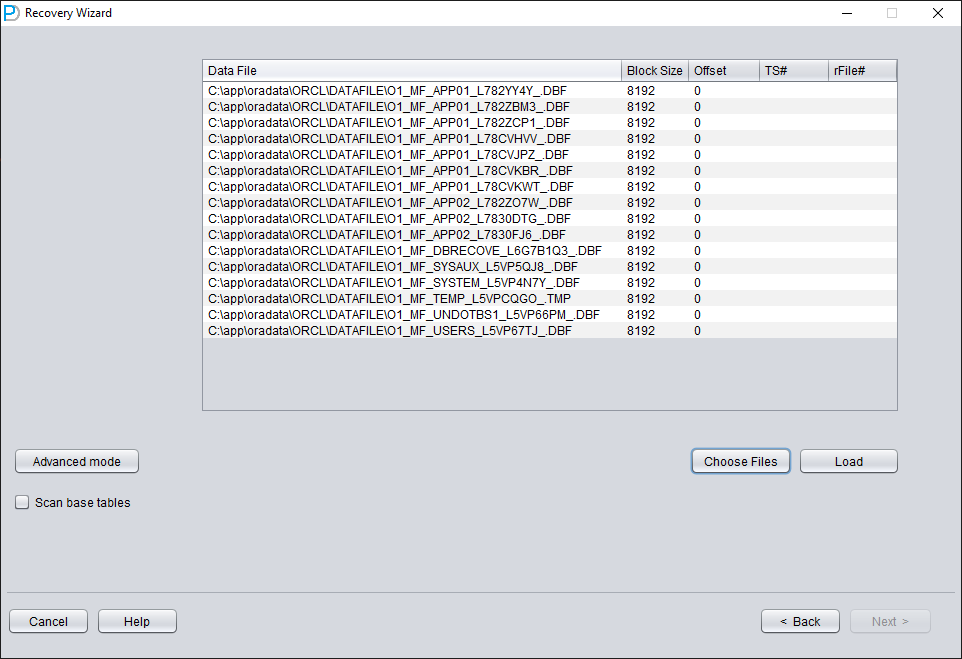
Ouvrez USERS pour voir plusieurs noms d'utilisateurs. Si vous devez récupérer une table du SCHEMA PD, ouvrez PD et double-cliquez sur le nom de la table :
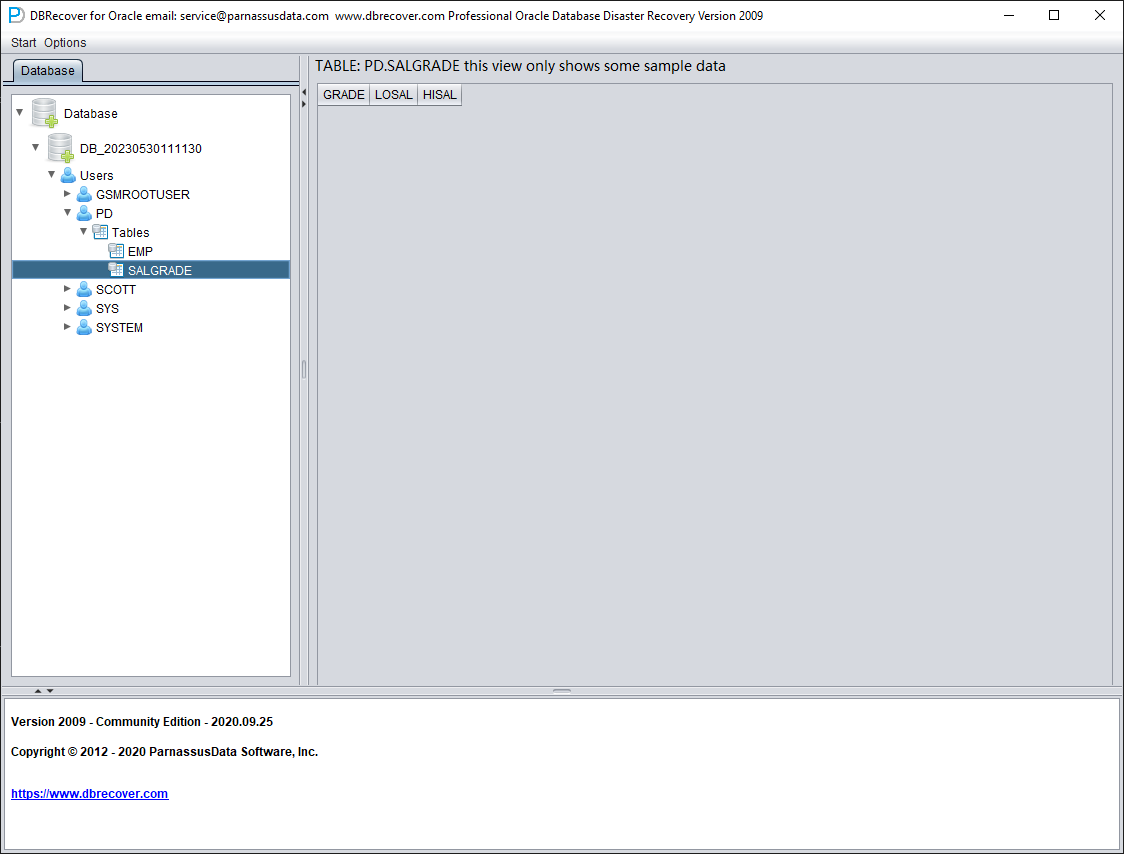
La table ayant été tronquée, le double-clic n'affiche aucune donnée. À ce stade, faites un clic droit sur la table et sélectionnez « Unload truncated data » :
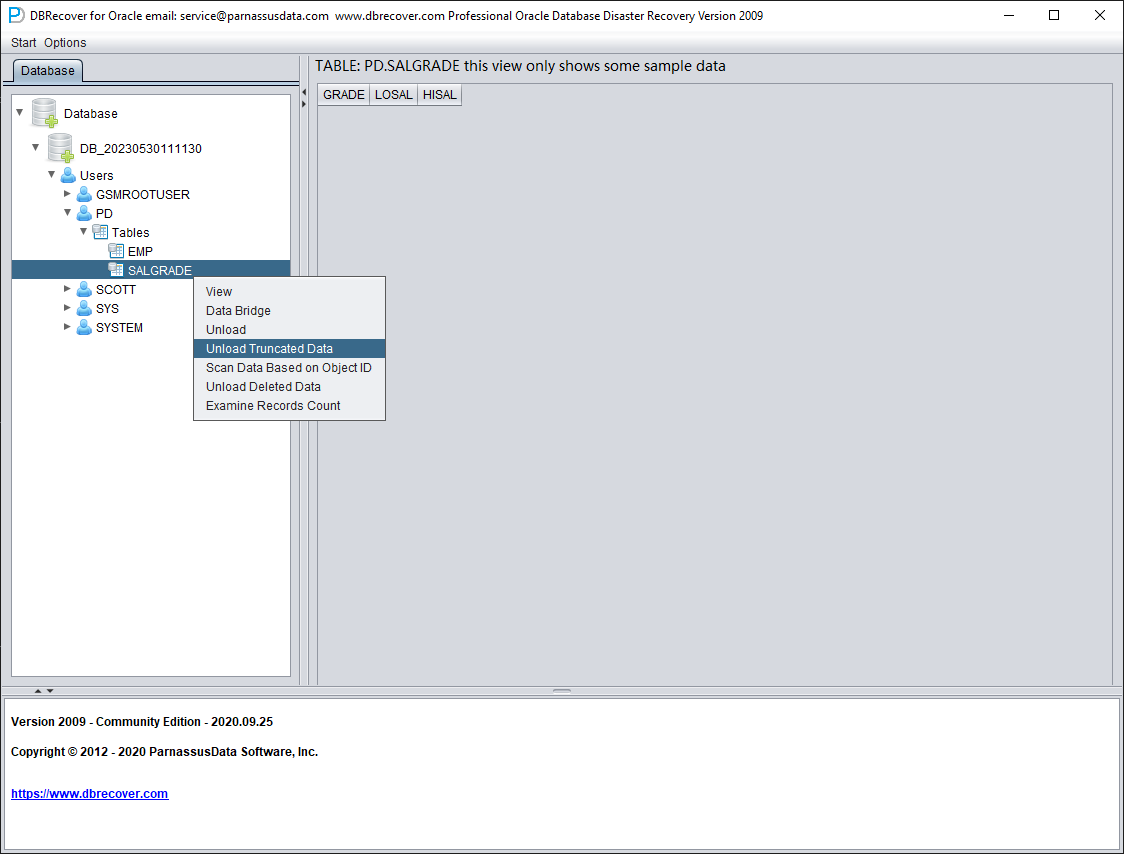
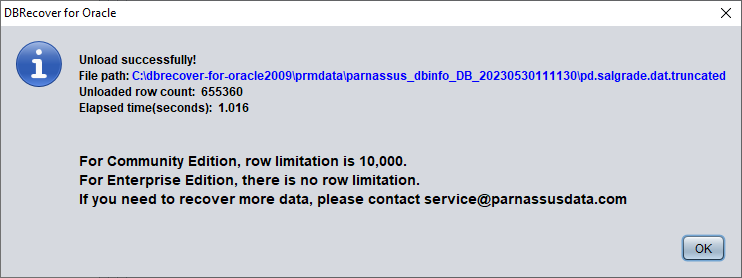
DBRECOVER va tenter de scanner le tablespace où réside la table et d'extraire les données tronquées. Comme le montre la figure ci-dessus, l'intégralité des 655 360 enregistrements est extraite de la table tronquée et stockée au chemin indiqué.
L'utilisateur peut consulter le fichier DAT pour confirmer le résultat de la récupération.
La clé de la récupération de données tronquées consiste à confirmer le DATA_OBJECT_ID antérieur à la troncature. Dans ce cas :
SQL> select object_id ,data_object_id from dba_objects where owner='PD' and object_name='SALGRADE';
OBJECT_ID DATA_OBJECT_ID
--------- --------------
76112 76113
Avant le TRUNCATE, l'OBJECT_ID et le DATA_OBJECT_ID de la table valaient tous deux 76112. Le TRUNCATE a fait passer DATA_OBJECT_ID à 76113 tandis qu'OBJECT_ID est resté inchangé.
Le DATA_OBJECT_ID d'origine est donc ici 76112. Mais si une table a été tronquée plusieurs fois et que vous devez récupérer des données antérieures à un TRUNCATE plus ancien, vous ne pouvez pas simplement déduire le DATA_OBJECT_ID d'origine à partir de l'OBJECT_ID courant.
Vous pouvez recourir à des techniques telles que les requêtes flashback, l'interrogation du dictionnaire et le log mining pour déterminer le DATA_OBJECT_ID ; voici un exemple de requête flashback :
SQL> select user# from sys.user$ where name='PD';
USER#
---------
106
SQL> select obj#,dataobj# from sys.obj$ as of timestamp systimestamp -1/24 where name='SALGRADE' and owner#=106;
OBJ# DATAOBJ#
--------- ----------
76112 76112
Le DATAOBJ# d'origine, c'est-à-dire le DATA_OBJECT_ID, est obtenu à l'aide de la requête flashback ci-dessus.
Utilisez ensuite la fonction Data Bridge pour insérer les données récupérées dans la base cible.
Point critique lors d'un Data Bridge vers la base source : si Data Bridge écrit dans la même base que celle dont provient la table tronquée, le tablespace de destination ne doit pas être celui qui contient les données tronquées, et la table de destination ne doit pas être la table source. Écrire dans le tablespace source peut écraser les extents résiduels que DBRECOVER tente de lire et rendre les données irrécupérables. (Si vous transférez vers une base totalement différente, ce point ne s'applique pas.)
Nous commençons donc ici par créer un nouveau tablespace destiné à stocker la table récupérée :
SQL> create tablespace pd_recover_data datafile size 600M;
Tablespace created.
Créez les informations de connexion nécessaires ; notez que l'utilisateur de la base doit disposer des permissions requises (il est recommandé d'octroyer le rôle DBA).
Une fois le test réussi, cliquez sur SAVE pour enregistrer.
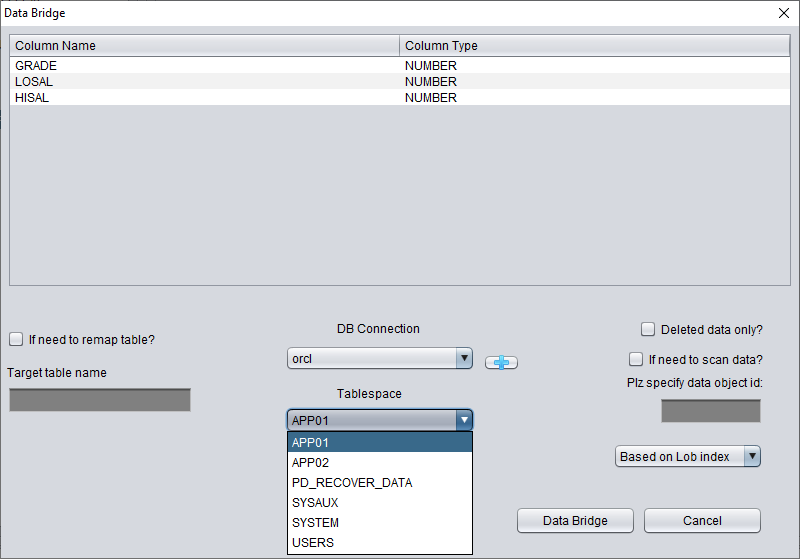
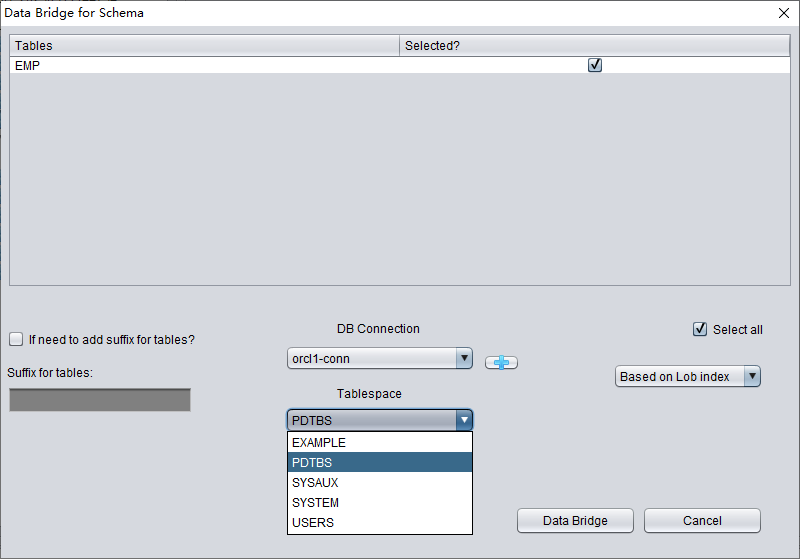
Ci-dessus, sélectionnez le tablespace destiné à stocker la table récupérée après TRUNCATE.
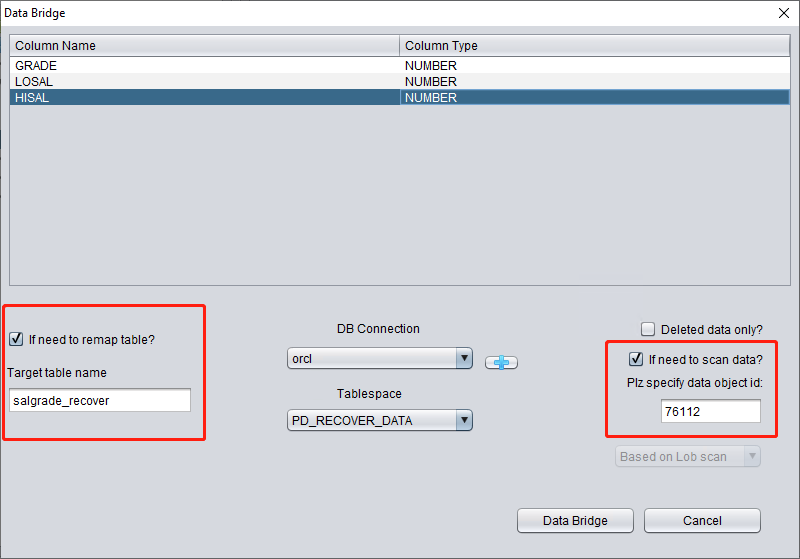
Ici, nous devons cocher « if need to scan data » et renseigner le DATA_OBJECT_ID d'origine obtenu précédemment. Ainsi, DBRECOVER ne scannera spécifiquement que les données correspondant à cet ID.
Dans le même temps, nous devons cocher « if need to remap table » et saisir un nouveau nom de table. L'objectif est de permettre l'insertion des données dans la nouvelle table (dans le nouveau tablespace) tout en excluant tout risque d'écrasement.
Remarque :
- Lorsque le nom de table correspondant existe déjà dans l'instance cible, DBRECOVER ne reconstruit pas la table mais insère les données de récupération nécessaires dans la table existante. Puisque la table a déjà été créée, le tablespace spécifié sera ignoré.
- Lorsque le nom de table correspondant n'existe pas dans le SCHEMA cible, DBRECOVER tentera de créer une table dans le tablespace spécifié et d'y insérer les données de récupération.
Après avoir effectué les étapes ci-dessus, cliquez sur le bouton Data Bridge.
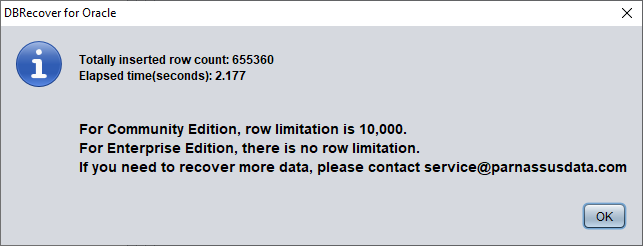
Vérifiez le nombre de lignes récupérées :
SQL> select count(*) from pd.salgrade_recover;
COUNT(*)
---------
655360
Le principe de base de la récupération après Truncate est le suivant : lorsqu'un Truncate se produit, ORACLE ne met à jour que le Data Object ID de la table dans le dictionnaire de données et dans le Segment Header, sans modifier la partie de données proprement dite des blocs. Comme le DATA_OBJECT_ID du dictionnaire de données et du segment header ne correspond plus à celui présent dans les blocs de données ultérieurs, le processus serveur ORACLE ne lira pas, lors d'un parcours complet de la table, les données TRUNCATED qui n'ont pas encore été écrasées. DBRECOVER peut donc récupérer ces données via les Data Extents (zones de données sur disque) qui n'ont pas été modifiés ou écrasés.
Scénario de récupération 6 : Récupération suite à un DROP TABLE accidentel
Les développeurs applicatifs de l'entreprise D ont droppé une table applicative centrale du système sans aucune sauvegarde. Dans ce cas, DBRECOVER peut être utilisé pour récupérer la majeure partie des données de la table supprimée. Depuis 10g, la fonction de corbeille (recycle bin) est disponible : on peut d'abord interroger la vue DBA_RECYCLEBIN pour déterminer si la table supprimée s'y trouve. Si oui, privilégiez un flashback avant le DROP via la corbeille. Si la table n'est pas dans la corbeille, utilisez immédiatement DBRECOVER pour la récupérer.
Comme pour la récupération après TRUNCATE, la récupération d'une table droppée nécessite de déterminer le DATA_OBJECT_ID d'origine.
La procédure synthétique de récupération est la suivante :
- Commencez par passer en lecture seule le tablespace contenant la table droppée avec
ALTER TABLESPACE {TABLESPACE_NAME} READ ONLY, ou copiez immédiatement tous les fichiers de données du tablespace.
- Identifiez le DATA_OBJECT_ID de la table droppée en interrogeant le dictionnaire de données ou LOGMINER.
- Démarrez DBRECOVER en mode NON-DICT (non dictionnaire), ajoutez tous les fichiers de données du tablespace où se trouvait la table droppée, puis lancez SCAN DATABASE + SCAN TABLE from Extent MAP.
- Repérez la table correspondante dans l'arborescence d'objets dépliée à l'aide du DATA_OBJECT_ID, puis réinsérez-la dans la base source en mode Data Bridge.
Vous pouvez retrouver un DATA_OBJECT_ID approximatif à l'aide de LogMiner. Voici un script de base :
EXECUTE DBMS_LOGMNR.ADD_LOGFILE( LOGFILENAME => '/oracle/logs/log1.f', OPTIONS => DBMS_LOGMNR.NEW);
EXECUTE DBMS_LOGMNR.ADD_LOGFILE( LOGFILENAME => '/oracle/logs/log2.f', OPTIONS => DBMS_LOGMNR.ADDFILE);
Execute DBMS_LOGMNR.START_LOGMNR(DBMS_LOGMNR.DICT_FROM_ONLINE_CATALOG+DBMS_LOGMNR.COMMITTED_DATA_ONLY);
SELECT * FROM V$LOGMNR_CONTENTS ;
EXECUTE DBMS_LOGMNR.END_LOGMNR;
Vous pouvez aussi tenter d'extraire le DATA_OBJECT_ID en explorant les données AWR :
-- Query 1: compare DBA_HIST_SQL_PLAN / GV$SQL_PLAN against OBJ$
Select * from
(select object_name,object# from DBA_HIST_SQL_PLAN
UNION select object_name,object# from GV$SQL_PLAN) V1 where V1.OBJECT# IS
NOT NULL minus select name,obj# from sys.obj$;
-- Query 2: compare WRH$_SEG_STAT_OBJ against OBJ$
select obj#,dataobj#, object_name from WRH$_SEG_STAT_OBJ where object_name
not in (select name from sys.obJ$) order by object_name desc;
-- Query 3: compare DBA_HIST_ACTIVE_SESS_HISTORY against OBJ$
SELECT tab1.SQL_ID,
current_obj#,
tab2.sql_text
FROM DBA_HIST_ACTIVE_SESS_HISTORY tab1,
dba_hist_sqltext tab2
WHERE tab1.current_obj# NOT IN
(SELECT obj# FROM sys.obj$
)
AND current_obj#!=-1
AND tab1.sql_id =tab2.sql_id(+);
// Les trois requêtes ci-dessus comparent les données AWR à la table de base du dictionnaire OBJ$ pour retrouver la table droppée.
Mettons-le en pratique :
SQL> create table dropit as select * from dba_objects;
Table created.
SQL> select count(*) from pd.dropit;
COUNT(*)
---------
73095
SQL> select tablespace_name from dba_segments where owner='PD' and segment_name='DROPIT';
TABLESPACE_NAME
-----------------------------
USERS
SQL> select object_id ,data_object_id from dba_objects where owner='PD' and object_name='DROPIT';
OBJECT_ID DATA_OBJECT_ID
--------- --------------
76116 76116
SQL> drop table dropit;
Table dropped.
SQL> alter system checkpoint;
System altered.
Nous démarrons DBRECOVER en mode dictionnaire (DICTIONARY-MODE) ; il suffit ici d'ajouter SYSTEM01.DBF et la table du tablespace USERS :
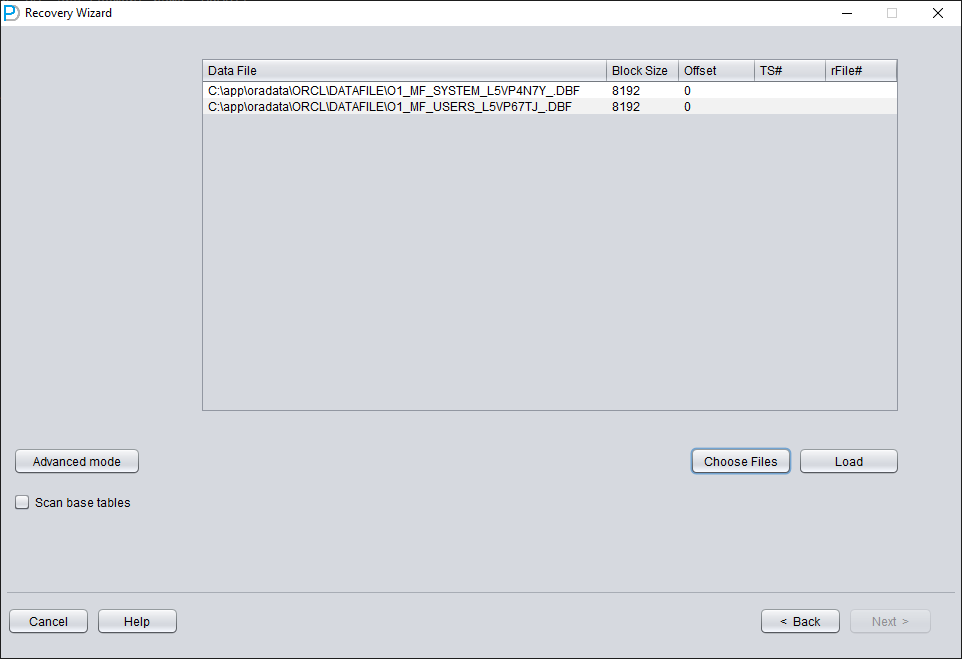
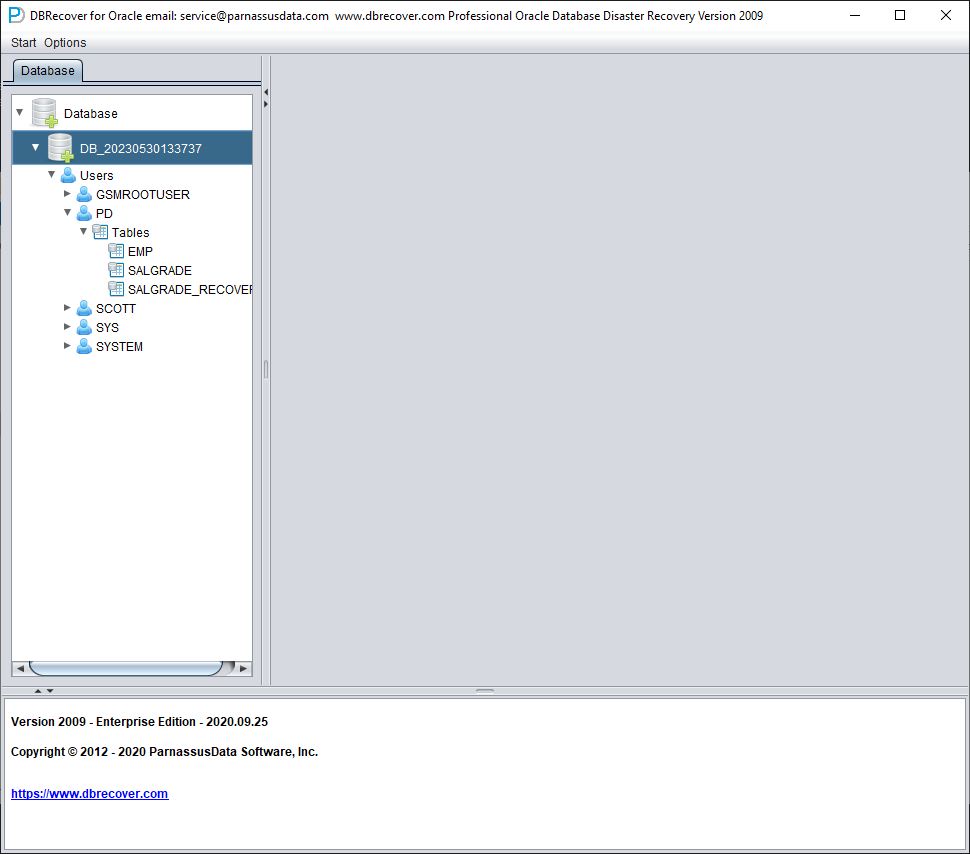
Une fois le chargement terminé, on constate qu'aucune table à récupérer n'apparaît sous le SCHEMA PD, ce qui est normal.
Sélectionnez le nœud de la base, faites un clic droit puis SCAN Data
Un nœud EXTENTS apparaît alors ; recherchez le nœud OBJ76116 :
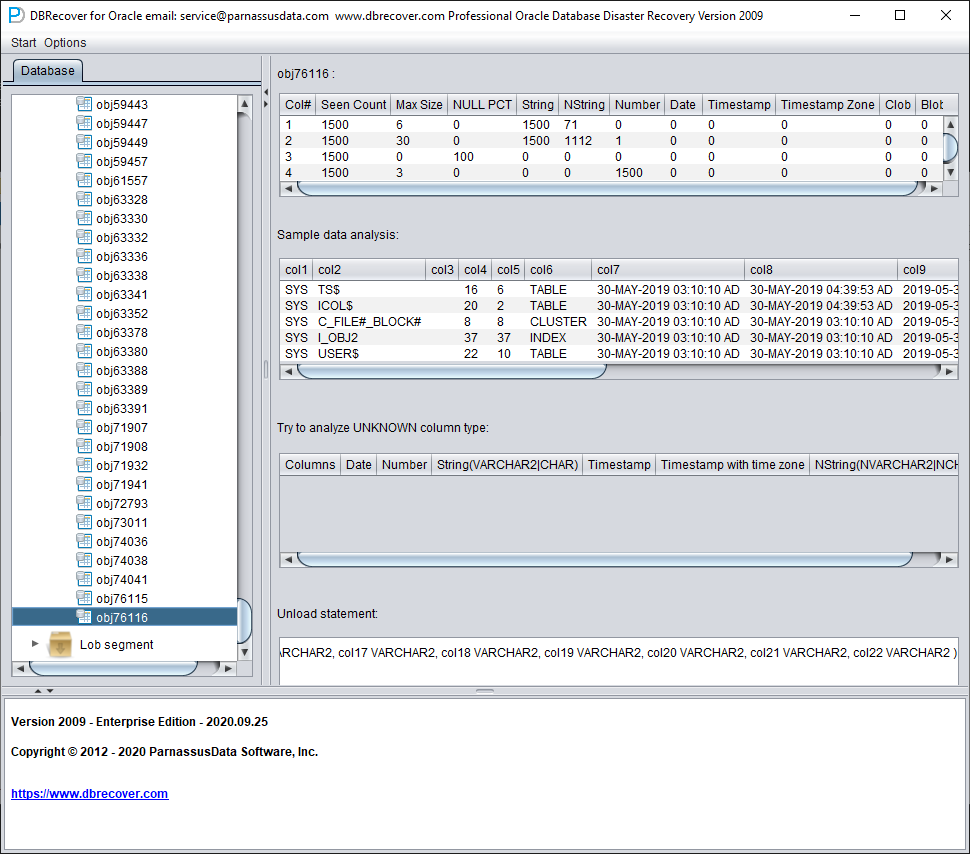
Ensuite, nous pouvons utiliser la fonction Data Bridge pour la réinsérer dans la base source.
Scénario de récupération 7 : Récupération suite à un DROP TABLESPACE accidentel
Chez l'entreprise D, un employé devait supprimer un tablespace inutile au moyen d'une opération DROP TABLESPACE INCLUDING CONTENTS. Toutefois, après le DROP TABLESPACE, le service développement a signalé que ce tablespace contenait en réalité des données importantes appartenant à un SCHEMA. Or, le tablespace a été dropé et il n'existe pas de sauvegardes.
Dans ce cas, nous pouvons utiliser le mode non dictionnaire de DBRECOVER pour extraire les données de tous les fichiers de données correspondant au tablespace dropé. Cette méthode permet de récupérer la majeure partie des données. Toutefois, comme nous sommes en mode non dictionnaire, les tables récupérées doivent être appariées une à une avec les tables applicatives. Habituellement, le personnel de développement et de maintenance applicative doit intervenir pour identifier manuellement à quelle table appartiennent quelles données. Comme l'opération DROP TABLESPACE modifie le dictionnaire de données et supprime de OBJ$ les objets situés sur le tablespace concerné, nous ne pouvons pas obtenir depuis OBJ$ la correspondance entre DATA_OBJECT_ID et OBJECT_NAME. Nous pouvons alors recourir à la méthode présentée dans le scénario DROP TABLE pour récupérer autant que possible la correspondance entre DATA_OBJECT_ID et OBJECT_NAME.
Le déroulement général est le suivant :
Si les fichiers de données ont également été physiquement supprimés lors de l'opération DROP TABLESPACE, il faut d'abord les restaurer. Vous pouvez essayer un logiciel de récupération au niveau du système de fichiers, ou utiliser le logiciel PRMSCAN pour scanner et reconstituer les fichiers de données au niveau des blocs Oracle.
PRMSCAN est un outil de scan et de fusion de fragments de blocs de données Oracle, adapté aux scénarios suivants :
- Suppression manuelle accidentelle de fichiers de données sur le système de fichiers (n'importe quel système : NTFS, FAT, EXT, UFS, JFS, etc.) ou sur ASM.
- Le système de fichiers est endommagé et le fichier de données est tronqué à zéro octet.
- Le système de fichiers est endommagé, ce qui empêche son MOUNT.
- Les métadonnées du stockage ASM sont endommagées, empêchant le mount et le chargement du diskgroup.
- La LV ou la PV du système de fichiers ou d'ASM est physiquement endommagée ou perdue.
- Dans les scénarios ci-dessus, prmscan peut scanner directement les blocs Oracle résiduels qui n'ont pas été écrasés dans les PV et LV du système de fichiers ou d'ASM, afin de fusionner et de reconstituer ces blocs Oracle dans un objectif de récupération des données.
PRMSCAN est développé en langage JAVA et peut être utilisé sur tous les systèmes d'exploitation prenant en charge JDK 1.6 et versions ultérieures, notamment Windows, Linux, Solaris, AIX et HP-UX.
Ce produit n'est actuellement pas disponible à la vente ; vous pouvez nous contacter pour bénéficier de prestations de récupération.
Dans l'exemple ci-dessous, /dev/sdb1 est une partition ext4 qui contient un ensemble de fichiers de données Oracle. Le système de fichiers ext4 est endommagé et SDB1 ne peut plus être monté, ce qui rend également la base Oracle inutilisable.
Nous utilisons ici la fonction de scan et de fusion des blocs Oracle de prmscan pour reconstituer directement les fichiers de données depuis le système de fichiers endommagé.
Scannez l'intégralité du disque
[oracle@dbdao01 ~]$ java -jar PRMScan.jar –scan /dev/sdb1 –guess 8k
L'option --scan indique que l'on scanne le périphérique /dev/sdb1 et que la taille de bloc Oracle est fixée à 8k.
[oracle@dbdao01 ~]$ java -jar PRMScan.jar --outputsh ./8kfull.txtL'option --outputsh génère un fichier SHELL capable de fusionner les informations scannées, ici 8kfull.txt.
[oracle@dbdao01 ~]$ sh 8kfull.txtL'exécution de 8kfull.txt génère dans le répertoire courant tous les fichiers de données à fusionner.
Par exemple :
[oracle@dbdao01 ~]$ ls -ll PD*
rw-r–r– 1 oracle oinstall 295428096 Jul 28 00:37 PD_DBF1.dbf
rw-r–r– 1 oracle oinstall 83427328 Jul 28 00:37 PD_DBF2.dbf
rw-r–r– 1 oracle oinstall 220266496 Jul 28 00:37 PD_DBF3.dbf
rw-r–r– 1 oracle oinstall 1324482560 Jul 28 00:38 PD_DBF4.dbf
Si les fichiers de données n'ont pas été physiquement supprimés, ils peuvent être ajoutés directement dans DBRECOVER et leurs données scannées en NON-DICTIONARY MODE.
Les étapes ultérieures peuvent reprendre la procédure DROP TABLE décrite précédemment, à la différence près que la récupération après DROP TABLESPACE concerne de nombreuses tables.